 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeML Based Lineage in Databases
Sep 13, 2021



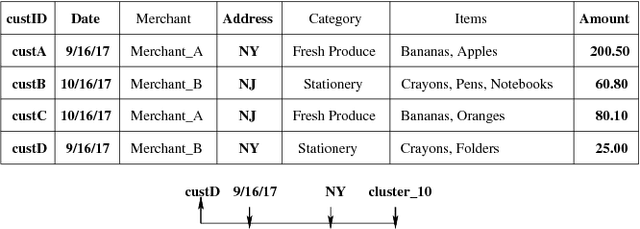
In this work, we track the lineage of tuples throughout their database lifetime. That is, we consider a scenario in which tuples (records) that are produced by a query may affect other tuple insertions into the DB, as part of a normal workflow. As time goes on, exact provenance explanations for such tuples become deeply nested, increasingly consuming space, and resulting in decreased clarity and readability. We present a novel approach for approximating lineage tracking, using a Machine Learning (ML) and Natural Language Processing (NLP) technique; namely, word embedding. The basic idea is summarizing (and approximating) the lineage of each tuple via a small set of constant-size vectors (the number of vectors per-tuple is a hyperparameter). Therefore, our solution does not suffer from space complexity blow-up over time, and it "naturally ranks" explanations to the existence of a tuple. We devise an alternative and improved lineage tracking mechanism, that of keeping track of and querying lineage at the column level; thereby, we manage to better distinguish between the provenance features and the textual characteristics of a tuple. We integrate our lineage computations into the PostgreSQL system via an extension (ProvSQL) and experimentally exhibit useful results in terms of accuracy against exact, semiring-based, justifications. In the experiments, we focus on tuples with multiple generations of tuples in their lifelong lineage and analyze them in terms of direct and distant lineage. The experiments suggest a high usefulness potential for the proposed approximate lineage methods and the further suggested enhancements. This especially holds for the column-based vectors method which exhibits high precision and high per-level recall.
Efficient Set of Vectors Search
Jul 14, 2021
We consider a similarity measure between two sets $A$ and $B$ of vectors, that balances the average and maximum cosine distance between pairs of vectors, one from set $A$ and one from set $B$. As a motivation for this measure, we present lineage tracking in a database. To practically realize this measure, we need an approximate search algorithm that given a set of vectors $A$ and sets of vectors $B_1,...,B_n$, the algorithm quickly locates the set $B_i$ that maximizes the similarity measure. For the case where all sets are singleton sets, essentially each is a single vector, there are known efficient approximate search algorithms, e.g., approximated versions of tree search algorithms, locality-sensitive hashing (LSH), vector quantization (VQ) and proximity graph algorithms. In this work, we present approximate search algorithms for the general case. The underlying idea in these algorithms is encoding a set of vectors via a "long" single vector.
NN-based Transformation of Any SQL Cardinality Estimator for Handling DISTINCT, AND, OR and NOT
Apr 15, 2020
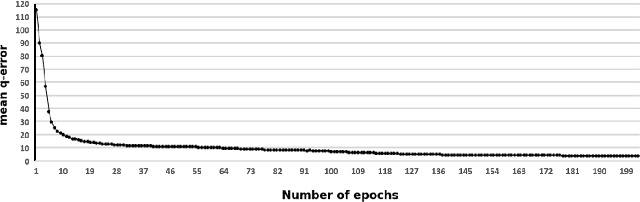

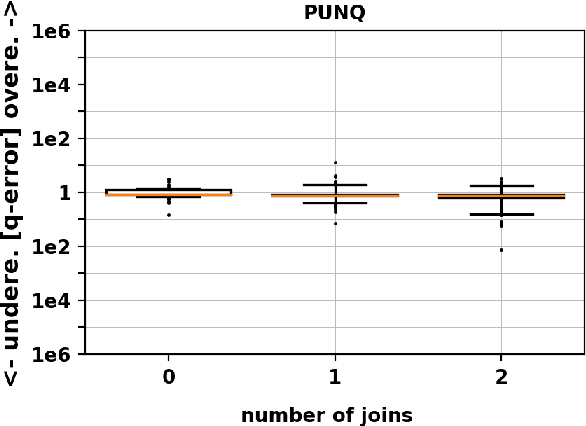
SQL queries, with the AND, OR, and NOT operators, constitute a broad class of highly used queries. Thus, their cardinality estimation is important for query optimization. In addition, a query planner requires the set-theoretic cardinality (i.e., without duplicates) for queries with DISTINCT as well as in planning; for example, when considering sorting options. Yet, despite the importance of estimating query cardinalities in the presence of DISTINCT, AND, OR, and NOT, many cardinality estimation methods are limited to estimating cardinalities of only conjunctive queries with duplicates counted. The focus of this work is on two methods for handling this deficiency that can be applied to any limited cardinality estimation model. First, we describe a specialized deep learning scheme, PUNQ, which is tailored to representing conjunctive SQL queries and predicting the percentage of unique rows in the query's result with duplicate rows. Using the predicted percentages obtained via PUNQ, we are able to transform any cardinality estimation method that only estimates for conjunctive queries, and which estimates cardinalities with duplicates (e.g., MSCN), to a method that estimates queries cardinalities without duplicates. This enables estimating cardinalities of queries with the DISTINCT keyword. In addition, we describe a recursive algorithm, GenCrd, for extending any cardinality estimation method M that only handles conjunctive queries to one that estimates cardinalities for more general queries (that include AND, OR, and NOT), without changing the method M itself. Our evaluation is carried out on a challenging, real-world database with general queries that include either the DISTINCT keyword or the AND, OR, and NOT operators. Experimentally, we show that the proposed methods obtain accurate cardinality estimates with the same level of accuracy as that of the original transformed methods.
Improved Cardinality Estimation by Learning Queries Containment Rates
Aug 21, 2019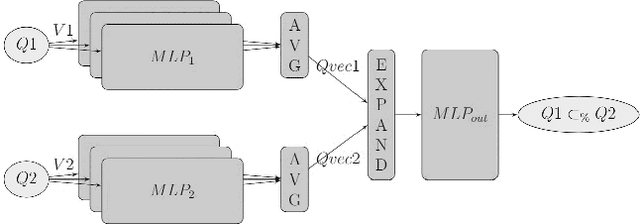


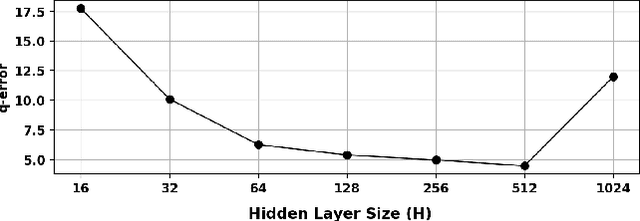
The containment rate of query Q1 in query Q2 over database D is the percentage of Q1's result tuples over D that are also in Q2's result over D. We directly estimate containment rates between pairs of queries over a specific database. For this, we use a specialized deep learning scheme, CRN, which is tailored to representing pairs of SQL queries. Result-cardinality estimation is a core component of query optimization. We describe a novel approach for estimating queries result-cardinalities using estimated containment rates among queries. This containment rate estimation may rely on CRN or embed, unchanged, known cardinality estimation methods. Experimentally, our novel approach for estimating cardinalities, using containment rates between queries, on a challenging real-world database, realizes significant improvements to state of the art cardinality estimation methods.
Cognitive Database: A Step towards Endowing Relational Databases with Artificial Intelligence Capabilities
Dec 19, 2017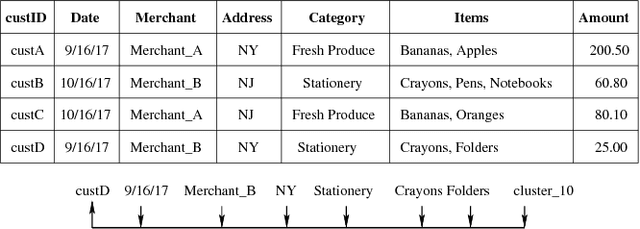
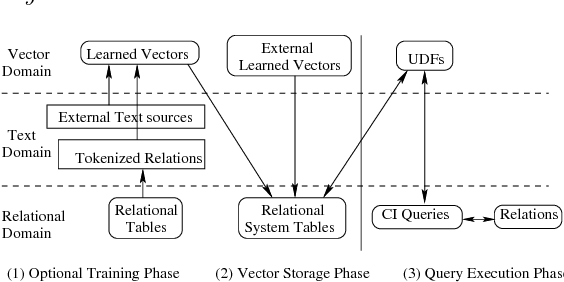
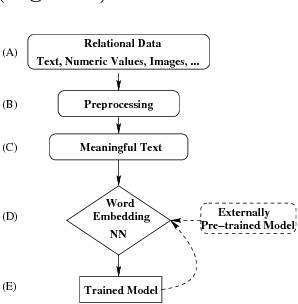
We propose Cognitive Databases, an approach for transparently enabling Artificial Intelligence (AI) capabilities in relational databases. A novel aspect of our design is to first view the structured data source as meaningful unstructured text, and then use the text to build an unsupervised neural network model using a Natural Language Processing (NLP) technique called word embedding. This model captures the hidden inter-/intra-column relationships between database tokens of different types. For each database token, the model includes a vector that encodes contextual semantic relationships. We seamlessly integrate the word embedding model into existing SQL query infrastructure and use it to enable a new class of SQL-based analytics queries called cognitive intelligence (CI) queries. CI queries use the model vectors to enable complex queries such as semantic matching, inductive reasoning queries such as analogies, predictive queries using entities not present in a database, and, more generally, using knowledge from external sources. We demonstrate unique capabilities of Cognitive Databases using an Apache Spark based prototype to execute inductive reasoning CI queries over a multi-modal database containing text and images. We believe our first-of-a-kind system exemplifies using AI functionality to endow relational databases with capabilities that were previously very hard to realize in practice.
Enabling Cognitive Intelligence Queries in Relational Databases using Low-dimensional Word Embeddings
Mar 23, 2016
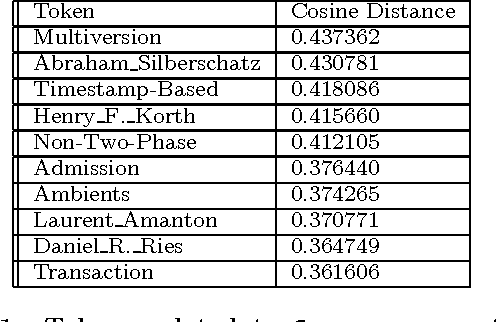


We apply distributed language embedding methods from Natural Language Processing to assign a vector to each database entity associated token (for example, a token may be a word occurring in a table row, or the name of a column). These vectors, of typical dimension 200, capture the meaning of tokens based on the contexts in which the tokens appear together. To form vectors, we apply a learning method to a token sequence derived from the database. We describe various techniques for extracting token sequences from a database. The techniques differ in complexity, in the token sequences they output and in the database information used (e.g., foreign keys). The vectors can be used to algebraically quantify semantic relationships between the tokens such as similarities and analogies. Vectors enable a dual view of the data: relational and (meaningful rather than purely syntactical) text. We introduce and explore a new class of queries called cognitive intelligence (CI) queries that extract information from the database based, in part, on the relationships encoded by vectors. We have implemented a prototype system on top of Spark to exhibit the power of CI queries. Here, CI queries are realized via SQL UDFs. This power goes far beyond text extensions to relational systems due to the information encoded in vectors. We also consider various extensions to the basic scheme, including using a collection of views derived from the database to focus on a domain of interest, utilizing vectors and/or text from external sources, maintaining vectors as the database evolves and exploring a database without utilizing its schema. For the latter, we consider minimal extensions to SQL to vastly improve query expressiveness.