 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttacks against Ranking Algorithms with Text Embeddings: a Case Study on Recruitment Algorithms
Aug 12, 2021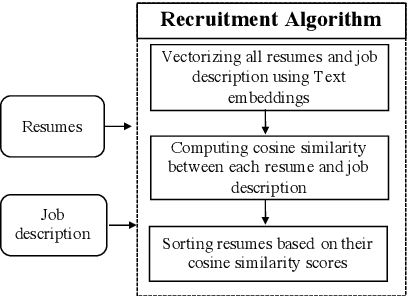
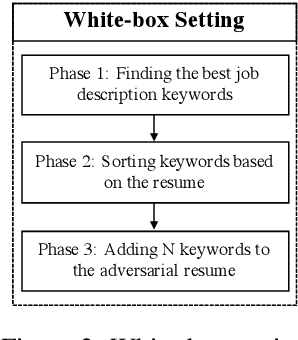
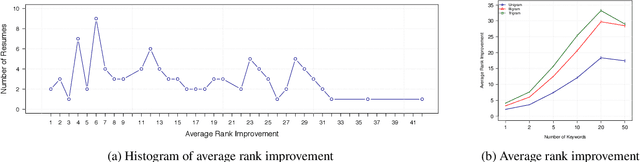
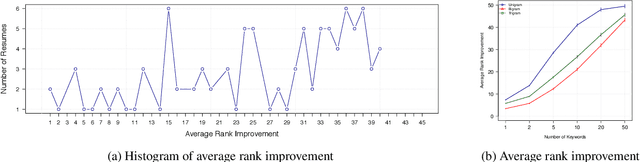
Recently, some studies have shown that text classification tasks are vulnerable to poisoning and evasion attacks. However, little work has investigated attacks against decision making algorithms that use text embeddings, and their output is a ranking. In this paper, we focus on ranking algorithms for recruitment process, that employ text embeddings for ranking applicants resumes when compared to a job description. We demonstrate both white box and black box attacks that identify text items, that based on their location in embedding space, have significant contribution in increasing the similarity score between a resume and a job description. The adversary then uses these text items to improve the ranking of their resume among others. We tested recruitment algorithms that use the similarity scores obtained from Universal Sentence Encoder (USE) and Term Frequency Inverse Document Frequency (TF IDF) vectors. Our results show that in both adversarial settings, on average the attacker is successful. We also found that attacks against TF IDF is more successful compared to USE.
Sequential Late Fusion Technique for Multi-modal Sentiment Analysis
Jun 22, 2021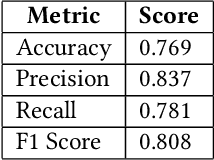
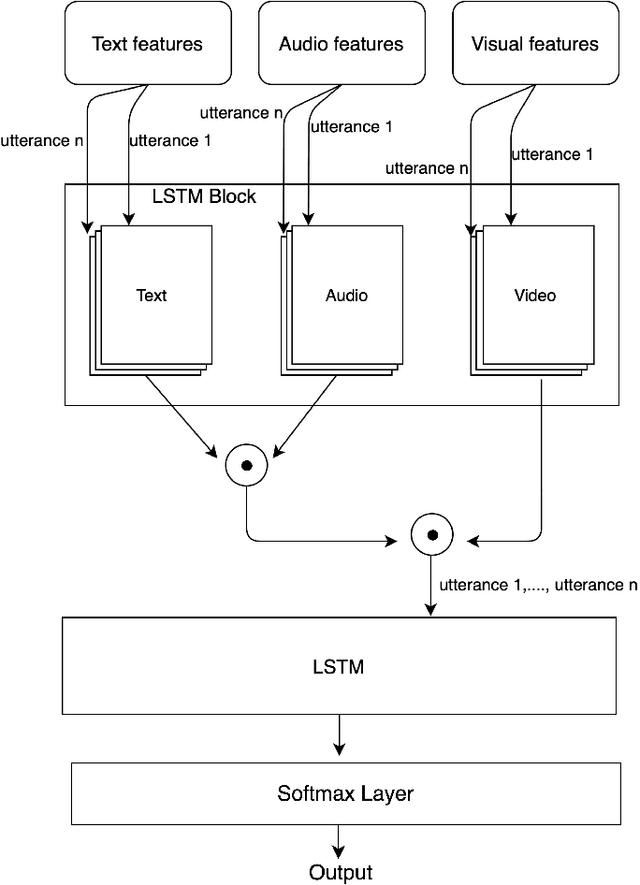
Multi-modal sentiment analysis plays an important role for providing better interactive experiences to users. Each modality in multi-modal data can provide different viewpoints or reveal unique aspects of a user's emotional state. In this work, we use text, audio and visual modalities from MOSI dataset and we propose a novel fusion technique using a multi-head attention LSTM network. Finally, we perform a classification task and evaluate its performance.
A Survey on Contrastive Self-supervised Learning
Oct 31, 2020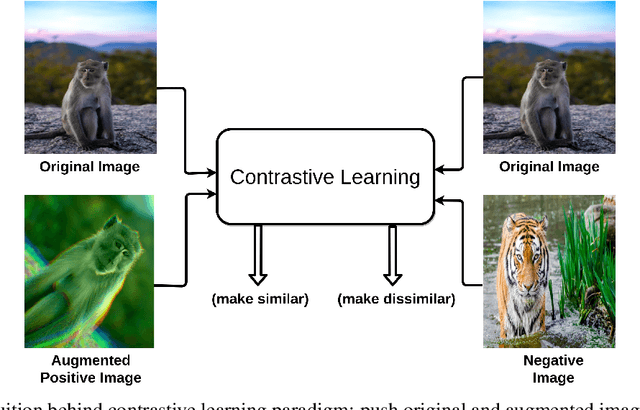
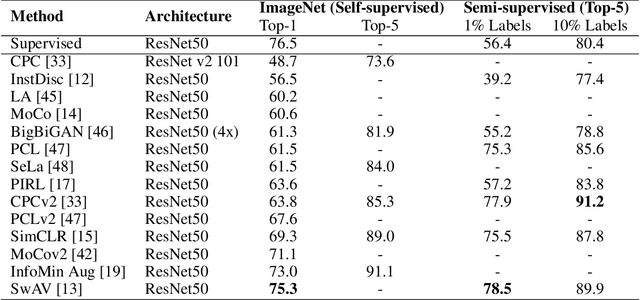
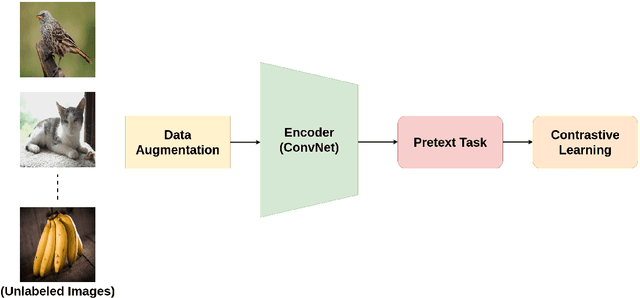
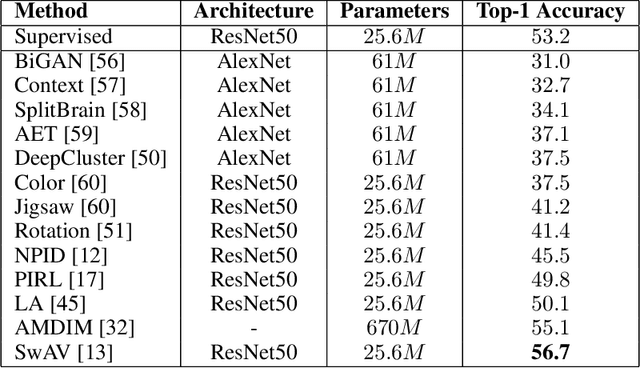
Self-supervised learning has gained popularity because of its ability to avoid the cost of annotating large-scale datasets. It is capable of adopting self-defined pseudo labels as supervision and use the learned representations for several downstream tasks. Specifically, contrastive learning has recently become a dominant component in self-supervised learning methods for computer vision, natural language processing (NLP), and other domains. It aims at embedding augmented versions of the same sample close to each other while trying to push away embeddings from different samples. This paper provides an extensive review of self-supervised methods that follow the contrastive approach. The work explains commonly used pretext tasks in a contrastive learning setup, followed by different architectures that have been proposed so far. Next, we have a performance comparison of different methods for multiple downstream tasks such as image classification, object detection, and action recognition. Finally, we conclude with the limitations of the current methods and the need for further techniques and future directions to make substantial progress.