 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Clinical-grade Universal Foundation Model for Intraoperative Pathology
Oct 06, 2025Intraoperative pathology is pivotal to precision surgery, yet its clinical impact is constrained by diagnostic complexity and the limited availability of high-quality frozen-section data. While computational pathology has made significant strides, the lack of large-scale, prospective validation has impeded its routine adoption in surgical workflows. Here, we introduce CRISP, a clinical-grade foundation model developed on over 100,000 frozen sections from eight medical centers, specifically designed to provide Clinical-grade Robust Intraoperative Support for Pathology (CRISP). CRISP was comprehensively evaluated on more than 15,000 intraoperative slides across nearly 100 retrospective diagnostic tasks, including benign-malignant discrimination, key intraoperative decision-making, and pan-cancer detection, etc. The model demonstrated robust generalization across diverse institutions, tumor types, and anatomical sites-including previously unseen sites and rare cancers. In a prospective cohort of over 2,000 patients, CRISP sustained high diagnostic accuracy under real-world conditions, directly informing surgical decisions in 92.6% of cases. Human-AI collaboration further reduced diagnostic workload by 35%, avoided 105 ancillary tests and enhanced detection of micrometastases with 87.5% accuracy. Together, these findings position CRISP as a clinical-grade paradigm for AI-driven intraoperative pathology, bridging computational advances with surgical precision and accelerating the translation of artificial intelligence into routine clinical practice.
HybridNorm: Towards Stable and Efficient Transformer Training via Hybrid Normalization
Mar 06, 2025Transformers have become the de facto architecture for a wide range of machine learning tasks, particularly in large language models (LLMs). Despite their remarkable performance, challenges remain in training deep transformer networks, especially regarding the location of layer normalization. While Pre-Norm structures facilitate easier training due to their more prominent identity path, they often yield suboptimal performance compared to Post-Norm. In this paper, we propose $\textbf{HybridNorm}$, a straightforward yet effective hybrid normalization strategy that integrates the advantages of both Pre-Norm and Post-Norm approaches. Specifically, HybridNorm employs QKV normalization within the attention mechanism and Post-Norm in the feed-forward network (FFN) of each transformer block. This design not only stabilizes training but also enhances performance, particularly in the context of LLMs. Comprehensive experiments in both dense and sparse architectures show that HybridNorm consistently outperforms both Pre-Norm and Post-Norm approaches, achieving state-of-the-art results across various benchmarks. These findings highlight the potential of HybridNorm as a more stable and effective technique for improving the training and performance of deep transformer models. %Code will be made publicly available. Code is available at https://github.com/BryceZhuo/HybridNorm.
Reproducibility Assessment of Magnetic Resonance Spectroscopy of Pregenual Anterior Cingulate Cortex across Sessions and Vendors via the Cloud Computing Platform CloudBrain-MRS
Mar 06, 2025



Given the need to elucidate the mechanisms underlying illnesses and their treatment, as well as the lack of harmonization of acquisition and post-processing protocols among different magnetic resonance system vendors, this work is to determine if metabolite concentrations obtained from different sessions, machine models and even different vendors of 3 T scanners can be highly reproducible and be pooled for diagnostic analysis, which is very valuable for the research of rare diseases. Participants underwent magnetic resonance imaging (MRI) scanning once on two separate days within one week (one session per day, each session including two proton magnetic resonance spectroscopy (1H-MRS) scans with no more than a 5-minute interval between scans (no off-bed activity)) on each machine. were analyzed for reliability of within- and between- sessions using the coefficient of variation (CV) and intraclass correlation coefficient (ICC), and for reproducibility of across the machines using correlation coefficient. As for within- and between- session, all CV values for a group of all the first or second scans of a session, or for a session were almost below 20%, and most of the ICCs for metabolites range from moderate (0.4-0.59) to excellent (0.75-1), indicating high data reliability. When it comes to the reproducibility across the three scanners, all Pearson correlation coefficients across the three machines approached 1 with most around 0.9, and majority demonstrated statistical significance (P<0.01). Additionally, the intra-vendor reproducibility was greater than the inter-vendor ones.
FwNet-ECA: Facilitating Window Attention with Global Receptive Fields through Fourier Filtering Operations
Feb 25, 2025Windowed attention mechanisms were introduced to mitigate the issue of excessive computation inherent in global attention mechanisms. However, In this paper, we present FwNet-ECA, a novel method that utilizes Fourier transforms paired with learnable weight matrices to enhance the spectral features of images. This strategy facilitates inter-window connectivity, thereby maximizing the receptive field. Additionally, we incorporate the Efficient Channel Attention (ECA) module to improve communication between different channels. Instead of relying on physically shifted windows, our approach leverages frequency domain enhancement to implicitly bridge information across spatial regions. We validate our model on the iCartoonFace dataset and conduct downstream tasks on ImageNet, demonstrating that our model achieves lower parameter counts and computational overheads compared to shifted window approaches, while maintaining competitive accuracy. This work offers a more efficient and effective alternative for leveraging attention mechanisms in visual processing tasks, alleviating the challenges associated with windowed attention models. Code is available at https://github.com/qingxiaoli/FwNet-ECA.
Scale-Distribution Decoupling: Enabling Stable and Effective Training of Large Language Models
Feb 21, 2025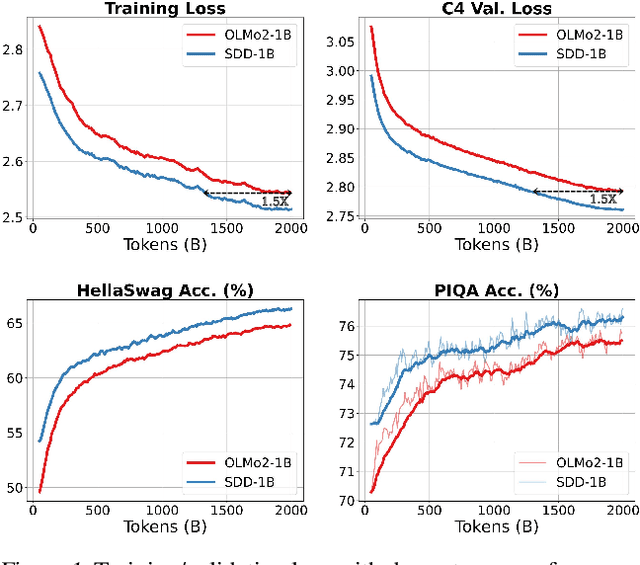
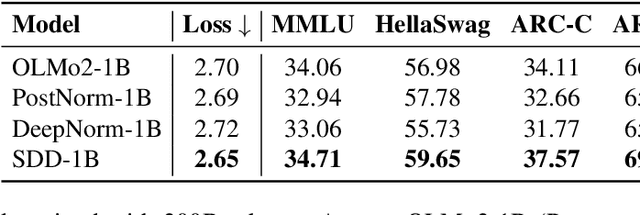
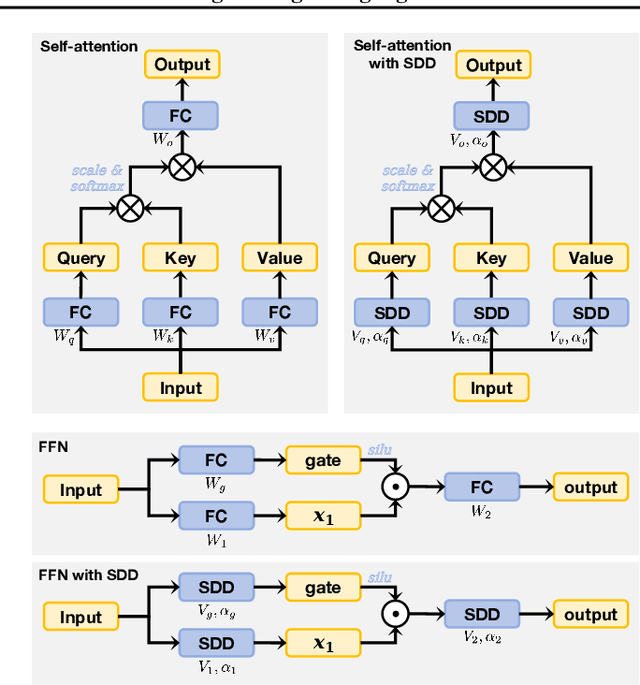
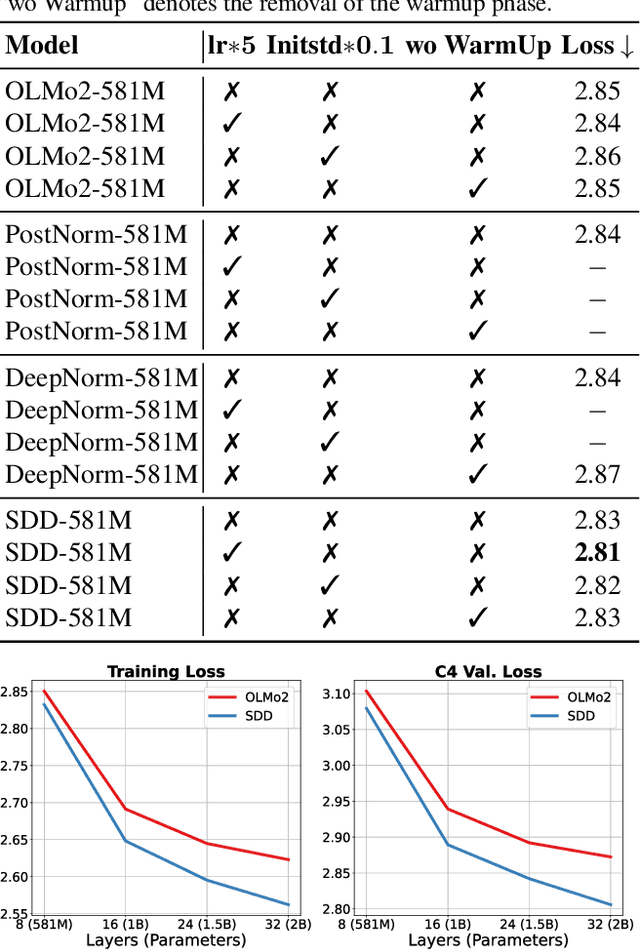
Training stability is a persistent challenge in the pre-training of large language models (LLMs), particularly for architectures such as Post-Norm Transformers, which are prone to gradient explosion and dissipation. In this paper, we propose Scale-Distribution Decoupling (SDD), a novel approach that stabilizes training by explicitly decoupling the scale and distribution of the weight matrix in fully-connected layers. SDD applies a normalization mechanism to regulate activations and a learnable scaling vector to maintain well-conditioned gradients, effectively preventing $\textbf{gradient explosion and dissipation}$. This separation improves optimization efficiency, particularly in deep networks, by ensuring stable gradient propagation. Experimental results demonstrate that our method stabilizes training across various LLM architectures and outperforms existing techniques in different normalization configurations. Furthermore, the proposed method is lightweight and compatible with existing frameworks, making it a practical solution for stabilizing LLM training. Code is available at https://github.com/kaihemo/SDD.
Polynomial Composition Activations: Unleashing the Dynamics of Large Language Models
Nov 06, 2024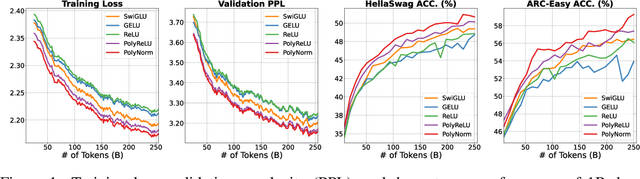
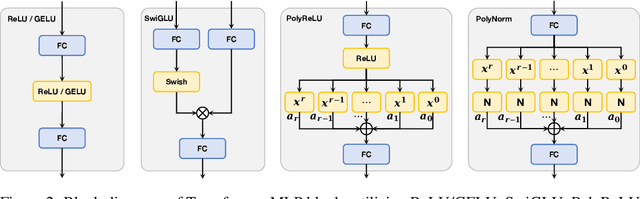

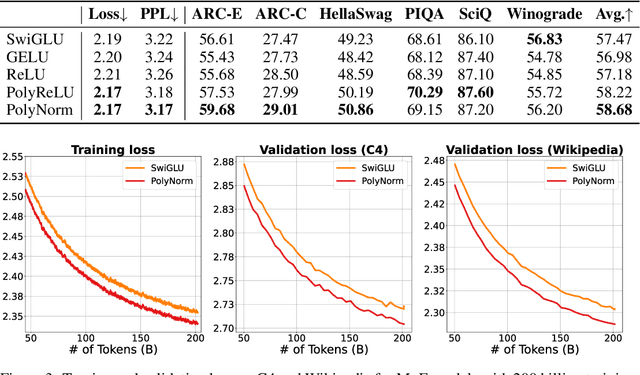
Transformers have found extensive applications across various domains due to the powerful fitting capabilities. This success can be partially attributed to their inherent nonlinearity. Thus, in addition to the ReLU function employed in the original transformer architecture, researchers have explored alternative modules such as GeLU and SwishGLU to enhance nonlinearity and thereby augment representational capacity. In this paper, we propose a novel category of polynomial composition activations (PolyCom), designed to optimize the dynamics of transformers. Theoretically, we provide a comprehensive mathematical analysis of PolyCom, highlighting its enhanced expressivity and efficacy relative to other activation functions. Notably, we demonstrate that networks incorporating PolyCom achieve the $\textbf{optimal approximation rate}$, indicating that PolyCom networks require minimal parameters to approximate general smooth functions in Sobolev spaces. We conduct empirical experiments on the pre-training configurations of large language models (LLMs), including both dense and sparse architectures. By substituting conventional activation functions with PolyCom, we enable LLMs to capture higher-order interactions within the data, thus improving performance metrics in terms of accuracy and convergence rates. Extensive experimental results demonstrate the effectiveness of our method, showing substantial improvements over other activation functions. Code is available at https://github.com/BryceZhuo/PolyCom.
One Sentence One Model for Neural Machine Translation
Sep 21, 2016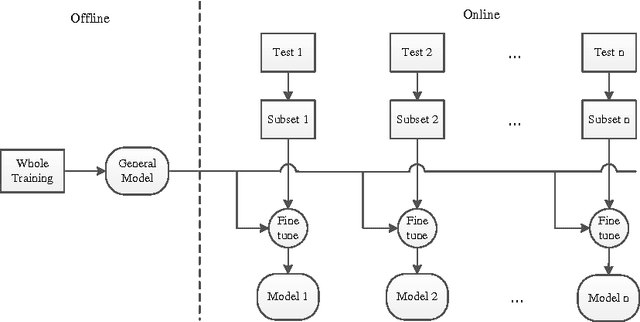

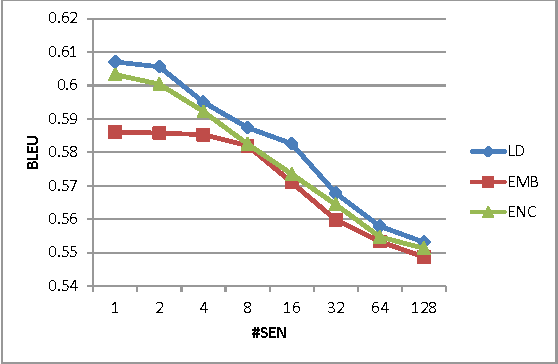

Neural machine translation (NMT) becomes a new state-of-the-art and achieves promising translation results using a simple encoder-decoder neural network. This neural network is trained once on the parallel corpus and the fixed network is used to translate all the test sentences. We argue that the general fixed network cannot best fit the specific test sentences. In this paper, we propose the dynamic NMT which learns a general network as usual, and then fine-tunes the network for each test sentence. The fine-tune work is done on a small set of the bilingual training data that is obtained through similarity search according to the test sentence. Extensive experiments demonstrate that this method can significantly improve the translation performance, especially when highly similar sentences are available.
Neural Name Translation Improves Neural Machine Translation
Jul 07, 2016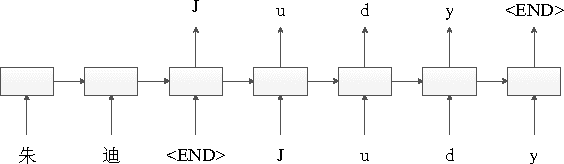
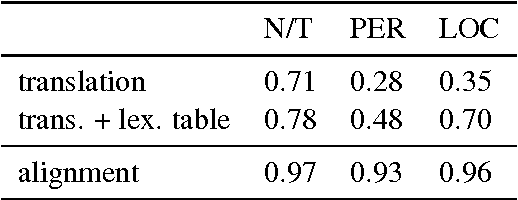
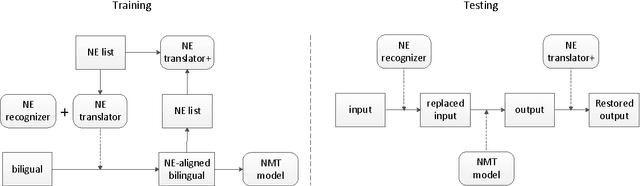
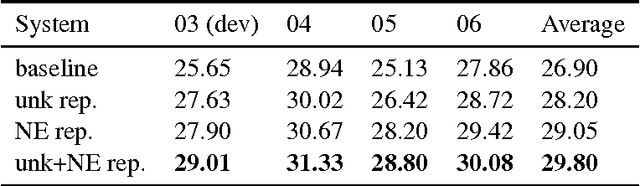
In order to control computational complexity, neural machine translation (NMT) systems convert all rare words outside the vocabulary into a single unk symbol. Previous solution (Luong et al., 2015) resorts to use multiple numbered unks to learn the correspondence between source and target rare words. However, testing words unseen in the training corpus cannot be handled by this method. And it also suffers from the noisy word alignment. In this paper, we focus on a major type of rare words -- named entity (NE), and propose to translate them with character level sequence to sequence model. The NE translation model is further used to derive high quality NE alignment in the bilingual training corpus. With the integration of NE translation and alignment modules, our NMT system is able to surpass the baseline system by 2.9 BLEU points on the Chinese to English task.