 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointLoc: Deep Pose Regressor for LiDAR Point Cloud Localization
Paper and Code
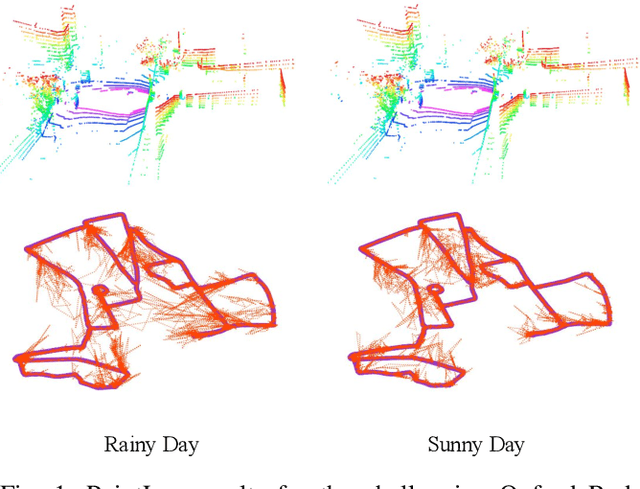
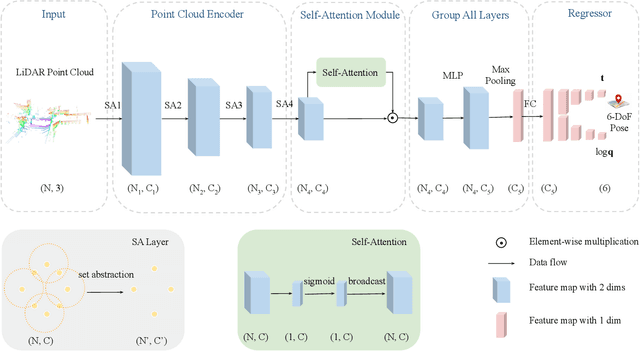
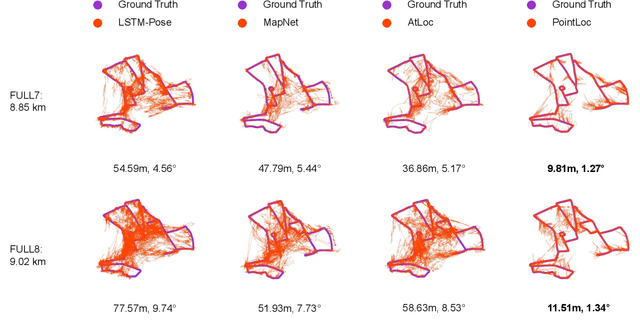
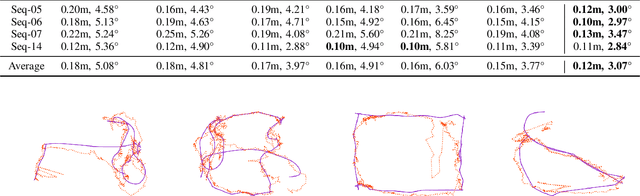
In this paper, we present a novel end-to-end learning-based LiDAR relocalization framework, termed PointLoc, which infers 6-DoF poses directly using only a single point cloud as input, without requiring a pre-built map. Compared to RGB image-based relocalization, LiDAR frames can provide rich and robust geometric information about a scene. However, LiDAR point clouds are sparse and unstructured making it difficult to apply traditional deep learning regression models for this task. We address this issue by proposing a novel PointNet-style architecture with self-attention to efficiently estimate 6-DoF poses from 360{\deg} LiDAR input frames. Extensive experiments on recently released challenging Oxford Radar RobotCar dataset and real-world robot experiments demonstrate that the proposed method can achieve accurate relocalization performance. We show that our approach improves the state-of-the-art MapNet by 69.59% in translation and 75.70% in rotation, and AtLoc by 66.86% in translation and 78.83% in rotation on the challenging outdoor large-scale Oxford Radar RobotCar dataset.