 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeB+ANN: A Fast Billion-Scale Disk-based Nearest-Neighbor Index
Nov 19, 2025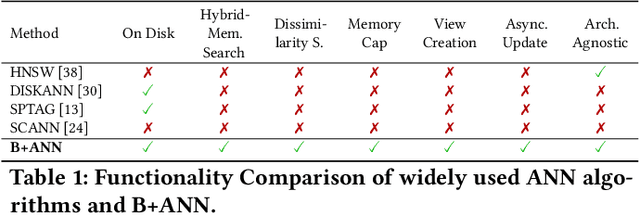



Storing and processing of embedding vectors by specialized Vector databases (VDBs) has become the linchpin in building modern AI pipelines. Most current VDBs employ variants of a graph-based ap- proximate nearest-neighbor (ANN) index algorithm, HNSW, to an- swer semantic queries over stored vectors. Inspite of its wide-spread use, the HNSW algorithm suffers from several issues: in-memory design and implementation, random memory accesses leading to degradation in cache behavior, limited acceleration scope due to fine-grained pairwise computations, and support of only semantic similarity queries. In this paper, we present a novel disk-based ANN index, B+ANN, to address these issues: it first partitions input data into blocks containing semantically similar items, then builds an B+ tree variant to store blocks both in-memory and on disks, and finally, enables hybrid edge- and block-based in-memory traversals. As demonstrated by our experimantal evaluation, the proposed B+ANN disk-based index improves both quality (Recall value), and execution performance (Queries per second/QPS) over HNSW, by improving spatial and temporal locality for semantic operations, reducing cache misses (19.23% relative gain), and decreasing the memory consumption and disk-based build time by 24x over the DiskANN algorithm. Finally, it enables dissimilarity queries, which are not supported by similarity-oriented ANN indices.
A Scalable Space-efficient In-database Interpretability Framework for Embedding-based Semantic SQL Queries
Mar 01, 2023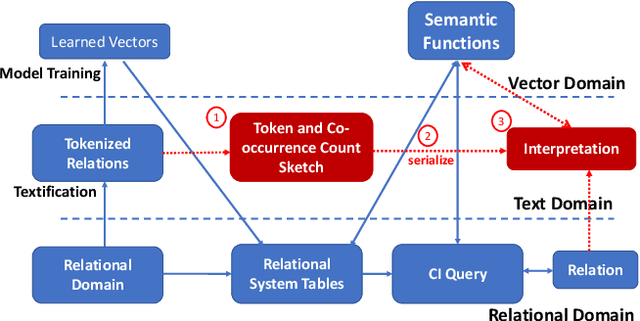
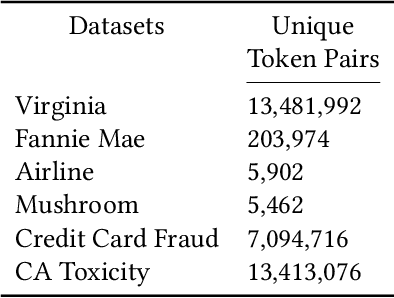
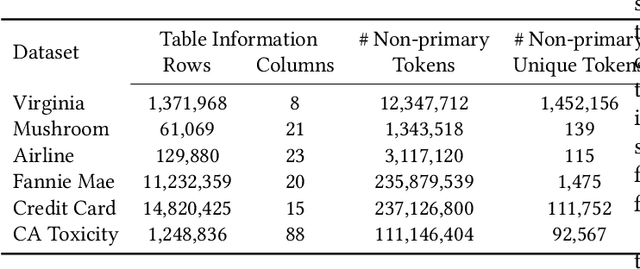
AI-Powered database (AI-DB) is a novel relational database system that uses a self-supervised neural network, database embedding, to enable semantic SQL queries on relational tables. In this paper, we describe an architecture and implementation of in-database interpretability infrastructure designed to provide simple, transparent, and relatable insights into ranked results of semantic SQL queries supported by AI-DB. We introduce a new co-occurrence based interpretability approach to capture relationships between relational entities and describe a space-efficient probabilistic Sketch implementation to store and process co-occurrence counts. Our approach provides both query-agnostic (global) and query-specific (local) interpretabilities. Experimental evaluation demonstrate that our in-database probabilistic approach provides the same interpretability quality as the precise space-inefficient approach, while providing scalable and space efficient runtime behavior (up to 8X space savings), without any user intervention.
EFloat: Entropy-coded Floating Point Format for Deep Learning
Feb 04, 2021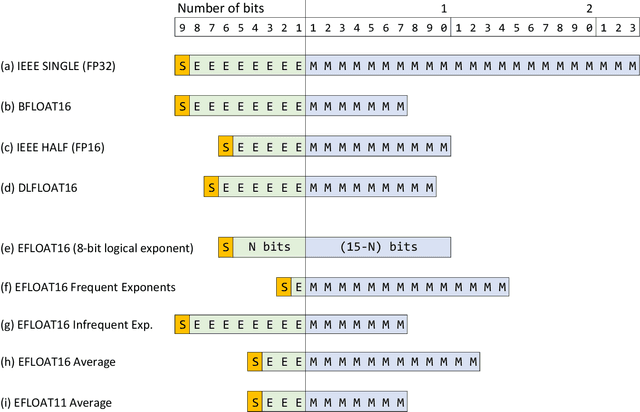
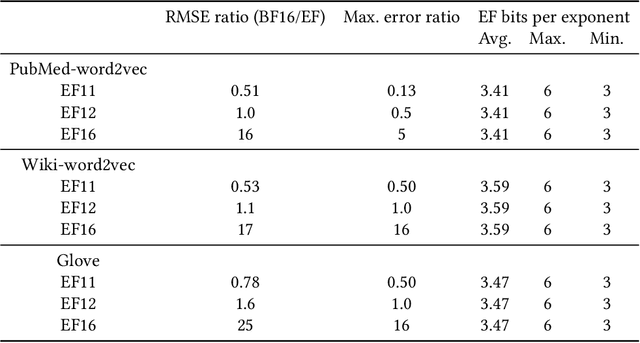
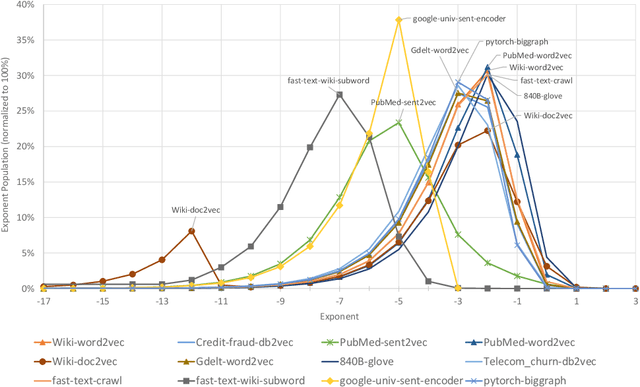
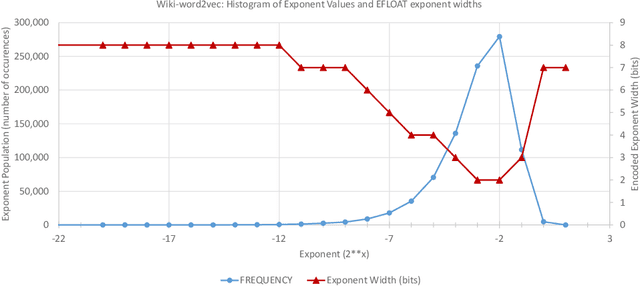
We describe the EFloat floating-point number format with 4 to 6 additional bits of precision and a wider exponent range than the existing floating point (FP) formats of any width including FP32, BFloat16, IEEE-Half precision, DLFloat, TensorFloat, and 8-bit floats. In a large class of deep learning models we observe that FP exponent values tend to cluster around few unique values which presents entropy encoding opportunities. The EFloat format encodes frequent exponent values and signs with Huffman codes to minimize the average exponent field width. Saved bits then become available to the mantissa increasing the EFloat numeric precision on average by 4 to 6 bits compared to other FP formats of equal width. The proposed encoding concept may be beneficial to low-precision formats including 8-bit floats. Training deep learning models with low precision arithmetic is challenging. EFloat, with its increased precision may provide an opportunity for those tasks as well. We currently use the EFloat format for compressing and saving memory used in large NLP deep learning models. A potential hardware implementation for improving PCIe and memory bandwidth limitations of AI accelerators is also discussed.
Unlocking New York City Crime Insights using Relational Database Embeddings
May 20, 2020
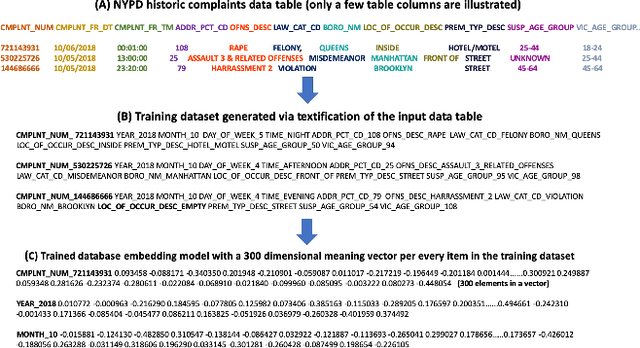


This paper demonstrates the use of the AI-Powered Database (AI-DB) in identifying non-obvious patterns in crime data that could serve as an aid to predictive policing measures. AI-DB uses an unsupervised neural network, db2Vec, to capture inter and intra-column semantic relationships from a relational table and allows users to exploit such relationships using novel semantic SQL queries. Using the publicly available New York Police Department (NYPD) Crime Complaint Dataset as an example, the paper illustrates how AI-DB can be used to interpret the data and generate useful insights. We demonstrate that AI-DB's database embedding model and semantic queries enable users to identify criminal complaint patterns that are not possible to extract using current crime analysis tools, including NYPD's state-of-the-art Patternizr system. We show that the AI-DB system can generate new insights with reduced pre-processing and execution costs (e.g., no labeling, reduced feature engineering, and use of standard SQL queries) with reasonable training performance (i.e., processing and training the 6.5 Million crime complaints in the NYPD Crime Complaint Dataset took less than 4 hours). The SQL-based implementation can be incorporated into any data science pipeline to provide visual representation of the results.
Cognitive Database: A Step towards Endowing Relational Databases with Artificial Intelligence Capabilities
Dec 19, 2017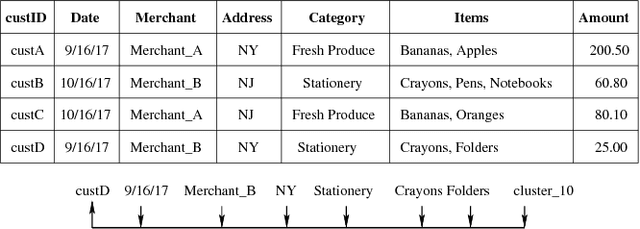
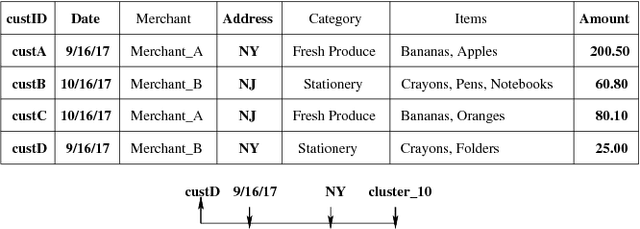
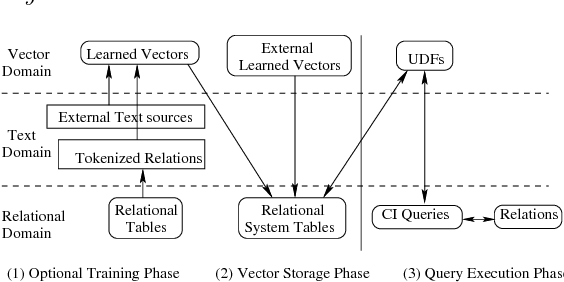
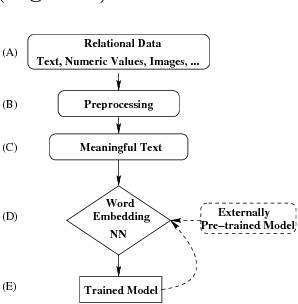
We propose Cognitive Databases, an approach for transparently enabling Artificial Intelligence (AI) capabilities in relational databases. A novel aspect of our design is to first view the structured data source as meaningful unstructured text, and then use the text to build an unsupervised neural network model using a Natural Language Processing (NLP) technique called word embedding. This model captures the hidden inter-/intra-column relationships between database tokens of different types. For each database token, the model includes a vector that encodes contextual semantic relationships. We seamlessly integrate the word embedding model into existing SQL query infrastructure and use it to enable a new class of SQL-based analytics queries called cognitive intelligence (CI) queries. CI queries use the model vectors to enable complex queries such as semantic matching, inductive reasoning queries such as analogies, predictive queries using entities not present in a database, and, more generally, using knowledge from external sources. We demonstrate unique capabilities of Cognitive Databases using an Apache Spark based prototype to execute inductive reasoning CI queries over a multi-modal database containing text and images. We believe our first-of-a-kind system exemplifies using AI functionality to endow relational databases with capabilities that were previously very hard to realize in practice.
Enabling Cognitive Intelligence Queries in Relational Databases using Low-dimensional Word Embeddings
Mar 23, 2016
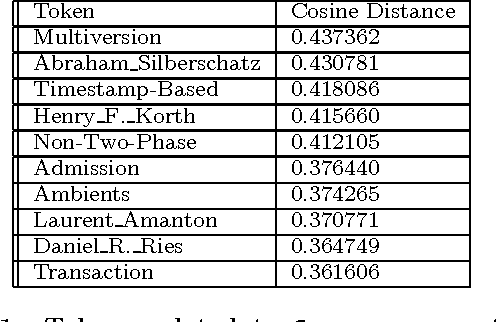


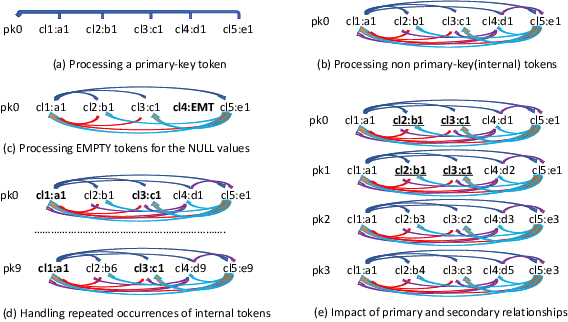
We apply distributed language embedding methods from Natural Language Processing to assign a vector to each database entity associated token (for example, a token may be a word occurring in a table row, or the name of a column). These vectors, of typical dimension 200, capture the meaning of tokens based on the contexts in which the tokens appear together. To form vectors, we apply a learning method to a token sequence derived from the database. We describe various techniques for extracting token sequences from a database. The techniques differ in complexity, in the token sequences they output and in the database information used (e.g., foreign keys). The vectors can be used to algebraically quantify semantic relationships between the tokens such as similarities and analogies. Vectors enable a dual view of the data: relational and (meaningful rather than purely syntactical) text. We introduce and explore a new class of queries called cognitive intelligence (CI) queries that extract information from the database based, in part, on the relationships encoded by vectors. We have implemented a prototype system on top of Spark to exhibit the power of CI queries. Here, CI queries are realized via SQL UDFs. This power goes far beyond text extensions to relational systems due to the information encoded in vectors. We also consider various extensions to the basic scheme, including using a collection of views derived from the database to focus on a domain of interest, utilizing vectors and/or text from external sources, maintaining vectors as the database evolves and exploring a database without utilizing its schema. For the latter, we consider minimal extensions to SQL to vastly improve query expressiveness.