 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Name Translation Improves Neural Machine Translation
Paper and Code
Jul 07, 2016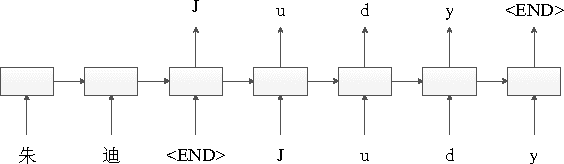
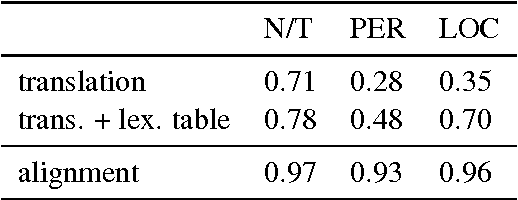
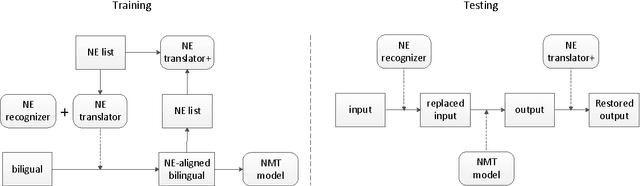
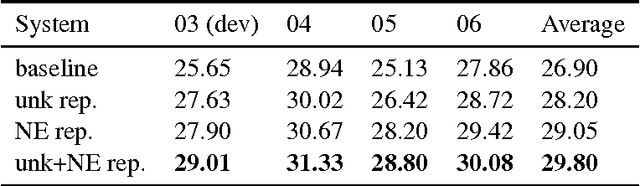
In order to control computational complexity, neural machine translation (NMT) systems convert all rare words outside the vocabulary into a single unk symbol. Previous solution (Luong et al., 2015) resorts to use multiple numbered unks to learn the correspondence between source and target rare words. However, testing words unseen in the training corpus cannot be handled by this method. And it also suffers from the noisy word alignment. In this paper, we focus on a major type of rare words -- named entity (NE), and propose to translate them with character level sequence to sequence model. The NE translation model is further used to derive high quality NE alignment in the bilingual training corpus. With the integration of NE translation and alignment modules, our NMT system is able to surpass the baseline system by 2.9 BLEU points on the Chinese to English task.