Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Late Fusion Technique for Multi-modal Sentiment Analysis
Paper and Code
Jun 22, 2021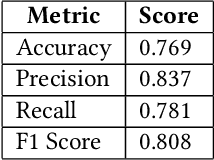
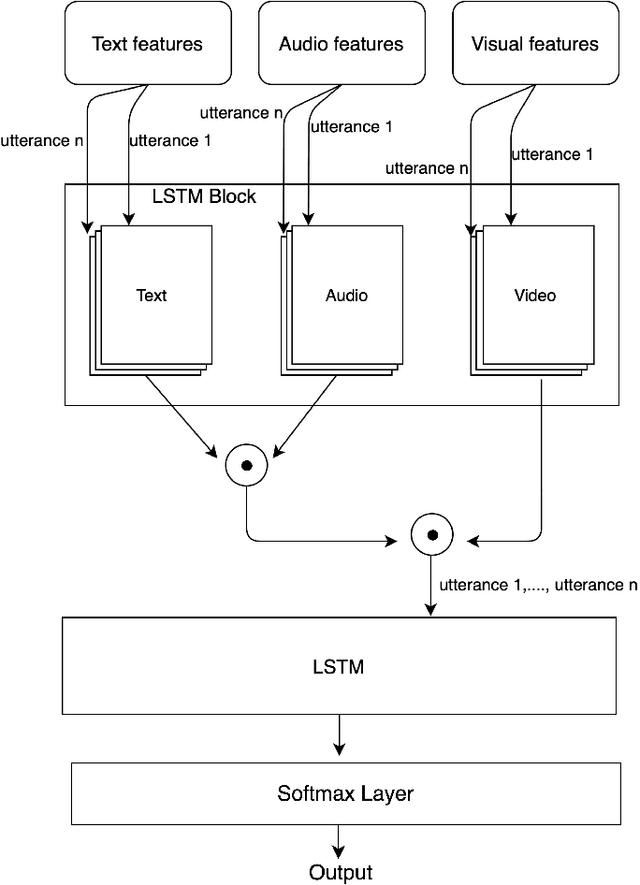
Multi-modal sentiment analysis plays an important role for providing better interactive experiences to users. Each modality in multi-modal data can provide different viewpoints or reveal unique aspects of a user's emotional state. In this work, we use text, audio and visual modalities from MOSI dataset and we propose a novel fusion technique using a multi-head attention LSTM network. Finally, we perform a classification task and evaluate its performance.
* 2 pages, 1 figure, 1 table
View paper on