 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM4TDD: Best Practices for Test Driven Development Using Large Language Models
Dec 07, 2023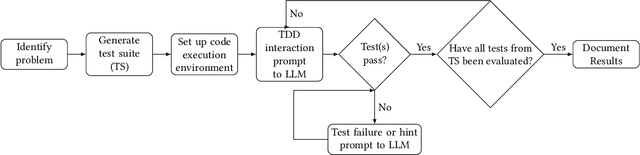
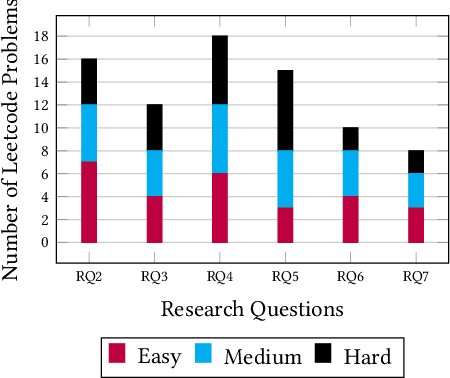
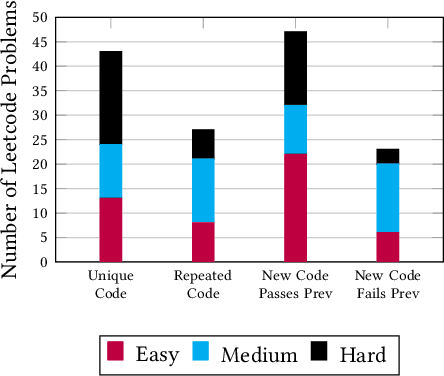

In today's society, we are becoming increasingly dependent on software systems. However, we also constantly witness the negative impacts of buggy software. Program synthesis aims to improve software correctness by automatically generating the program given an outline of the expected behavior. For decades, program synthesis has been an active research field, with recent approaches looking to incorporate Large Language Models to help generate code. This paper explores the concept of LLM4TDD, where we guide Large Language Models to generate code iteratively using a test-driven development methodology. We conduct an empirical evaluation using ChatGPT and coding problems from LeetCode to investigate the impact of different test, prompt and problem attributes on the efficacy of LLM4TDD.