 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViTaPEs: Visuotactile Position Encodings for Cross-Modal Alignment in Multimodal Transformers
May 26, 2025



Tactile sensing provides local essential information that is complementary to visual perception, such as texture, compliance, and force. Despite recent advances in visuotactile representation learning, challenges remain in fusing these modalities and generalizing across tasks and environments without heavy reliance on pre-trained vision-language models. Moreover, existing methods do not study positional encodings, thereby overlooking the multi-scale spatial reasoning needed to capture fine-grained visuotactile correlations. We introduce ViTaPEs, a transformer-based framework that robustly integrates visual and tactile input data to learn task-agnostic representations for visuotactile perception. Our approach exploits a novel multi-scale positional encoding scheme to capture intra-modal structures, while simultaneously modeling cross-modal cues. Unlike prior work, we provide provable guarantees in visuotactile fusion, showing that our encodings are injective, rigid-motion-equivariant, and information-preserving, validating these properties empirically. Experiments on multiple large-scale real-world datasets show that ViTaPEs not only surpasses state-of-the-art baselines across various recognition tasks but also demonstrates zero-shot generalization to unseen, out-of-domain scenarios. We further demonstrate the transfer-learning strength of ViTaPEs in a robotic grasping task, where it outperforms state-of-the-art baselines in predicting grasp success. Project page: https://sites.google.com/view/vitapes
ED-VAE: Entropy Decomposition of ELBO in Variational Autoencoders
Jul 09, 2024


Traditional Variational Autoencoders (VAEs) are constrained by the limitations of the Evidence Lower Bound (ELBO) formulation, particularly when utilizing simplistic, non-analytic, or unknown prior distributions. These limitations inhibit the VAE's ability to generate high-quality samples and provide clear, interpretable latent representations. This work introduces the Entropy Decomposed Variational Autoencoder (ED-VAE), a novel re-formulation of the ELBO that explicitly includes entropy and cross-entropy components. This reformulation significantly enhances model flexibility, allowing for the integration of complex and non-standard priors. By providing more detailed control over the encoding and regularization of latent spaces, ED-VAE not only improves interpretability but also effectively captures the complex interactions between latent variables and observed data, thus leading to better generative performance.
M2CURL: Sample-Efficient Multimodal Reinforcement Learning via Self-Supervised Representation Learning for Robotic Manipulation
Jan 30, 2024



One of the most critical aspects of multimodal Reinforcement Learning (RL) is the effective integration of different observation modalities. Having robust and accurate representations derived from these modalities is key to enhancing the robustness and sample efficiency of RL algorithms. However, learning representations in RL settings for visuotactile data poses significant challenges, particularly due to the high dimensionality of the data and the complexity involved in correlating visual and tactile inputs with the dynamic environment and task objectives. To address these challenges, we propose Multimodal Contrastive Unsupervised Reinforcement Learning (M2CURL). Our approach employs a novel multimodal self-supervised learning technique that learns efficient representations and contributes to faster convergence of RL algorithms. Our method is agnostic to the RL algorithm, thus enabling its integration with any available RL algorithm. We evaluate M2CURL on the Tactile Gym 2 simulator and we show that it significantly enhances the learning efficiency in different manipulation tasks. This is evidenced by faster convergence rates and higher cumulative rewards per episode, compared to standard RL algorithms without our representation learning approach.
Multimodal Visual-Tactile Representation Learning through Self-Supervised Contrastive Pre-Training
Jan 22, 2024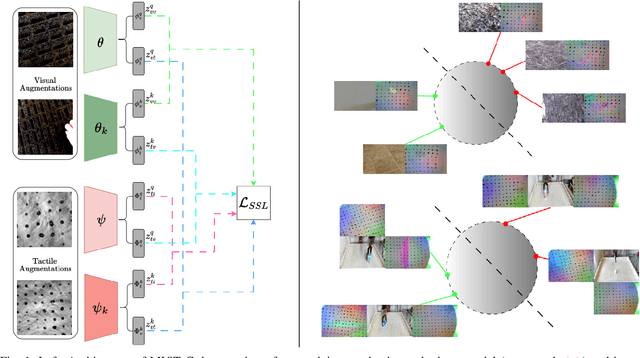
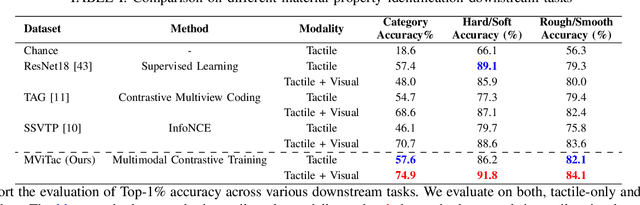

The rapidly evolving field of robotics necessitates methods that can facilitate the fusion of multiple modalities. Specifically, when it comes to interacting with tangible objects, effectively combining visual and tactile sensory data is key to understanding and navigating the complex dynamics of the physical world, enabling a more nuanced and adaptable response to changing environments. Nevertheless, much of the earlier work in merging these two sensory modalities has relied on supervised methods utilizing datasets labeled by humans.This paper introduces MViTac, a novel methodology that leverages contrastive learning to integrate vision and touch sensations in a self-supervised fashion. By availing both sensory inputs, MViTac leverages intra and inter-modality losses for learning representations, resulting in enhanced material property classification and more adept grasping prediction. Through a series of experiments, we showcase the effectiveness of our method and its superiority over existing state-of-the-art self-supervised and supervised techniques. In evaluating our methodology, we focus on two distinct tasks: material classification and grasping success prediction. Our results indicate that MViTac facilitates the development of improved modality encoders, yielding more robust representations as evidenced by linear probing assessments.
CR-VAE: Contrastive Regularization on Variational Autoencoders for Preventing Posterior Collapse
Sep 09, 2023



The Variational Autoencoder (VAE) is known to suffer from the phenomenon of \textit{posterior collapse}, where the latent representations generated by the model become independent of the inputs. This leads to degenerated representations of the input, which is attributed to the limitations of the VAE's objective function. In this work, we propose a novel solution to this issue, the Contrastive Regularization for Variational Autoencoders (CR-VAE). The core of our approach is to augment the original VAE with a contrastive objective that maximizes the mutual information between the representations of similar visual inputs. This strategy ensures that the information flow between the input and its latent representation is maximized, effectively avoiding posterior collapse. We evaluate our method on a series of visual datasets and demonstrate, that CR-VAE outperforms state-of-the-art approaches in preventing posterior collapse.
Sequential Late Fusion Technique for Multi-modal Sentiment Analysis
Jun 22, 2021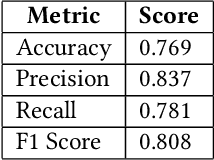
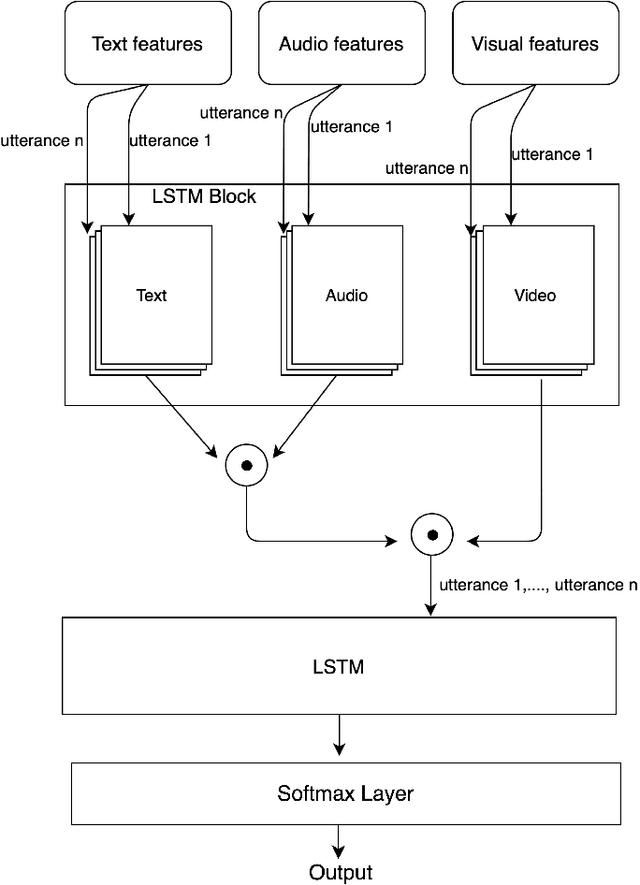
Multi-modal sentiment analysis plays an important role for providing better interactive experiences to users. Each modality in multi-modal data can provide different viewpoints or reveal unique aspects of a user's emotional state. In this work, we use text, audio and visual modalities from MOSI dataset and we propose a novel fusion technique using a multi-head attention LSTM network. Finally, we perform a classification task and evaluate its performance.