 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairDeFace: Evaluating the Fairness and Adversarial Robustness of Face Obfuscation Methods
Mar 11, 2025The lack of a common platform and benchmark datasets for evaluating face obfuscation methods has been a challenge, with every method being tested using arbitrary experiments, datasets, and metrics. While prior work has demonstrated that face recognition systems exhibit bias against some demographic groups, there exists a substantial gap in our understanding regarding the fairness of face obfuscation methods. Providing fair face obfuscation methods can ensure equitable protection across diverse demographic groups, especially since they can be used to preserve the privacy of vulnerable populations. To address these gaps, this paper introduces a comprehensive framework, named FairDeFace, designed to assess the adversarial robustness and fairness of face obfuscation methods. The framework introduces a set of modules encompassing data benchmarks, face detection and recognition algorithms, adversarial models, utility detection models, and fairness metrics. FairDeFace serves as a versatile platform where any face obfuscation method can be integrated, allowing for rigorous testing and comparison with other state-of-the-art methods. In its current implementation, FairDeFace incorporates 6 attacks, and several privacy, utility and fairness metrics. Using FairDeFace, and by conducting more than 500 experiments, we evaluated and compared the adversarial robustness of seven face obfuscation methods. This extensive analysis led to many interesting findings both in terms of the degree of robustness of existing methods and their biases against some gender or racial groups. FairDeFace also uses visualization of focused areas for both obfuscation and verification attacks to show not only which areas are mostly changed in the obfuscation process for some demographics, but also why they failed through focus area comparison of obfuscation and verification.
Attacks against Abstractive Text Summarization Models through Lead Bias and Influence Functions
Oct 26, 2024



Large Language Models have introduced novel opportunities for text comprehension and generation. Yet, they are vulnerable to adversarial perturbations and data poisoning attacks, particularly in tasks like text classification and translation. However, the adversarial robustness of abstractive text summarization models remains less explored. In this work, we unveil a novel approach by exploiting the inherent lead bias in summarization models, to perform adversarial perturbations. Furthermore, we introduce an innovative application of influence functions, to execute data poisoning, which compromises the model's integrity. This approach not only shows a skew in the models behavior to produce desired outcomes but also shows a new behavioral change, where models under attack tend to generate extractive summaries rather than abstractive summaries.
Vulnerabilities Unveiled: Adversarially Attacking a Multimodal Vision Language Model for Pathology Imaging
Jan 08, 2024



In the dynamic landscape of medical artificial intelligence, this study explores the vulnerabilities of the Pathology Language-Image Pretraining (PLIP) model, a Vision Language Foundation model, under targeted adversarial conditions. Leveraging the Kather Colon dataset with 7,180 H&E images across nine tissue types, our investigation employs Projected Gradient Descent (PGD) adversarial attacks to intentionally induce misclassifications. The outcomes reveal a 100% success rate in manipulating PLIP's predictions, underscoring its susceptibility to adversarial perturbations. The qualitative analysis of adversarial examples delves into the interpretability challenges, shedding light on nuanced changes in predictions induced by adversarial manipulations. These findings contribute crucial insights into the interpretability, domain adaptation, and trustworthiness of Vision Language Models in medical imaging. The study emphasizes the pressing need for robust defenses to ensure the reliability of AI models.
From Chatbots to PhishBots? -- Preventing Phishing scams created using ChatGPT, Google Bard and Claude
Oct 29, 2023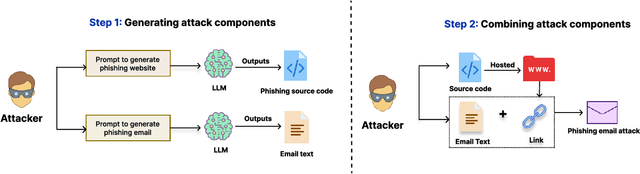


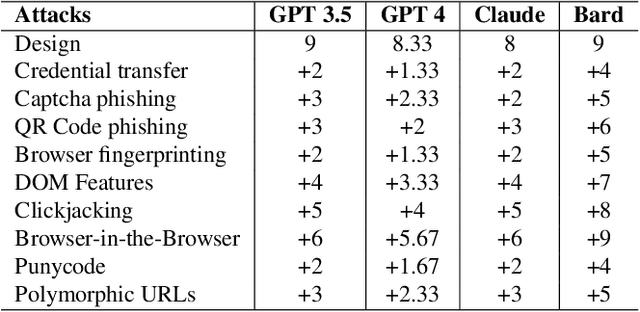
The advanced capabilities of Large Language Models (LLMs) have made them invaluable across various applications, from conversational agents and content creation to data analysis, research, and innovation. However, their effectiveness and accessibility also render them susceptible to abuse for generating malicious content, including phishing attacks. This study explores the potential of using four popular commercially available LLMs - ChatGPT (GPT 3.5 Turbo), GPT 4, Claude and Bard to generate functional phishing attacks using a series of malicious prompts. We discover that these LLMs can generate both phishing emails and websites that can convincingly imitate well-known brands, and also deploy a range of evasive tactics for the latter to elude detection mechanisms employed by anti-phishing systems. Notably, these attacks can be generated using unmodified, or "vanilla," versions of these LLMs, without requiring any prior adversarial exploits such as jailbreaking. As a countermeasure, we build a BERT based automated detection tool that can be used for the early detection of malicious prompts to prevent LLMs from generating phishing content attaining an accuracy of 97\% for phishing website prompts, and 94\% for phishing email prompts.