 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Chatbots to PhishBots? -- Preventing Phishing scams created using ChatGPT, Google Bard and Claude
Oct 29, 2023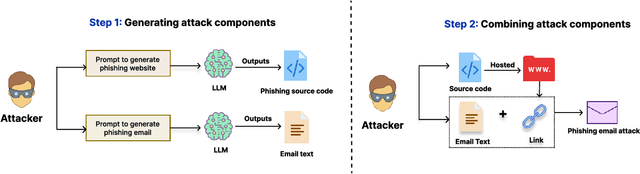


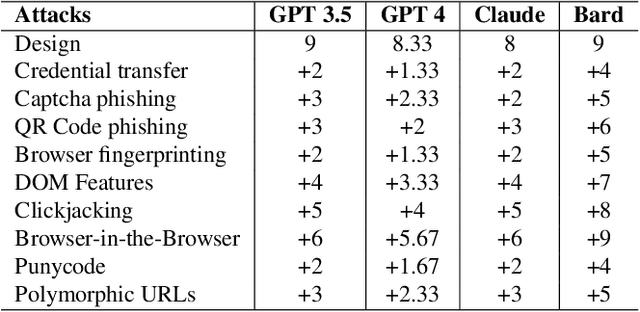
The advanced capabilities of Large Language Models (LLMs) have made them invaluable across various applications, from conversational agents and content creation to data analysis, research, and innovation. However, their effectiveness and accessibility also render them susceptible to abuse for generating malicious content, including phishing attacks. This study explores the potential of using four popular commercially available LLMs - ChatGPT (GPT 3.5 Turbo), GPT 4, Claude and Bard to generate functional phishing attacks using a series of malicious prompts. We discover that these LLMs can generate both phishing emails and websites that can convincingly imitate well-known brands, and also deploy a range of evasive tactics for the latter to elude detection mechanisms employed by anti-phishing systems. Notably, these attacks can be generated using unmodified, or "vanilla," versions of these LLMs, without requiring any prior adversarial exploits such as jailbreaking. As a countermeasure, we build a BERT based automated detection tool that can be used for the early detection of malicious prompts to prevent LLMs from generating phishing content attaining an accuracy of 97\% for phishing website prompts, and 94\% for phishing email prompts.
Generating Phishing Attacks using ChatGPT
May 09, 2023



The ability of ChatGPT to generate human-like responses and understand context has made it a popular tool for conversational agents, content creation, data analysis, and research and innovation. However, its effectiveness and ease of accessibility makes it a prime target for generating malicious content, such as phishing attacks, that can put users at risk. In this work, we identify several malicious prompts that can be provided to ChatGPT to generate functional phishing websites. Through an iterative approach, we find that these phishing websites can be made to imitate popular brands and emulate several evasive tactics that have been known to avoid detection by anti-phishing entities. These attacks can be generated using vanilla ChatGPT without the need of any prior adversarial exploits (jailbreaking).