 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Code generation for Information Technology Tasks in YAML through Large Language Models
May 05, 2023



The recent improvement in code generation capabilities due to the use of large language models has mainly benefited general purpose programming languages. Domain specific languages, such as the ones used for IT Automation, have received far less attention, despite involving many active developers and being an essential component of modern cloud platforms. This work focuses on the generation of Ansible-YAML, a widely used markup language for IT Automation. We present Ansible Wisdom, a natural-language to Ansible-YAML code generation tool, aimed at improving IT automation productivity. Ansible Wisdom is a transformer-based model, extended by training with a new dataset containing Ansible-YAML. We also develop two novel performance metrics for YAML and Ansible to capture the specific characteristics of this domain. Results show that Ansible Wisdom can accurately generate Ansible script from natural language prompts with performance comparable or better than existing state of the art code generation models.
D2A: A Dataset Built for AI-Based Vulnerability Detection Methods Using Differential Analysis
Feb 16, 2021
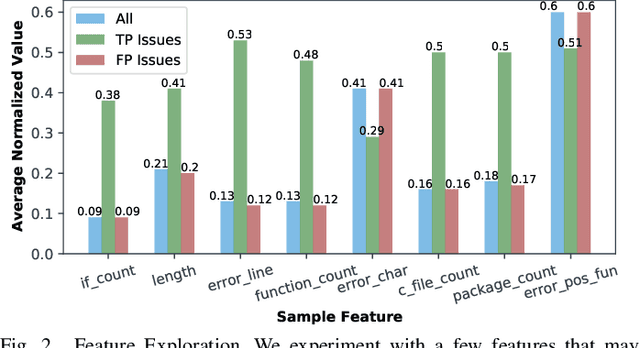


Static analysis tools are widely used for vulnerability detection as they understand programs with complex behavior and millions of lines of code. Despite their popularity, static analysis tools are known to generate an excess of false positives. The recent ability of Machine Learning models to understand programming languages opens new possibilities when applied to static analysis. However, existing datasets to train models for vulnerability identification suffer from multiple limitations such as limited bug context, limited size, and synthetic and unrealistic source code. We propose D2A, a differential analysis based approach to label issues reported by static analysis tools. The D2A dataset is built by analyzing version pairs from multiple open source projects. From each project, we select bug fixing commits and we run static analysis on the versions before and after such commits. If some issues detected in a before-commit version disappear in the corresponding after-commit version, they are very likely to be real bugs that got fixed by the commit. We use D2A to generate a large labeled dataset to train models for vulnerability identification. We show that the dataset can be used to build a classifier to identify possible false alarms among the issues reported by static analysis, hence helping developers prioritize and investigate potential true positives first.