 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtLoc: Attention Guided Camera Localization
Paper and Code

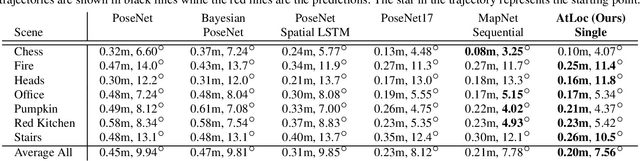
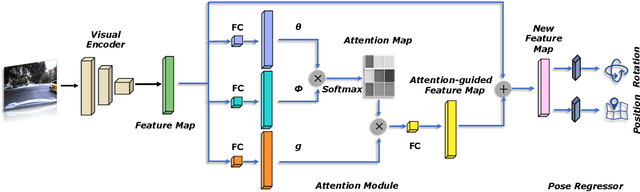
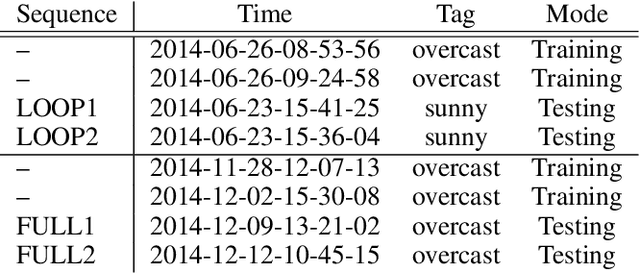
Deep learning has achieved impressive results in camera localization, but current single-image techniques typically suffer from a lack of robustness, leading to large outliers. To some extent, this has been tackled by sequential (multi-images) or geometry constraint approaches, which can learn to reject dynamic objects and illumination conditions to achieve better performance. In this work, we show that attention can be used to force the network to focus on more geometrically robust objects and features, achieving state-of-the-art performance in common benchmark, even if using only a single image as input. Extensive experimental evidence is provided through public indoor and outdoor datasets. Through visualization of the saliency maps, we demonstrate how the network learns to reject dynamic objects, yielding superior global camera pose regression performance. The source code is avaliable at https://github.com/BingCS/AtLoc.