 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons Learned: A Multi-Agent Framework for Code LLMs to Learn and Improve
May 29, 2025Recent studies show that LLMs possess different skills and specialize in different tasks. In fact, we observe that their varied performance occur in several levels of granularity. For example, in the code optimization task, code LLMs excel at different optimization categories and no one dominates others. This observation prompts the question of how one leverages multiple LLM agents to solve a coding problem without knowing their complementary strengths a priori. We argue that a team of agents can learn from each other's successes and failures so as to improve their own performance. Thus, a lesson is the knowledge produced by an agent and passed on to other agents in the collective solution process. We propose a lesson-based collaboration framework, design the lesson solicitation--banking--selection mechanism, and demonstrate that a team of small LLMs with lessons learned can outperform a much larger LLM and other multi-LLM collaboration methods.
Identifying Money Laundering Subgraphs on the Blockchain
Oct 10, 2024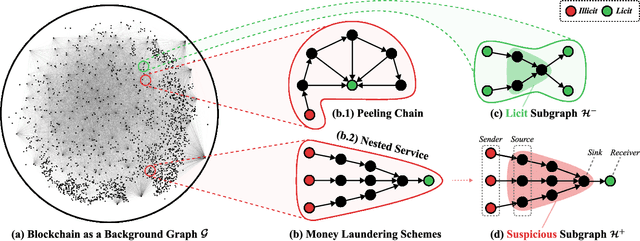
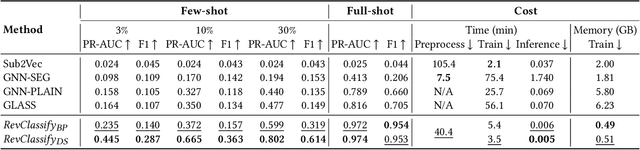
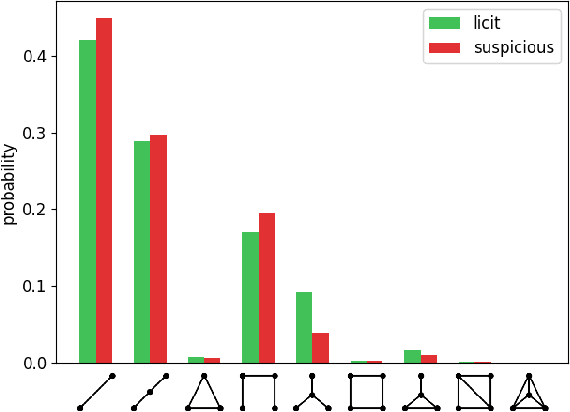

Anti-Money Laundering (AML) involves the identification of money laundering crimes in financial activities, such as cryptocurrency transactions. Recent studies advanced AML through the lens of graph-based machine learning, modeling the web of financial transactions as a graph and developing graph methods to identify suspicious activities. For instance, a recent effort on opensourcing datasets and benchmarks, Elliptic2, treats a set of Bitcoin addresses, considered to be controlled by the same entity, as a graph node and transactions among entities as graph edges. This modeling reveals the "shape" of a money laundering scheme - a subgraph on the blockchain. Despite the attractive subgraph classification results benchmarked by the paper, competitive methods remain expensive to apply due to the massive size of the graph; moreover, existing methods require candidate subgraphs as inputs which may not be available in practice. In this work, we introduce RevTrack, a graph-based framework that enables large-scale AML analysis with a lower cost and a higher accuracy. The key idea is to track the initial senders and the final receivers of funds; these entities offer a strong indication of the nature (licit vs. suspicious) of their respective subgraph. Based on this framework, we propose RevClassify, which is a neural network model for subgraph classification. Additionally, we address the practical problem where subgraph candidates are not given, by proposing RevFilter. This method identifies new suspicious subgraphs by iteratively filtering licit transactions, using RevClassify. Benchmarking these methods on Elliptic2, a new standard for AML, we show that RevClassify outperforms state-of-the-art subgraph classification techniques in both cost and accuracy. Furthermore, we demonstrate the effectiveness of RevFilter in discovering new suspicious subgraphs, confirming its utility for practical AML.
RISC-V Toolchain and Agile Development based Open-source Neuromorphic Processor
Oct 06, 2022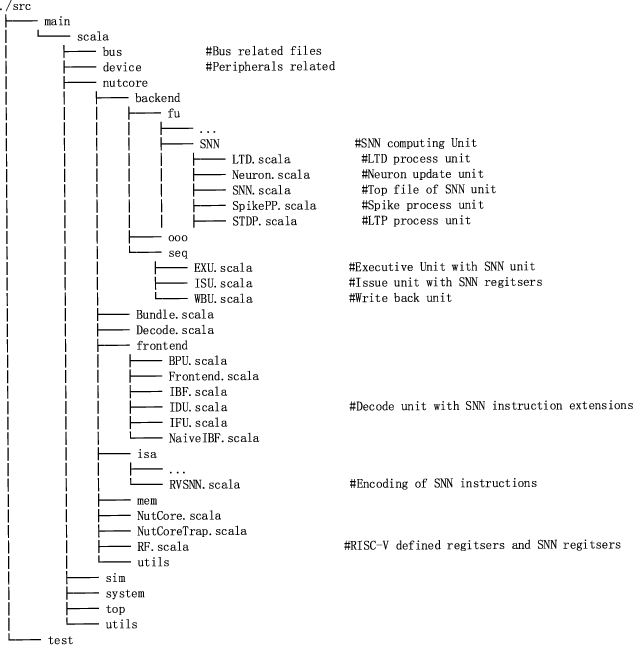

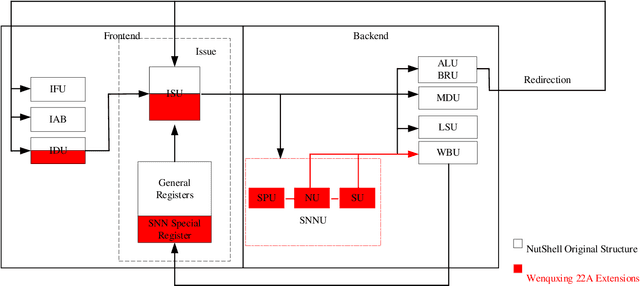
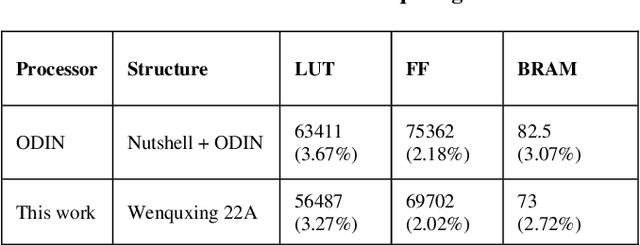
In recent decades, neuromorphic computing aiming to imitate brains' behaviors has been developed in various fields of computer science. The Artificial Neural Network (ANN) is an important concept in Artificial Intelligence (AI). It is utilized in recognition and classification. To explore a better way to simulate obtained brain behaviors, which is fast and energy-efficient, on hardware, researchers need an advanced method such as neuromorphic computing. In this case, Spiking Neural Network (SNN) becomes an optimal choice in hardware implementation. Recent works are focusing on accelerating SNN computing. However, most accelerator solutions are based on CPU-accelerator architecture which is energy-inefficient due to the complex control flows in this structure. This paper proposes Wenquxing 22A, a low-power neuromorphic processor that combines general-purpose CPU functions and SNN to efficiently compute it with RISC-V SNN extension instructions. The main idea of Wenquxing 22A is to integrate the SNN calculation unit into the pipeline of a general-purpose CPU to achieve low-power computing with customized RISC-V SNN instructions version 1.0 (RV-SNN V1.0), Streamlined Leaky Integrate-and-Fire (LIF) model, and the binary stochastic Spike-timing-dependent-plasticity (STDP). The source code of Wenquxing 22A is released online on Gitee and GitHub. We apply Wenquxing 22A to the recognition of the MNIST dataset to make a comparison with other SNN systems. Our experiment results show that Wenquxing 22A improves the energy expenses by 5.13 times over the accelerator solution, ODIN, with approximately classification accuracy, 85.00% for 3-bit ODIN online learning, and 91.91% for 1-bit Wenquxing 22A.
Escort: Efficient Sparse Convolutional Neural Networks on GPUs
Feb 28, 2018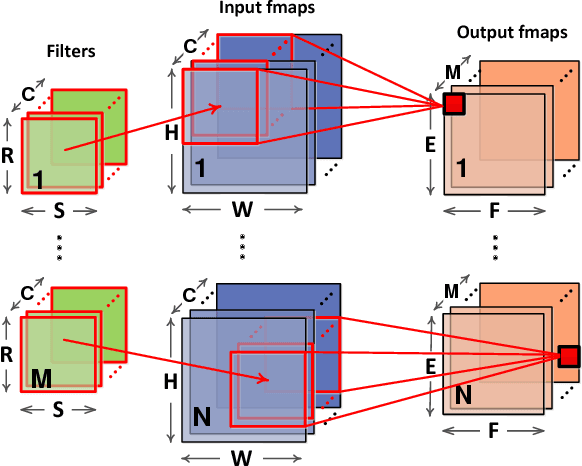

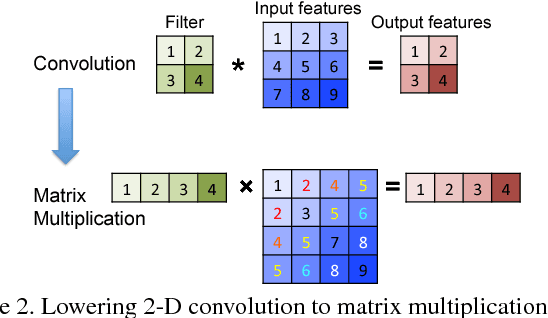

Deep neural networks have achieved remarkable accuracy in many artificial intelligence applications, e.g. computer vision, at the cost of a large number of parameters and high computational complexity. Weight pruning can compress DNN models by removing redundant parameters in the networks, but it brings sparsity in the weight matrix, and therefore makes the computation inefficient on GPUs. Although pruning can remove more than 80% of the weights, it actually hurts inference performance (speed) when running models on GPUs. Two major problems cause this unsatisfactory performance on GPUs. First, lowering convolution onto matrix multiplication reduces data reuse opportunities and wastes memory bandwidth. Second, the sparsity brought by pruning makes the computation irregular, which leads to inefficiency when running on massively parallel GPUs. To overcome these two limitations, we propose Escort, an efficient sparse convolutional neural networks on GPUs. Instead of using the lowering method, we choose to compute the sparse convolutions directly. We then orchestrate the parallelism and locality for the direct sparse convolution kernel, and apply customized optimization techniques to further improve performance. Evaluation on NVIDIA GPUs show that Escort can improve sparse convolution speed by 2.63x and 3.07x, and inference speed by 1.38x and 1.60x, compared to CUBLAS and CUSPARSE respectively.