 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualHints: A Visual-Lingual Environment for Multimodal Reinforcement Learning
Paper and Code
Oct 26, 2020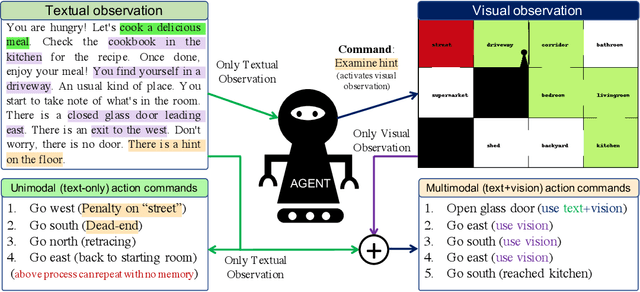
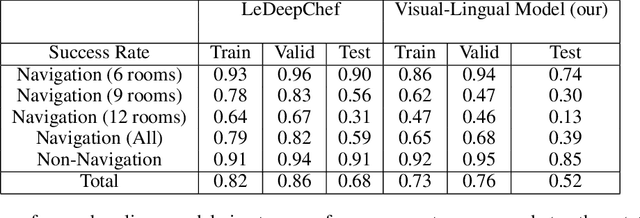
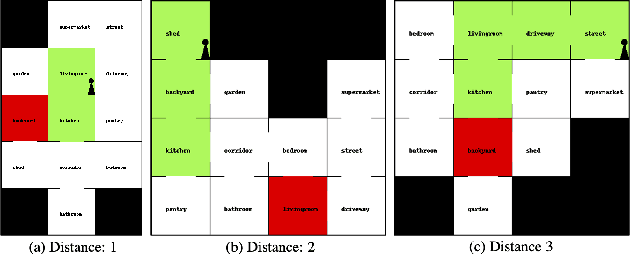

We present VisualHints, a novel environment for multimodal reinforcement learning (RL) involving text-based interactions along with visual hints (obtained from the environment). Real-life problems often demand that agents interact with the environment using both natural language information and visual perception towards solving a goal. However, most traditional RL environments either solve pure vision-based tasks like Atari games or video-based robotic manipulation; or entirely use natural language as a mode of interaction, like Text-based games and dialog systems. In this work, we aim to bridge this gap and unify these two approaches in a single environment for multimodal RL. We introduce an extension of the TextWorld cooking environment with the addition of visual clues interspersed throughout the environment. The goal is to force an RL agent to use both text and visual features to predict natural language action commands for solving the final task of cooking a meal. We enable variations and difficulties in our environment to emulate various interactive real-world scenarios. We present a baseline multimodal agent for solving such problems using CNN-based feature extraction from visual hints and LSTMs for textual feature extraction. We believe that our proposed visual-lingual environment will facilitate novel problem settings for the RL community.