 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Codebook VQ: Enhanced Image Reconstruction with Reduced Codebook Size
Mar 13, 2025



Vector Quantization (VQ) techniques face significant challenges in codebook utilization, limiting reconstruction fidelity in image modeling. We introduce a Dual Codebook mechanism that effectively addresses this limitation by partitioning the representation into complementary global and local components. The global codebook employs a lightweight transformer for concurrent updates of all code vectors, while the local codebook maintains precise feature representation through deterministic selection. This complementary approach is trained from scratch without requiring pre-trained knowledge. Experimental evaluation across multiple standard benchmark datasets demonstrates state-of-the-art reconstruction quality while using a compact codebook of size 512 - half the size of previous methods that require pre-training. Our approach achieves significant FID improvements across diverse image domains, particularly excelling in scene and face reconstruction tasks. These results establish Dual Codebook VQ as an efficient paradigm for high-fidelity image reconstruction with significantly reduced computational requirements.
Evaluating Text Classification Robustness to Part-of-Speech Adversarial Examples
Aug 15, 2024As machine learning systems become more widely used, especially for safety critical applications, there is a growing need to ensure that these systems behave as intended, even in the face of adversarial examples. Adversarial examples are inputs that are designed to trick the decision making process, and are intended to be imperceptible to humans. However, for text-based classification systems, changes to the input, a string of text, are always perceptible. Therefore, text-based adversarial examples instead focus on trying to preserve semantics. Unfortunately, recent work has shown this goal is often not met. To improve the quality of text-based adversarial examples, we need to know what elements of the input text are worth focusing on. To address this, in this paper, we explore what parts of speech have the highest impact of text-based classifiers. Our experiments highlight a distinct bias in CNN algorithms against certain parts of speech tokens within review datasets. This finding underscores a critical vulnerability in the linguistic processing capabilities of CNNs.
Attacks against Ranking Algorithms with Text Embeddings: a Case Study on Recruitment Algorithms
Aug 12, 2021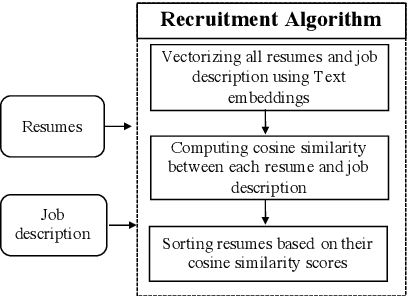
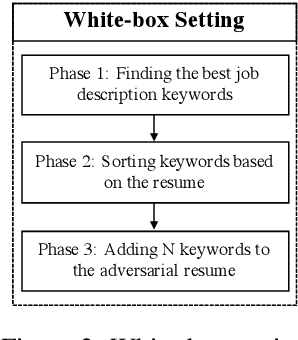
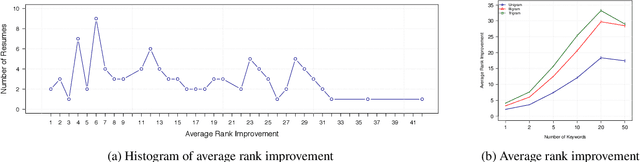
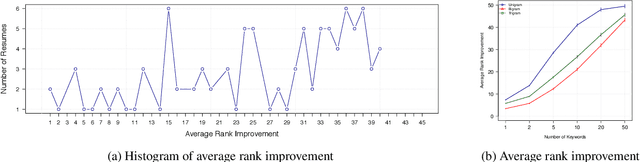
Recently, some studies have shown that text classification tasks are vulnerable to poisoning and evasion attacks. However, little work has investigated attacks against decision making algorithms that use text embeddings, and their output is a ranking. In this paper, we focus on ranking algorithms for recruitment process, that employ text embeddings for ranking applicants resumes when compared to a job description. We demonstrate both white box and black box attacks that identify text items, that based on their location in embedding space, have significant contribution in increasing the similarity score between a resume and a job description. The adversary then uses these text items to improve the ranking of their resume among others. We tested recruitment algorithms that use the similarity scores obtained from Universal Sentence Encoder (USE) and Term Frequency Inverse Document Frequency (TF IDF) vectors. Our results show that in both adversarial settings, on average the attacker is successful. We also found that attacks against TF IDF is more successful compared to USE.