 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time 3D Vision-Language Embedding Mapping
Aug 08, 2025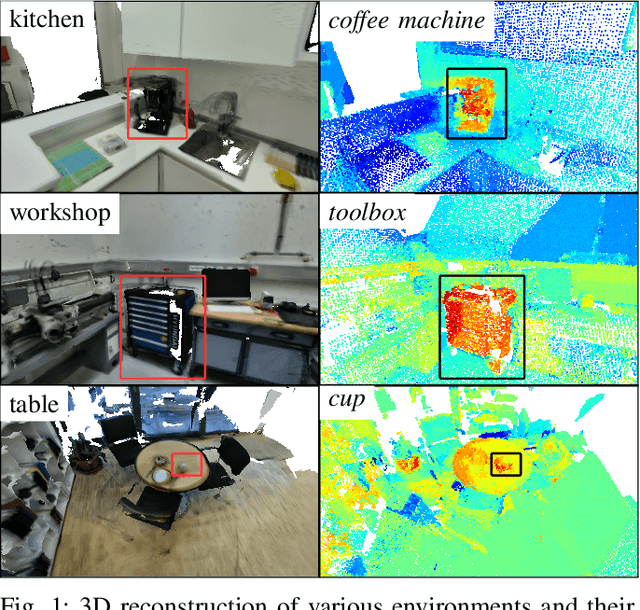
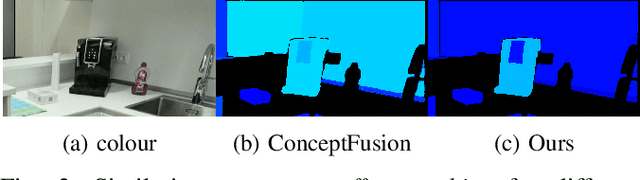


A metric-accurate semantic 3D representation is essential for many robotic tasks. This work proposes a simple, yet powerful, way to integrate the 2D embeddings of a Vision-Language Model in a metric-accurate 3D representation at real-time. We combine a local embedding masking strategy, for a more distinct embedding distribution, with a confidence-weighted 3D integration for more reliable 3D embeddings. The resulting metric-accurate embedding representation is task-agnostic and can represent semantic concepts on a global multi-room, as well as on a local object-level. This enables a variety of interactive robotic applications that require the localisation of objects-of-interest via natural language. We evaluate our approach on a variety of real-world sequences and demonstrate that these strategies achieve a more accurate object-of-interest localisation while improving the runtime performance in order to meet our real-time constraints. We further demonstrate the versatility of our approach in a variety of interactive handheld, mobile robotics and manipulation tasks, requiring only raw image data.
EnvoDat: A Large-Scale Multisensory Dataset for Robotic Spatial Awareness and Semantic Reasoning in Heterogeneous Environments
Oct 29, 2024
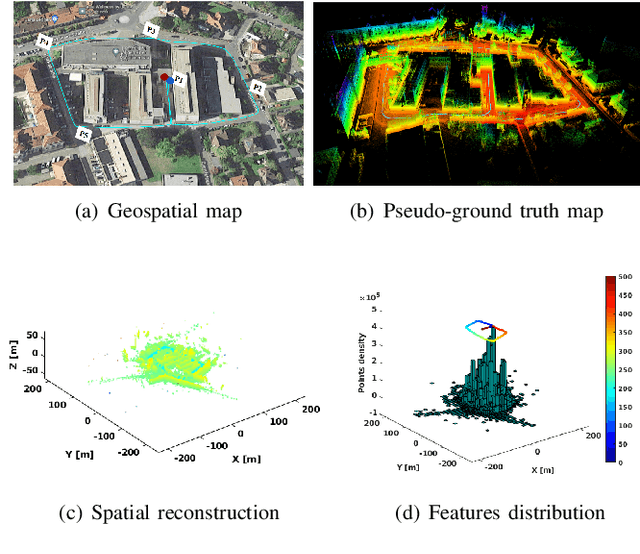
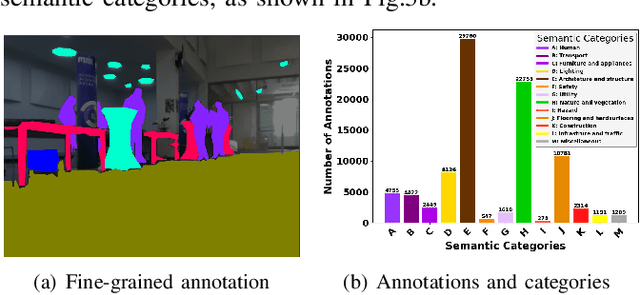
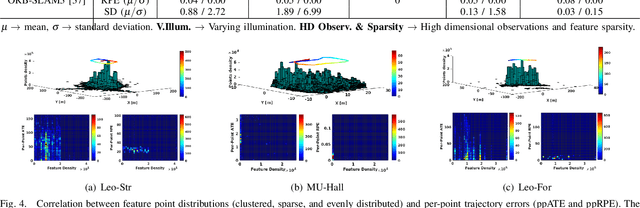
To ensure the efficiency of robot autonomy under diverse real-world conditions, a high-quality heterogeneous dataset is essential to benchmark the operating algorithms' performance and robustness. Current benchmarks predominantly focus on urban terrains, specifically for on-road autonomous driving, leaving multi-degraded, densely vegetated, dynamic and feature-sparse environments, such as underground tunnels, natural fields, and modern indoor spaces underrepresented. To fill this gap, we introduce EnvoDat, a large-scale, multi-modal dataset collected in diverse environments and conditions, including high illumination, fog, rain, and zero visibility at different times of the day. Overall, EnvoDat contains 26 sequences from 13 scenes, 10 sensing modalities, over 1.9TB of data, and over 89K fine-grained polygon-based annotations for more than 82 object and terrain classes. We post-processed EnvoDat in different formats that support benchmarking SLAM and supervised learning algorithms, and fine-tuning multimodal vision models. With EnvoDat, we contribute to environment-resilient robotic autonomy in areas where the conditions are extremely challenging. The datasets and other relevant resources can be accessed through https://linusnep.github.io/EnvoDat/.
M2CURL: Sample-Efficient Multimodal Reinforcement Learning via Self-Supervised Representation Learning for Robotic Manipulation
Jan 30, 2024



One of the most critical aspects of multimodal Reinforcement Learning (RL) is the effective integration of different observation modalities. Having robust and accurate representations derived from these modalities is key to enhancing the robustness and sample efficiency of RL algorithms. However, learning representations in RL settings for visuotactile data poses significant challenges, particularly due to the high dimensionality of the data and the complexity involved in correlating visual and tactile inputs with the dynamic environment and task objectives. To address these challenges, we propose Multimodal Contrastive Unsupervised Reinforcement Learning (M2CURL). Our approach employs a novel multimodal self-supervised learning technique that learns efficient representations and contributes to faster convergence of RL algorithms. Our method is agnostic to the RL algorithm, thus enabling its integration with any available RL algorithm. We evaluate M2CURL on the Tactile Gym 2 simulator and we show that it significantly enhances the learning efficiency in different manipulation tasks. This is evidenced by faster convergence rates and higher cumulative rewards per episode, compared to standard RL algorithms without our representation learning approach.
Multimodal Visual-Tactile Representation Learning through Self-Supervised Contrastive Pre-Training
Jan 22, 2024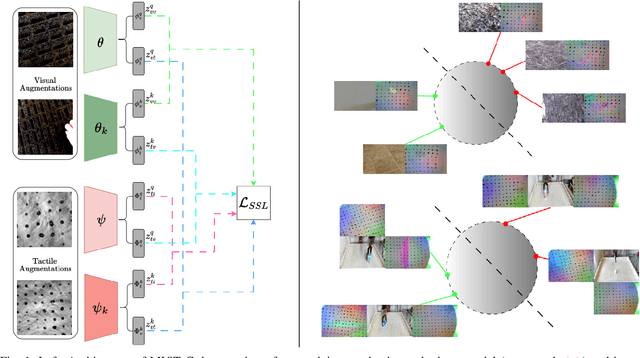
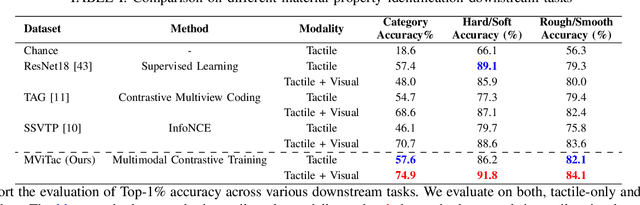

The rapidly evolving field of robotics necessitates methods that can facilitate the fusion of multiple modalities. Specifically, when it comes to interacting with tangible objects, effectively combining visual and tactile sensory data is key to understanding and navigating the complex dynamics of the physical world, enabling a more nuanced and adaptable response to changing environments. Nevertheless, much of the earlier work in merging these two sensory modalities has relied on supervised methods utilizing datasets labeled by humans.This paper introduces MViTac, a novel methodology that leverages contrastive learning to integrate vision and touch sensations in a self-supervised fashion. By availing both sensory inputs, MViTac leverages intra and inter-modality losses for learning representations, resulting in enhanced material property classification and more adept grasping prediction. Through a series of experiments, we showcase the effectiveness of our method and its superiority over existing state-of-the-art self-supervised and supervised techniques. In evaluating our methodology, we focus on two distinct tasks: material classification and grasping success prediction. Our results indicate that MViTac facilitates the development of improved modality encoders, yielding more robust representations as evidenced by linear probing assessments.
Orientation Probabilistic Movement Primitives on Riemannian Manifolds
Oct 28, 2021


Learning complex robot motions necessarily demands to have models that are able to encode and retrieve full-pose trajectories when tasks are defined in operational spaces. Probabilistic movement primitives (ProMPs) stand out as a principled approach that models trajectory distributions learned from demonstrations. ProMPs allow for trajectory modulation and blending to achieve better generalization to novel situations. However, when ProMPs are employed in operational space, their original formulation does not directly apply to full-pose movements including rotational trajectories described by quaternions. This paper proposes a Riemannian formulation of ProMPs that enables encoding and retrieving of quaternion trajectories. Our method builds on Riemannian manifold theory, and exploits multilinear geodesic regression for estimating the ProMPs parameters. This novel approach makes ProMPs a suitable model for learning complex full-pose robot motion patterns. Riemannian ProMPs are tested on toy examples to illustrate their workflow, and on real learning-from-demonstration experiments.