 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatching of Descriptive Labels to Glossary Descriptions
Oct 27, 2023



Semantic text similarity plays an important role in software engineering tasks in which engineers are requested to clarify the semantics of descriptive labels (e.g., business terms, table column names) that are often consists of too short or too generic words and appears in their IT systems. We formulate this type of problem as a task of matching descriptive labels to glossary descriptions. We then propose a framework to leverage an existing semantic text similarity measurement (STS) and augment it using semantic label enrichment and set-based collective contextualization where the former is a method to retrieve sentences relevant to a given label and the latter is a method to compute similarity between two contexts each of which is derived from a set of texts (e.g., column names in the same table). We performed an experiment on two datasets derived from publicly available data sources. The result indicated that the proposed methods helped the underlying STS correctly match more descriptive labels with the descriptions.
Exploring Graph Neural Networks for Stock Market Predictions with Rolling Window Analysis
Sep 29, 2019
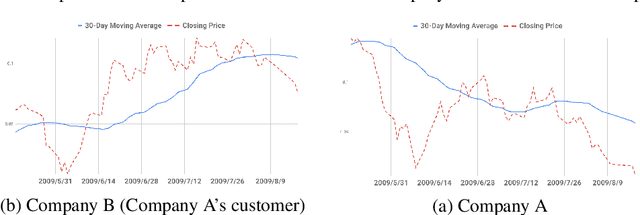

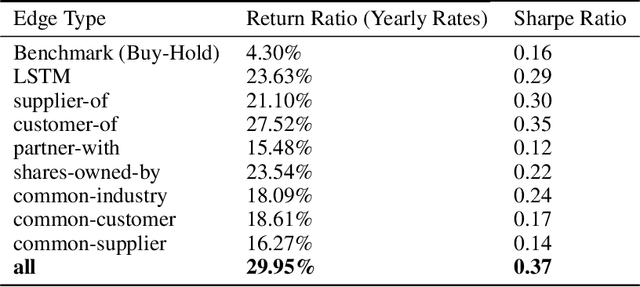
Recently, there has been a surge of interest in the use of machine learning to help aid in the accurate predictions of financial markets. Despite the exciting advances in this cross-section of finance and AI, many of the current approaches are limited to using technical analysis to capture historical trends of each stock price and thus limited to certain experimental setups to obtain good prediction results. On the other hand, professional investors additionally use their rich knowledge of inter-market and inter-company relations to map the connectivity of companies and events, and use this map to make better market predictions. For instance, they would predict the movement of a certain company's stock price based not only on its former stock price trends but also on the performance of its suppliers or customers, the overall industry, macroeconomic factors and trade policies. This paper investigates the effectiveness of work at the intersection of market predictions and graph neural networks, which hold the potential to mimic the ways in which investors make decisions by incorporating company knowledge graphs directly into the predictive model. The main goal of this work is to test the validity of this approach across different markets and longer time horizons for backtesting using rolling window analysis. In this work, we concentrate on the prediction of individual stock prices in the Japanese Nikkei 225 market over a period of roughly 20 years. For the knowledge graph, we use the Nikkei Value Search data, which is a rich dataset showing mainly supplier relations among Japanese and foreign companies. Our preliminary results show a 29.5% increase and a 2.2-fold increase in the return ratio and Sharpe ratio, respectively, when compared to the market benchmark, as well as a 6.32% increase and 1.3-fold increase, respectively, compared to the baseline LSTM model.
Real-time tree search with pessimistic scenarios
Feb 28, 2019

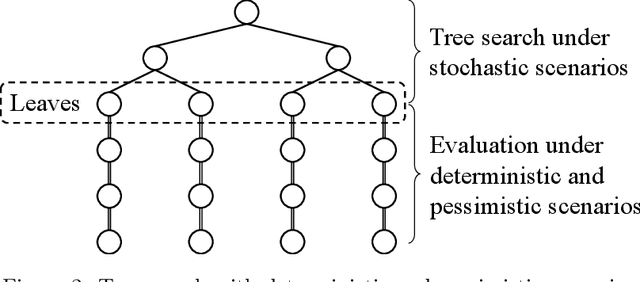

Autonomous agents need to make decisions in a sequential manner, under partially observable environment, and in consideration of how other agents behave. In critical situations, such decisions need to be made in real time for example to avoid collisions and recover to safe conditions. We propose a technique of tree search where a deterministic and pessimistic scenario is used after a specified depth. Because there is no branching with the deterministic scenario, the proposed technique allows us to take into account far ahead in the future in real time. The effectiveness of the proposed technique is demonstrated in Pommerman, a multi-agent environment used in a NeurIPS 2018 competition, where the agents that implement the proposed technique have won the first and third places.