 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Processing Unit (QPU) processing time Prediction with Machine Learning
Oct 23, 2025This paper explores the application of machine learning (ML) techniques in predicting the QPU processing time of quantum jobs. By leveraging ML algorithms, this study introduces predictive models that are designed to enhance operational efficiency in quantum computing systems. Using a dataset of about 150,000 jobs that follow the IBM Quantum schema, we employ ML methods based on Gradient-Boosting (LightGBM) to predict the QPU processing times, incorporating data preprocessing methods to improve model accuracy. The results demonstrate the effectiveness of ML in forecasting quantum jobs. This improvement can have implications on improving resource management and scheduling within quantum computing frameworks. This research not only highlights the potential of ML in refining quantum job predictions but also sets a foundation for integrating AI-driven tools in advanced quantum computing operations.
AI Methods for Permutation Circuit Synthesis Across Generic Topologies
Sep 19, 2025This paper investigates artificial intelligence (AI) methodologies for the synthesis and transpilation of permutation circuits across generic topologies. Our approach uses Reinforcement Learning (RL) techniques to achieve near-optimal synthesis of permutation circuits up to 25 qubits. Rather than developing specialized models for individual topologies, we train a foundational model on a generic rectangular lattice, and employ masking mechanisms to dynamically select subsets of topologies during the synthesis. This enables the synthesis of permutation circuits on any topology that can be embedded within the rectangular lattice, without the need to re-train the model. In this paper we show results for 5x5 lattice and compare them to previous AI topology-oriented models and classical methods, showing that they outperform classical heuristics, and match previous specialized AI models, and performs synthesis even for topologies that were not seen during training. We further show that the model can be fine tuned to strengthen the performance for selected topologies of interest. This methodology allows a single trained model to efficiently synthesize circuits across diverse topologies, allowing its practical integration into transpilation workflows.
Quantum Verifiable Rewards for Post-Training Qiskit Code Assistant
Aug 28, 2025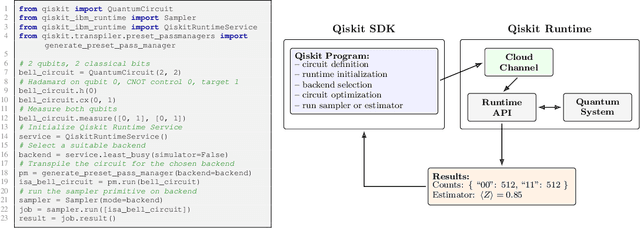

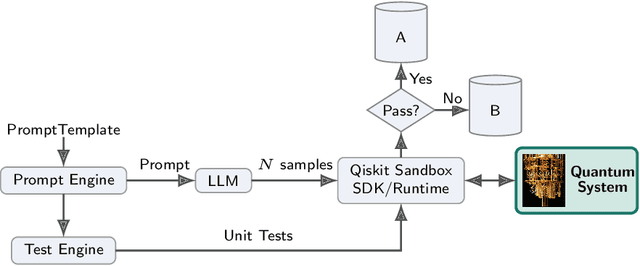

Qiskit is an open-source quantum computing framework that allows users to design, simulate, and run quantum circuits on real quantum hardware. We explore post-training techniques for LLMs to assist in writing Qiskit code. We introduce quantum verification as an effective method for ensuring code quality and executability on quantum hardware. To support this, we developed a synthetic data pipeline that generates quantum problem-unit test pairs and used it to create preference data for aligning LLMs with DPO. Additionally, we trained models using GRPO, leveraging quantum-verifiable rewards provided by the quantum hardware. Our best-performing model, combining DPO and GRPO, surpasses the strongest open-source baselines on the challenging Qiskit-HumanEval-hard benchmark.
AI methods for approximate compiling of unitaries
Jul 30, 2024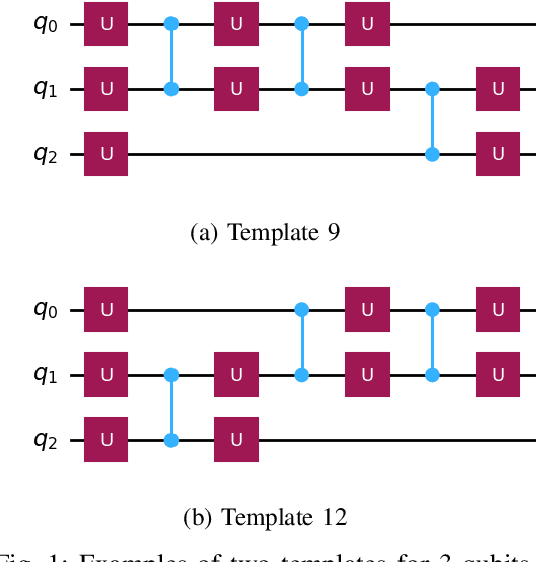
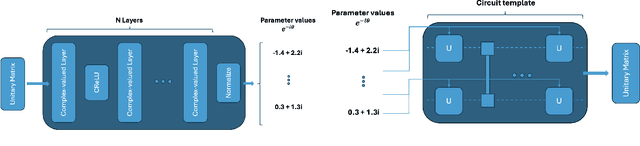
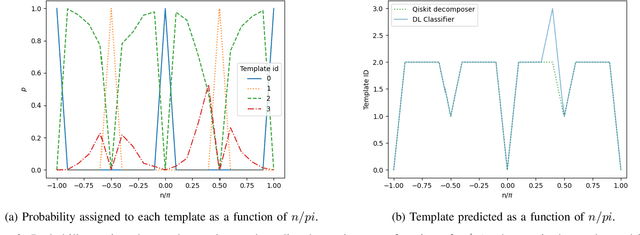
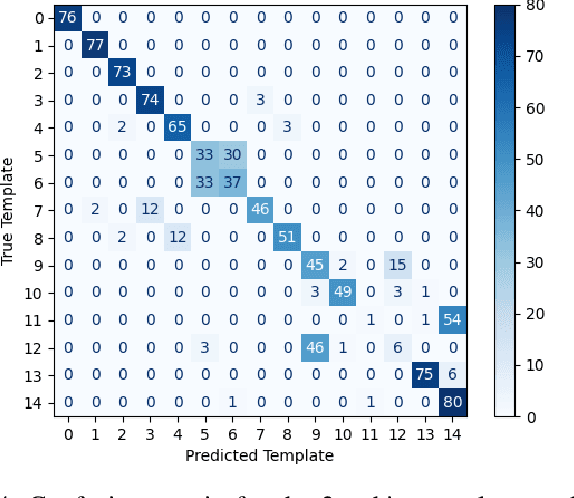
This paper explores artificial intelligence (AI) methods for the approximate compiling of unitaries, focusing on the use of fixed two-qubit gates and arbitrary single-qubit rotations typical in superconducting hardware. Our approach involves three main stages: identifying an initial template that approximates the target unitary, predicting initial parameters for this template, and refining these parameters to maximize the fidelity of the circuit. We propose AI-driven approaches for the first two stages, with a deep learning model that suggests initial templates and an autoencoder-like model that suggests parameter values, which are refined through gradient descent to achieve the desired fidelity. We demonstrate the method on 2 and 3-qubit unitaries, showcasing promising improvements over exhaustive search and random parameter initialization. The results highlight the potential of AI to enhance the transpiling process, supporting more efficient quantum computations on current and future quantum hardware.
Qiskit HumanEval: An Evaluation Benchmark For Quantum Code Generative Models
Jun 20, 2024Quantum programs are typically developed using quantum Software Development Kits (SDKs). The rapid advancement of quantum computing necessitates new tools to streamline this development process, and one such tool could be Generative Artificial intelligence (GenAI). In this study, we introduce and use the Qiskit HumanEval dataset, a hand-curated collection of tasks designed to benchmark the ability of Large Language Models (LLMs) to produce quantum code using Qiskit - a quantum SDK. This dataset consists of more than 100 quantum computing tasks, each accompanied by a prompt, a canonical solution, a comprehensive test case, and a difficulty scale to evaluate the correctness of the generated solutions. We systematically assess the performance of a set of LLMs against the Qiskit HumanEval dataset's tasks and focus on the models ability in producing executable quantum code. Our findings not only demonstrate the feasibility of using LLMs for generating quantum code but also establish a new benchmark for ongoing advancements in the field and encourage further exploration and development of GenAI-driven tools for quantum code generation.
Qiskit Code Assistant: Training LLMs for generating Quantum Computing Code
May 29, 2024
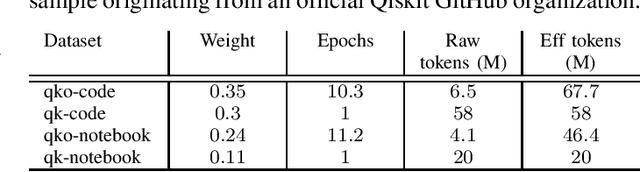
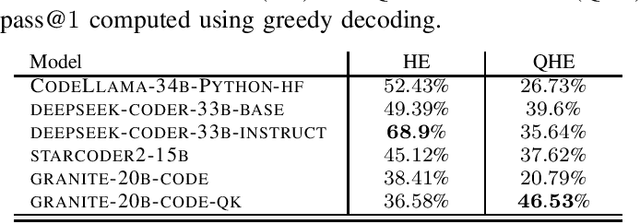
Code Large Language Models (Code LLMs) have emerged as powerful tools, revolutionizing the software development landscape by automating the coding process and reducing time and effort required to build applications. This paper focuses on training Code LLMs to specialize in the field of quantum computing. We begin by discussing the unique needs of quantum computing programming, which differ significantly from classical programming approaches or languages. A Code LLM specializing in quantum computing requires a foundational understanding of quantum computing and quantum information theory. However, the scarcity of available quantum code examples and the rapidly evolving field, which necessitates continuous dataset updates, present significant challenges. Moreover, we discuss our work on training Code LLMs to produce high-quality quantum code using the Qiskit library. This work includes an examination of the various aspects of the LLMs used for training and the specific training conditions, as well as the results obtained with our current models. To evaluate our models, we have developed a custom benchmark, similar to HumanEval, which includes a set of tests specifically designed for the field of quantum computing programming using Qiskit. Our findings indicate that our model outperforms existing state-of-the-art models in quantum computing tasks. We also provide examples of code suggestions, comparing our model to other relevant code LLMs. Finally, we introduce a discussion on the potential benefits of Code LLMs for quantum computing computational scientists, researchers, and practitioners. We also explore various features and future work that could be relevant in this context.
Practical and efficient quantum circuit synthesis and transpiling with Reinforcement Learning
May 21, 2024This paper demonstrates the integration of Reinforcement Learning (RL) into quantum transpiling workflows, significantly enhancing the synthesis and routing of quantum circuits. By employing RL, we achieve near-optimal synthesis of Linear Function, Clifford, and Permutation circuits, up to 9, 11 and 65 qubits respectively, while being compatible with native device instruction sets and connectivity constraints, and orders of magnitude faster than optimization methods such as SAT solvers. We also achieve significant reductions in two-qubit gate depth and count for circuit routing up to 133 qubits with respect to other routing heuristics such as SABRE. We find the method to be efficient enough to be useful in practice in typical quantum transpiling pipelines. Our results set the stage for further AI-powered enhancements of quantum computing workflows.
Automated Source Code Generation and Auto-completion Using Deep Learning: Comparing and Discussing Current Language-Model-Related Approaches
Sep 16, 2020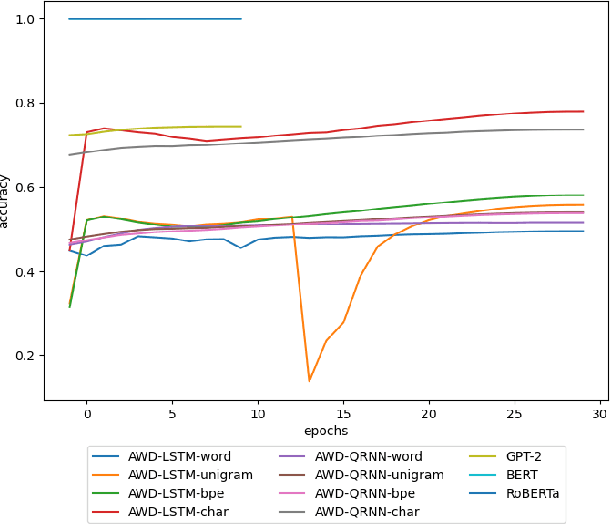
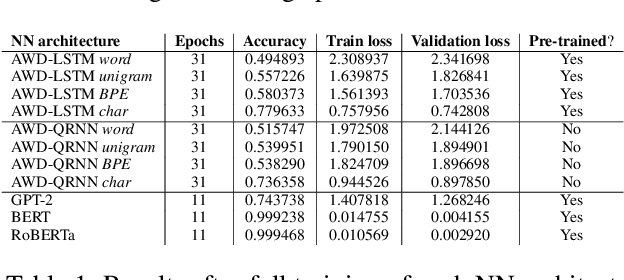
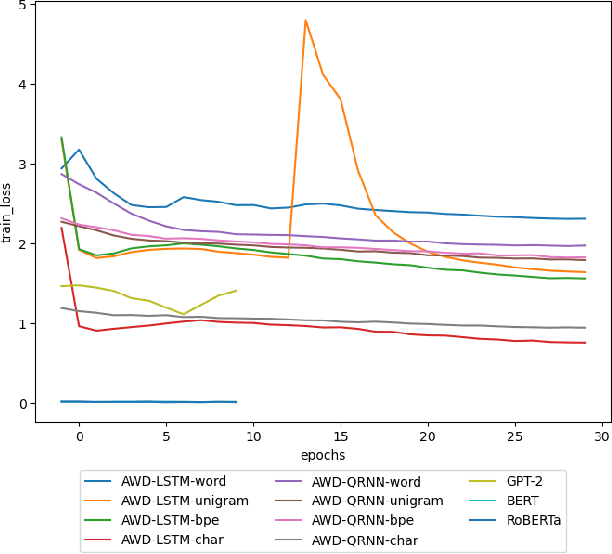
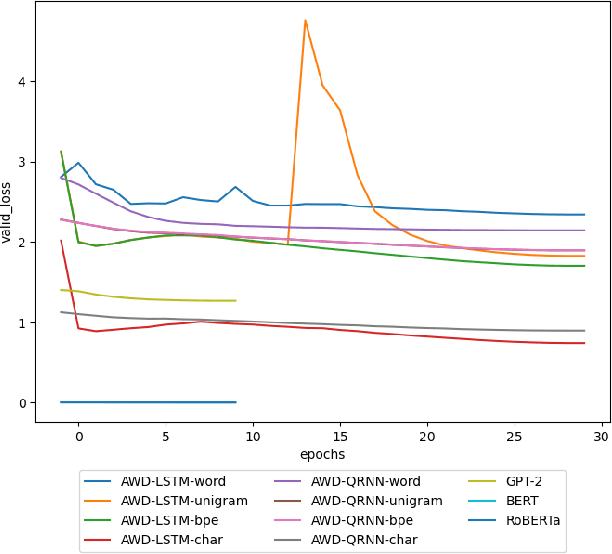
In recent years, the use of deep learning in language models, text auto-completion, and text generation has made tremendous progress and gained much attention from the research community. Some products and research projects claim that they can generate text that can be interpreted as human-writing, enabling new possibilities in many application areas. Among the different areas related to language processing, one of the most notable in applying this type of modeling is the processing of programming languages. For years, the Machine Learning community has been researching in this Big Code area, pursuing goals like applying different approaches to auto-complete generate, fix, or evaluate code programmed by humans. One of the approaches followed in recent years to pursue these goals is the use of Deep-Learning-enabled language models. Considering the increasing popularity of that approach, we detected a lack of empirical papers that compare different methods and deep learning architectures to create and use language models based on programming code. In this paper, we compare different neural network (NN) architectures like AWD-LSTMs, AWD-QRNNs, and Transformer, while using transfer learning, and different tokenizations to see how they behave in building language models using a Python dataset for code generation and filling mask tasks. Considering the results, we discuss the different strengths and weaknesses of each approach and technique and what lacks do we find to evaluate the language models or apply them in a real programming context while including humans-in-the-loop.