 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Text Classification Robustness to Part-of-Speech Adversarial Examples
Aug 15, 2024As machine learning systems become more widely used, especially for safety critical applications, there is a growing need to ensure that these systems behave as intended, even in the face of adversarial examples. Adversarial examples are inputs that are designed to trick the decision making process, and are intended to be imperceptible to humans. However, for text-based classification systems, changes to the input, a string of text, are always perceptible. Therefore, text-based adversarial examples instead focus on trying to preserve semantics. Unfortunately, recent work has shown this goal is often not met. To improve the quality of text-based adversarial examples, we need to know what elements of the input text are worth focusing on. To address this, in this paper, we explore what parts of speech have the highest impact of text-based classifiers. Our experiments highlight a distinct bias in CNN algorithms against certain parts of speech tokens within review datasets. This finding underscores a critical vulnerability in the linguistic processing capabilities of CNNs.
LLM4TDD: Best Practices for Test Driven Development Using Large Language Models
Dec 07, 2023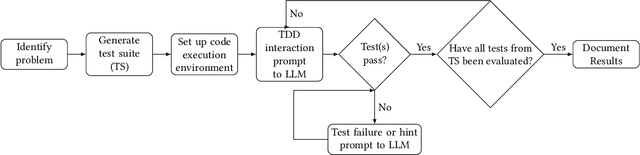
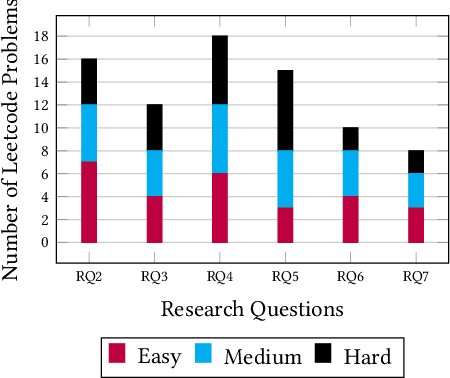
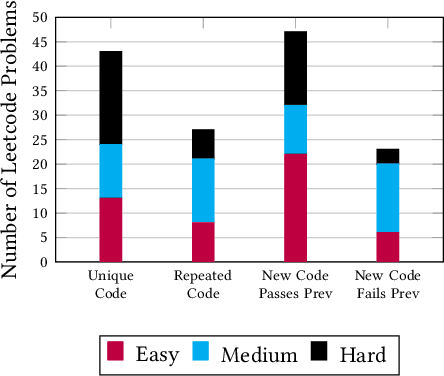

In today's society, we are becoming increasingly dependent on software systems. However, we also constantly witness the negative impacts of buggy software. Program synthesis aims to improve software correctness by automatically generating the program given an outline of the expected behavior. For decades, program synthesis has been an active research field, with recent approaches looking to incorporate Large Language Models to help generate code. This paper explores the concept of LLM4TDD, where we guide Large Language Models to generate code iteratively using a test-driven development methodology. We conduct an empirical evaluation using ChatGPT and coding problems from LeetCode to investigate the impact of different test, prompt and problem attributes on the efficacy of LLM4TDD.