 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess Forgetting for Better Generalization: Exploring Continual-learning Fine-tuning Methods for Speech Self-supervised Representations
Paper and Code
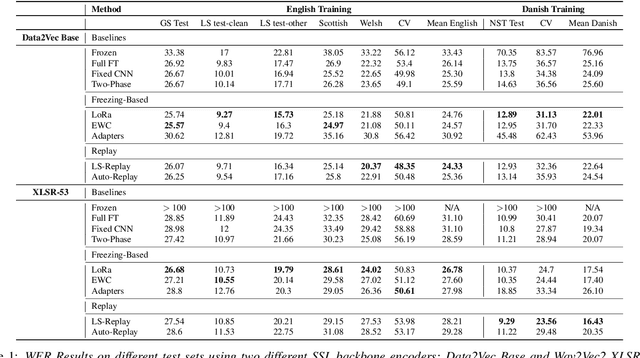
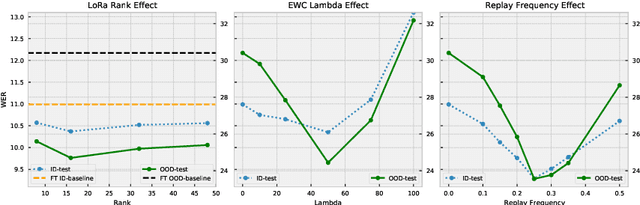
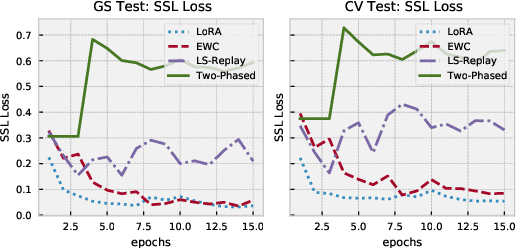
Despite being trained on massive and diverse datasets, speech self-supervised encoders are generally used for downstream purposes as mere frozen feature extractors or model initializers before fine-tuning. The former severely limits the exploitation of large encoders, while the latter hurts the robustness acquired during pretraining, especially in low-resource scenarios. This work explores middle-ground solutions, conjecturing that reducing the forgetting of the self-supervised task during the downstream fine-tuning leads to better generalization. To prove this, focusing on speech recognition, we benchmark different continual-learning approaches during fine-tuning and show that they improve both in-domain and out-of-domain generalization abilities. Relative performance gains reach 15.7% and 22.5% with XLSR used as the encoder on two English and Danish speech recognition tasks. Further probing experiments show that these gains are indeed linked to less forgetting.