 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming Data Challenges in ML-based Security Tasks: Lessons from Integrating Generative AI
Jul 08, 2025Machine learning-based supervised classifiers are widely used for security tasks, and their improvement has been largely focused on algorithmic advancements. We argue that data challenges that negatively impact the performance of these classifiers have received limited attention. We address the following research question: Can developments in Generative AI (GenAI) address these data challenges and improve classifier performance? We propose augmenting training datasets with synthetic data generated using GenAI techniques to improve classifier generalization. We evaluate this approach across 7 diverse security tasks using 6 state-of-the-art GenAI methods and introduce a novel GenAI scheme called Nimai that enables highly controlled data synthesis. We find that GenAI techniques can significantly improve the performance of security classifiers, achieving improvements of up to 32.6% even in severely data-constrained settings (only ~180 training samples). Furthermore, we demonstrate that GenAI can facilitate rapid adaptation to concept drift post-deployment, requiring minimal labeling in the adjustment process. Despite successes, our study finds that some GenAI schemes struggle to initialize (train and produce data) on certain security tasks. We also identify characteristics of specific tasks, such as noisy labels, overlapping class distributions, and sparse feature vectors, which hinder performance boost using GenAI. We believe that our study will drive the development of future GenAI tools designed for security tasks.
FairDeFace: Evaluating the Fairness and Adversarial Robustness of Face Obfuscation Methods
Mar 11, 2025The lack of a common platform and benchmark datasets for evaluating face obfuscation methods has been a challenge, with every method being tested using arbitrary experiments, datasets, and metrics. While prior work has demonstrated that face recognition systems exhibit bias against some demographic groups, there exists a substantial gap in our understanding regarding the fairness of face obfuscation methods. Providing fair face obfuscation methods can ensure equitable protection across diverse demographic groups, especially since they can be used to preserve the privacy of vulnerable populations. To address these gaps, this paper introduces a comprehensive framework, named FairDeFace, designed to assess the adversarial robustness and fairness of face obfuscation methods. The framework introduces a set of modules encompassing data benchmarks, face detection and recognition algorithms, adversarial models, utility detection models, and fairness metrics. FairDeFace serves as a versatile platform where any face obfuscation method can be integrated, allowing for rigorous testing and comparison with other state-of-the-art methods. In its current implementation, FairDeFace incorporates 6 attacks, and several privacy, utility and fairness metrics. Using FairDeFace, and by conducting more than 500 experiments, we evaluated and compared the adversarial robustness of seven face obfuscation methods. This extensive analysis led to many interesting findings both in terms of the degree of robustness of existing methods and their biases against some gender or racial groups. FairDeFace also uses visualization of focused areas for both obfuscation and verification attacks to show not only which areas are mostly changed in the obfuscation process for some demographics, but also why they failed through focus area comparison of obfuscation and verification.
Attacks against Abstractive Text Summarization Models through Lead Bias and Influence Functions
Oct 26, 2024



Large Language Models have introduced novel opportunities for text comprehension and generation. Yet, they are vulnerable to adversarial perturbations and data poisoning attacks, particularly in tasks like text classification and translation. However, the adversarial robustness of abstractive text summarization models remains less explored. In this work, we unveil a novel approach by exploiting the inherent lead bias in summarization models, to perform adversarial perturbations. Furthermore, we introduce an innovative application of influence functions, to execute data poisoning, which compromises the model's integrity. This approach not only shows a skew in the models behavior to produce desired outcomes but also shows a new behavioral change, where models under attack tend to generate extractive summaries rather than abstractive summaries.
Utilizing Large Language Models to Optimize the Detection and Explainability of Phishing Websites
Aug 11, 2024



In this paper, we introduce PhishLang, an open-source, lightweight Large Language Model (LLM) specifically designed for phishing website detection through contextual analysis of the website. Unlike traditional heuristic or machine learning models that rely on static features and struggle to adapt to new threats and deep learning models that are computationally intensive, our model utilizes the advanced language processing capabilities of LLMs to learn granular features that are characteristic of phishing attacks. Furthermore, PhishLang operates with minimal data preprocessing and offers performance comparable to leading deep learning tools, while being significantly faster and less resource-intensive. Over a 3.5-month testing period, PhishLang successfully identified approximately 26K phishing URLs, many of which were undetected by popular antiphishing blocklists, thus demonstrating its potential to aid current detection measures. We also evaluate PhishLang against several realistic adversarial attacks and develop six patches that make it very robust against such threats. Furthermore, we integrate PhishLang with GPT-3.5 Turbo to create \textit{explainable blocklisting} - warnings that provide users with contextual information about different features that led to a website being marked as phishing. Finally, we have open-sourced the PhishLang framework and developed a Chromium-based browser extension and URL scanner website, which implement explainable warnings for end-users.
Vulnerabilities Unveiled: Adversarially Attacking a Multimodal Vision Language Model for Pathology Imaging
Jan 08, 2024



In the dynamic landscape of medical artificial intelligence, this study explores the vulnerabilities of the Pathology Language-Image Pretraining (PLIP) model, a Vision Language Foundation model, under targeted adversarial conditions. Leveraging the Kather Colon dataset with 7,180 H&E images across nine tissue types, our investigation employs Projected Gradient Descent (PGD) adversarial attacks to intentionally induce misclassifications. The outcomes reveal a 100% success rate in manipulating PLIP's predictions, underscoring its susceptibility to adversarial perturbations. The qualitative analysis of adversarial examples delves into the interpretability challenges, shedding light on nuanced changes in predictions induced by adversarial manipulations. These findings contribute crucial insights into the interpretability, domain adaptation, and trustworthiness of Vision Language Models in medical imaging. The study emphasizes the pressing need for robust defenses to ensure the reliability of AI models.
From Chatbots to PhishBots? -- Preventing Phishing scams created using ChatGPT, Google Bard and Claude
Oct 29, 2023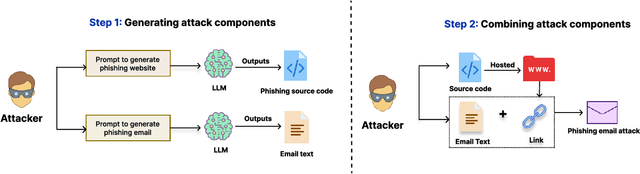


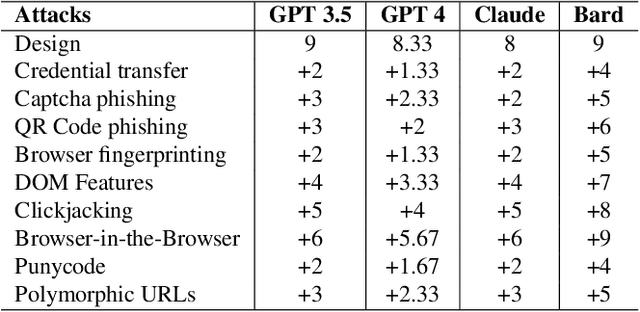
The advanced capabilities of Large Language Models (LLMs) have made them invaluable across various applications, from conversational agents and content creation to data analysis, research, and innovation. However, their effectiveness and accessibility also render them susceptible to abuse for generating malicious content, including phishing attacks. This study explores the potential of using four popular commercially available LLMs - ChatGPT (GPT 3.5 Turbo), GPT 4, Claude and Bard to generate functional phishing attacks using a series of malicious prompts. We discover that these LLMs can generate both phishing emails and websites that can convincingly imitate well-known brands, and also deploy a range of evasive tactics for the latter to elude detection mechanisms employed by anti-phishing systems. Notably, these attacks can be generated using unmodified, or "vanilla," versions of these LLMs, without requiring any prior adversarial exploits such as jailbreaking. As a countermeasure, we build a BERT based automated detection tool that can be used for the early detection of malicious prompts to prevent LLMs from generating phishing content attaining an accuracy of 97\% for phishing website prompts, and 94\% for phishing email prompts.
Generating Phishing Attacks using ChatGPT
May 09, 2023



The ability of ChatGPT to generate human-like responses and understand context has made it a popular tool for conversational agents, content creation, data analysis, and research and innovation. However, its effectiveness and ease of accessibility makes it a prime target for generating malicious content, such as phishing attacks, that can put users at risk. In this work, we identify several malicious prompts that can be provided to ChatGPT to generate functional phishing websites. Through an iterative approach, we find that these phishing websites can be made to imitate popular brands and emulate several evasive tactics that have been known to avoid detection by anti-phishing entities. These attacks can be generated using vanilla ChatGPT without the need of any prior adversarial exploits (jailbreaking).
StyleGAN as a Utility-Preserving Face De-identification Method
Dec 05, 2022



Several face de-identification methods have been proposed to preserve users' privacy by obscuring their faces. These methods, however, can degrade the quality of photos, and they usually do not preserve the utility of faces, e.g., their age, gender, pose, and facial expression. Recently, advanced generative adversarial network models, such as StyleGAN, have been proposed, which generate realistic, high-quality imaginary faces. In this paper, we investigate the use of StyleGAN in generating de-identified faces through style mixing, where the styles or features of the target face and an auxiliary face get mixed to generate a de-identified face that carries the utilities of the target face. We examined this de-identification method with respect to preserving utility and privacy, by implementing several face detection, verification, and identification attacks. Through extensive experiments and also comparing with two state-of-the-art face de-identification methods, we show that StyleGAN preserves the quality and utility of the faces much better than the other approaches and also by choosing the style mixing levels correctly, it can preserve the privacy of the faces much better than other methods.
Evaluating the effectiveness of Phishing Reports on Twitter
Nov 13, 2021
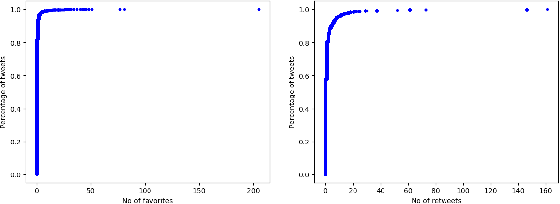
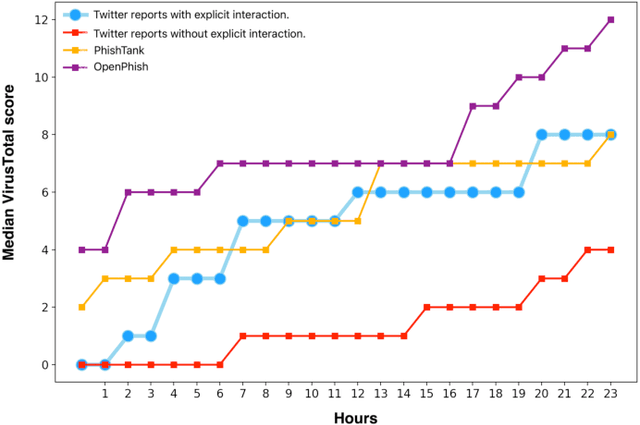

Phishing attacks are an increasingly potent web-based threat, with nearly 1.5 million websites created on a monthly basis. In this work, we present the first study towards identifying such attacks through phishing reports shared by users on Twitter. We evaluated over 16.4k such reports posted by 701 Twitter accounts between June to August 2021, which contained 11.1k unique URLs, and analyzed their effectiveness using various quantitative and qualitative measures. Our findings indicate that not only do these users share a high volume of legitimate phishing URLs, but these reports contain more information regarding the phishing websites (which can expedite the process of identifying and removing these threats), when compared to two popular open-source phishing feeds: PhishTank and OpenPhish. We also notice that the reported websites had very little overlap with the URLs existing in the other feeds, and also remained active for longer periods of time. But despite having these attributes, we found that these reports have very low interaction from other Twitter users, especially from the domains and organizations targeted by the reported URLs. Moreover, nearly 31% of these URLs were still active even after a week of them being reported, with 27% of them being detected by very few anti-phishing tools, suggesting that a large majority of these reports remain undiscovered, despite the majority of the follower base of these accounts being security focused users. Thus, this work highlights the effectiveness of the reports, and the benefits of using them as an open source knowledge base for identifying new phishing websites.
Attacks against Ranking Algorithms with Text Embeddings: a Case Study on Recruitment Algorithms
Aug 12, 2021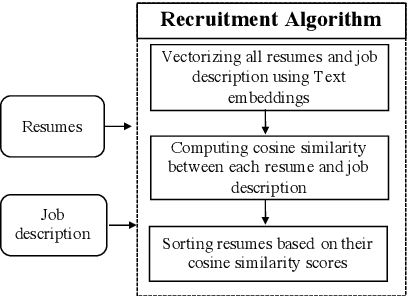
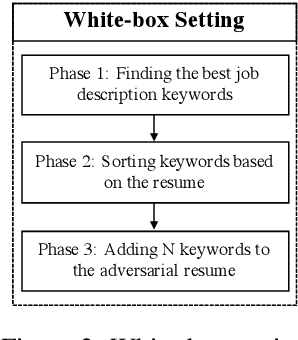
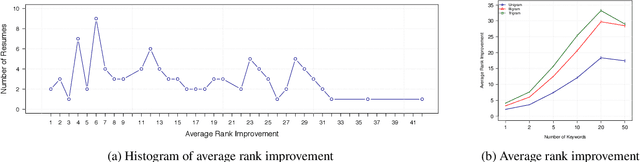
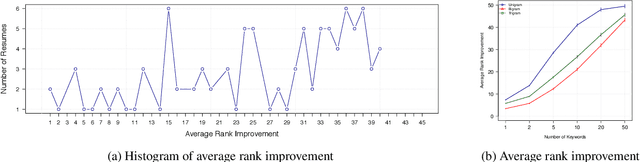
Recently, some studies have shown that text classification tasks are vulnerable to poisoning and evasion attacks. However, little work has investigated attacks against decision making algorithms that use text embeddings, and their output is a ranking. In this paper, we focus on ranking algorithms for recruitment process, that employ text embeddings for ranking applicants resumes when compared to a job description. We demonstrate both white box and black box attacks that identify text items, that based on their location in embedding space, have significant contribution in increasing the similarity score between a resume and a job description. The adversary then uses these text items to improve the ranking of their resume among others. We tested recruitment algorithms that use the similarity scores obtained from Universal Sentence Encoder (USE) and Term Frequency Inverse Document Frequency (TF IDF) vectors. Our results show that in both adversarial settings, on average the attacker is successful. We also found that attacks against TF IDF is more successful compared to USE.