 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Efficient and Statistical Quality Estimation for Data Annotation
May 20, 2024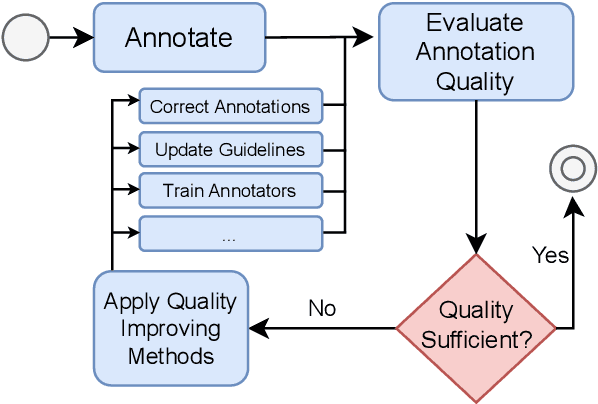
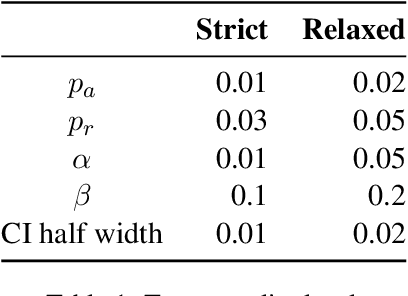
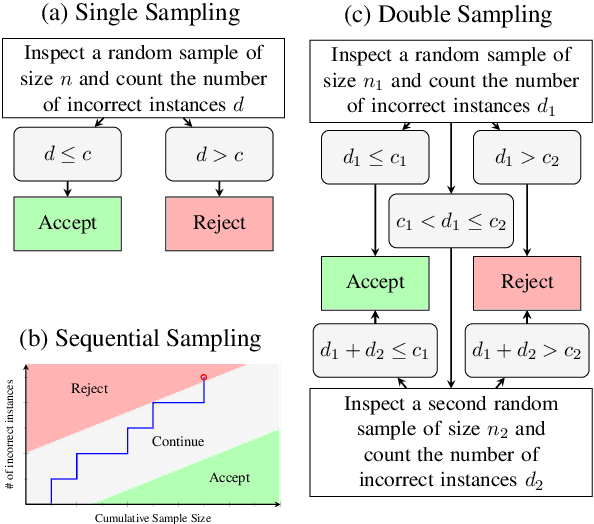
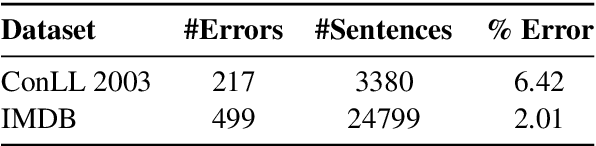
Annotated datasets are an essential ingredient to train, evaluate, compare and productionalize supervised machine learning models. It is therefore imperative that annotations are of high quality. For their creation, good quality management and thereby reliable quality estimates are needed. Then, if quality is insufficient during the annotation process, rectifying measures can be taken to improve it. Quality estimation is often performed by having experts manually label instances as correct or incorrect. But checking all annotated instances tends to be expensive. Therefore, in practice, usually only subsets are inspected; sizes are chosen mostly without justification or regard to statistical power and more often than not, are relatively small. Basing estimates on small sample sizes, however, can lead to imprecise values for the error rate. Using unnecessarily large sample sizes costs money that could be better spent, for instance on more annotations. Therefore, we first describe in detail how to use confidence intervals for finding the minimal sample size needed to estimate the annotation error rate. Then, we propose applying acceptance sampling as an alternative to error rate estimation We show that acceptance sampling can reduce the required sample sizes up to 50% while providing the same statistical guarantees.
Neo: Generalizing Confusion Matrix Visualization to Hierarchical and Multi-Output Labels
Oct 24, 2021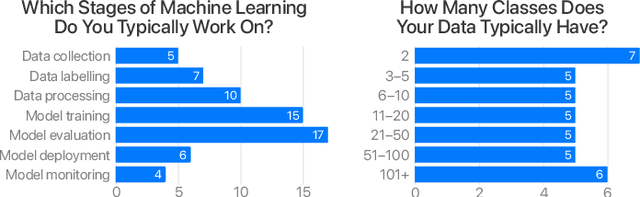

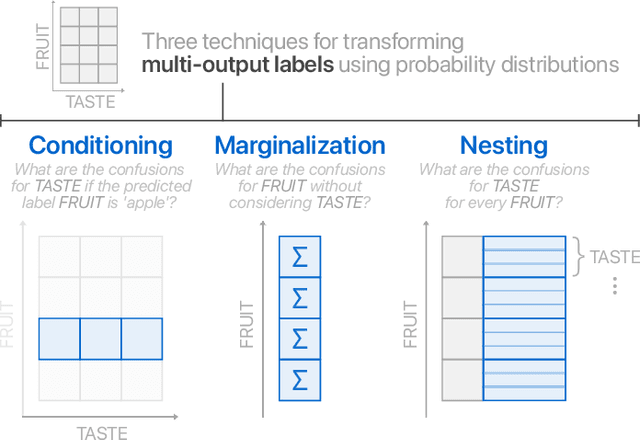

The confusion matrix, a ubiquitous visualization for helping people evaluate machine learning models, is a tabular layout that compares predicted class labels against actual class labels over all data instances. We conduct formative research with machine learning practitioners at a large technology company and find that conventional confusion matrices do not support more complex data-structures found in modern-day applications, such as hierarchical and multi-output labels. To express such variations of confusion matrices, we design an algebra that models confusion matrices as probability distributions. Based on this algebra, we develop Neo, a visual analytics system that enables practitioners to flexibly author and interact with hierarchical and multi-output confusion matrices, visualize derived metrics, renormalize confusions, and share matrix specifications. Finally, we demonstrate Neo's utility with three case studies that help people better understand model performance and reveal hidden confusions.