 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Source Code Generation and Auto-completion Using Deep Learning: Comparing and Discussing Current Language-Model-Related Approaches
Paper and Code
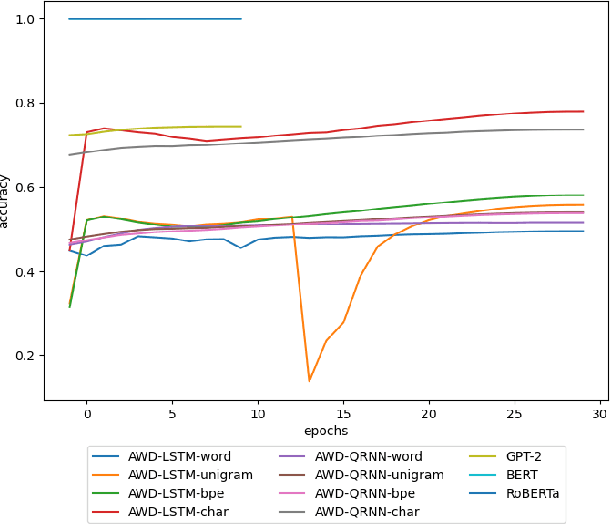
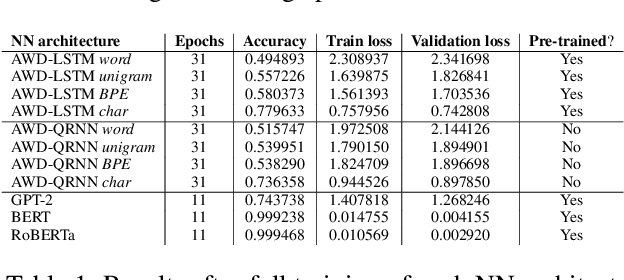
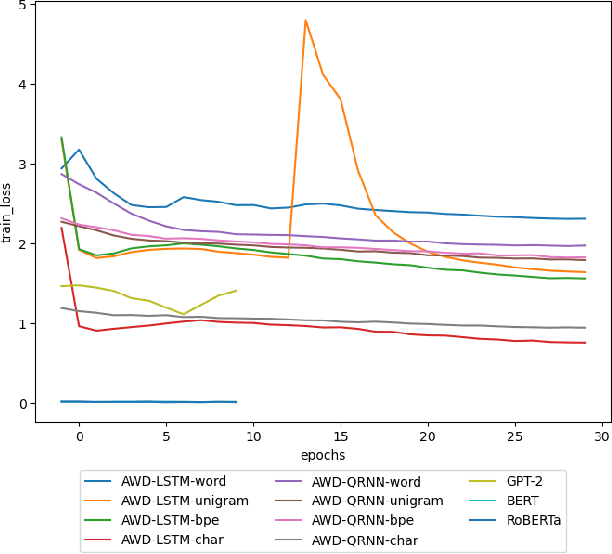
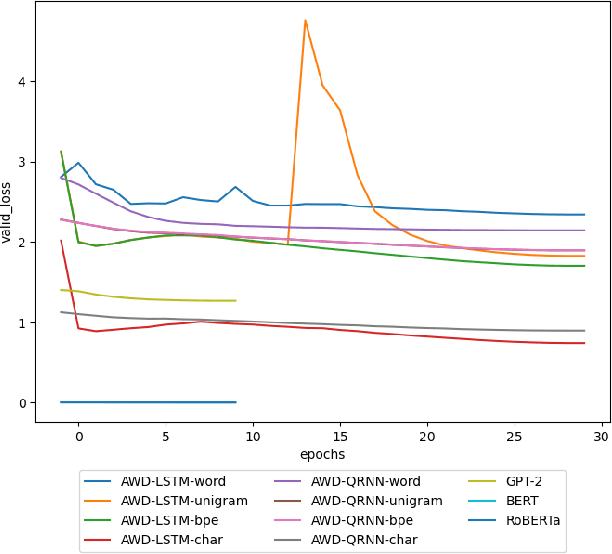
In recent years, the use of deep learning in language models, text auto-completion, and text generation has made tremendous progress and gained much attention from the research community. Some products and research projects claim that they can generate text that can be interpreted as human-writing, enabling new possibilities in many application areas. Among the different areas related to language processing, one of the most notable in applying this type of modeling is the processing of programming languages. For years, the Machine Learning community has been researching in this Big Code area, pursuing goals like applying different approaches to auto-complete generate, fix, or evaluate code programmed by humans. One of the approaches followed in recent years to pursue these goals is the use of Deep-Learning-enabled language models. Considering the increasing popularity of that approach, we detected a lack of empirical papers that compare different methods and deep learning architectures to create and use language models based on programming code. In this paper, we compare different neural network (NN) architectures like AWD-LSTMs, AWD-QRNNs, and Transformer, while using transfer learning, and different tokenizations to see how they behave in building language models using a Python dataset for code generation and filling mask tasks. Considering the results, we discuss the different strengths and weaknesses of each approach and technique and what lacks do we find to evaluate the language models or apply them in a real programming context while including humans-in-the-loop.