 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiPhishGuard: An LLM-based Multi-Agent System for Phishing Email Detection
May 26, 2025



Phishing email detection faces critical challenges from evolving adversarial tactics and heterogeneous attack patterns. Traditional detection methods, such as rule-based filters and denylists, often struggle to keep pace with these evolving tactics, leading to false negatives and compromised security. While machine learning approaches have improved detection accuracy, they still face challenges adapting to novel phishing strategies. We present MultiPhishGuard, a dynamic LLM-based multi-agent detection system that synergizes specialized expertise with adversarial-aware reinforcement learning. Our framework employs five cooperative agents (text, URL, metadata, explanation simplifier, and adversarial agents) with automatically adjusted decision weights powered by a Proximal Policy Optimization reinforcement learning algorithm. To address emerging threats, we introduce an adversarial training loop featuring an adversarial agent that generates subtle context-aware email variants, creating a self-improving defense ecosystem and enhancing system robustness. Experimental evaluations on public datasets demonstrate that MultiPhishGuard significantly outperforms Chain-of-Thoughts, single-agent baselines and state-of-the-art detectors, as validated by ablation studies and comparative analyses. Experiments demonstrate that MultiPhishGuard achieves high accuracy (97.89\%) with low false positive (2.73\%) and false negative rates (0.20\%). Additionally, we incorporate an explanation simplifier agent, which provides users with clear and easily understandable explanations for why an email is classified as phishing or legitimate. This work advances phishing defense through dynamic multi-agent collaboration and generative adversarial resilience.
RAGent: Retrieval-based Access Control Policy Generation
Sep 08, 2024

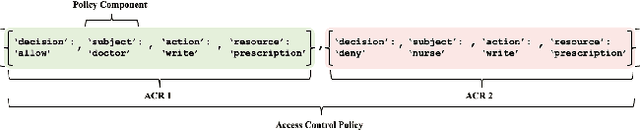

Manually generating access control policies from an organization's high-level requirement specifications poses significant challenges. It requires laborious efforts to sift through multiple documents containing such specifications and translate their access requirements into access control policies. Also, the complexities and ambiguities of these specifications often result in errors by system administrators during the translation process, leading to data breaches. However, the automated policy generation frameworks designed to help administrators in this process are unreliable due to limitations, such as the lack of domain adaptation. Therefore, to improve the reliability of access control policy generation, we propose RAGent, a novel retrieval-based access control policy generation framework based on language models. RAGent identifies access requirements from high-level requirement specifications with an average state-of-the-art F1 score of 87.9%. Through retrieval augmented generation, RAGent then translates the identified access requirements into access control policies with an F1 score of 77.9%. Unlike existing frameworks, RAGent generates policies with complex components like purposes and conditions, in addition to subjects, actions, and resources. Moreover, RAGent automatically verifies the generated policies and iteratively refines them through a novel verification-refinement mechanism, further improving the reliability of the process by 3%, reaching the F1 score of 80.6%. We also introduce three annotated datasets for developing access control policy generation frameworks in the future, addressing the data scarcity of the domain.
No Vandalism: Privacy-Preserving and Byzantine-Robust Federated Learning
Jun 03, 2024



Federated learning allows several clients to train one machine learning model jointly without sharing private data, providing privacy protection. However, traditional federated learning is vulnerable to poisoning attacks, which can not only decrease the model performance, but also implant malicious backdoors. In addition, direct submission of local model parameters can also lead to the privacy leakage of the training dataset. In this paper, we aim to build a privacy-preserving and Byzantine-robust federated learning scheme to provide an environment with no vandalism (NoV) against attacks from malicious participants. Specifically, we construct a model filter for poisoned local models, protecting the global model from data and model poisoning attacks. This model filter combines zero-knowledge proofs to provide further privacy protection. Then, we adopt secret sharing to provide verifiable secure aggregation, removing malicious clients that disrupting the aggregation process. Our formal analysis proves that NoV can protect data privacy and weed out Byzantine attackers. Our experiments illustrate that NoV can effectively address data and model poisoning attacks, including PGD, and outperforms other related schemes.
Zero-knowledge Proof Meets Machine Learning in Verifiability: A Survey
Oct 23, 2023With the rapid advancement of artificial intelligence technology, the usage of machine learning models is gradually becoming part of our daily lives. High-quality models rely not only on efficient optimization algorithms but also on the training and learning processes built upon vast amounts of data and computational power. However, in practice, due to various challenges such as limited computational resources and data privacy concerns, users in need of models often cannot train machine learning models locally. This has led them to explore alternative approaches such as outsourced learning and federated learning. While these methods address the feasibility of model training effectively, they introduce concerns about the trustworthiness of the training process since computations are not performed locally. Similarly, there are trustworthiness issues associated with outsourced model inference. These two problems can be summarized as the trustworthiness problem of model computations: How can one verify that the results computed by other participants are derived according to the specified algorithm, model, and input data? To address this challenge, verifiable machine learning (VML) has emerged. This paper presents a comprehensive survey of zero-knowledge proof-based verifiable machine learning (ZKP-VML) technology. We first analyze the potential verifiability issues that may exist in different machine learning scenarios. Subsequently, we provide a formal definition of ZKP-VML. We then conduct a detailed analysis and classification of existing works based on their technical approaches. Finally, we discuss the key challenges and future directions in the field of ZKP-based VML.
SoK: Access Control Policy Generation from High-level Natural Language Requirements
Oct 05, 2023



Administrator-centered access control failures can cause data breaches, putting organizations at risk of financial loss and reputation damage. Existing graphical policy configuration tools and automated policy generation frameworks attempt to help administrators configure and generate access control policies by avoiding such failures. However, graphical policy configuration tools are prone to human errors, making them unusable. On the other hand, automated policy generation frameworks are prone to erroneous predictions, making them unreliable. Therefore, to find ways to improve their usability and reliability, we conducted a Systematic Literature Review analyzing 49 publications, to identify those tools, frameworks, and their limitations. Identifying those limitations will help develop effective access control policy generation solutions while avoiding access control failures.