 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatch to Win: Analysing Sequences Lengths for Efficient Self-supervised Learning in Speech and Audio
Paper and Code
Oct 03, 2022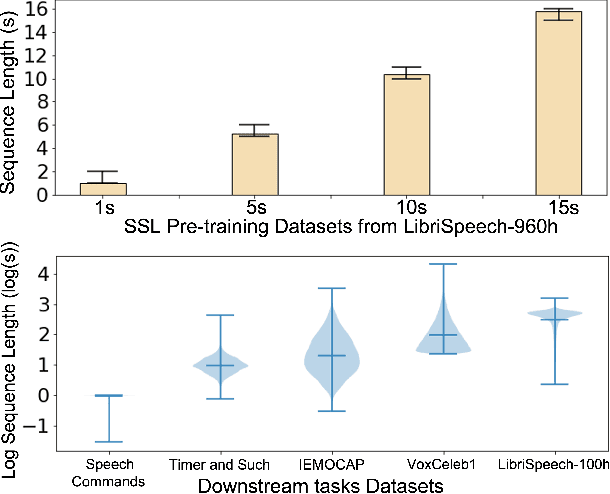

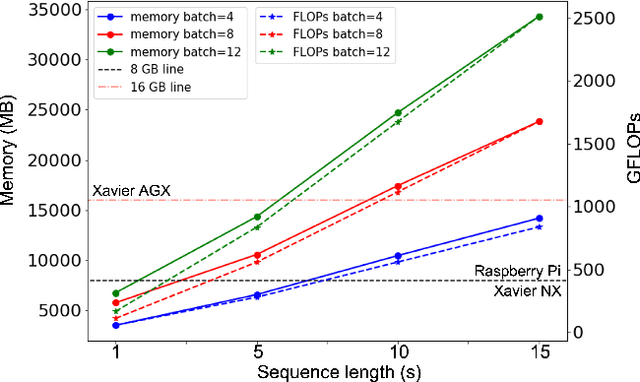
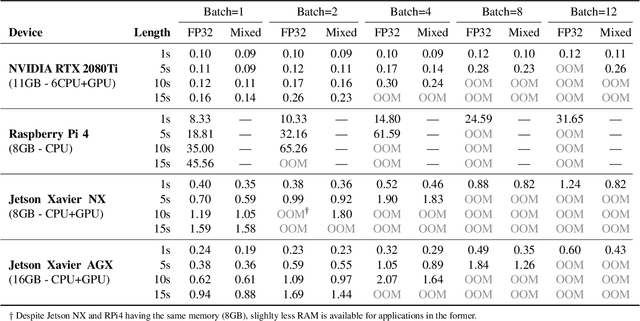
Self-supervised learning (SSL) has proven vital in speech and audio-related applications. The paradigm trains a general model on unlabeled data that can later be used to solve specific downstream tasks. This type of model is costly to train as it requires manipulating long input sequences that can only be handled by powerful centralised servers. Surprisingly, despite many attempts to increase training efficiency through model compression, the effects of truncating input sequence lengths to reduce computation have not been studied. In this paper, we provide the first empirical study of SSL pre-training for different specified sequence lengths and link this to various downstream tasks. We find that training on short sequences can dramatically reduce resource costs while retaining a satisfactory performance for all tasks. This simple one-line change would promote the migration of SSL training from data centres to user-end edge devices for more realistic and personalised applications.