 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJury Learning: Integrating Dissenting Voices into Machine Learning Models
Feb 07, 2022

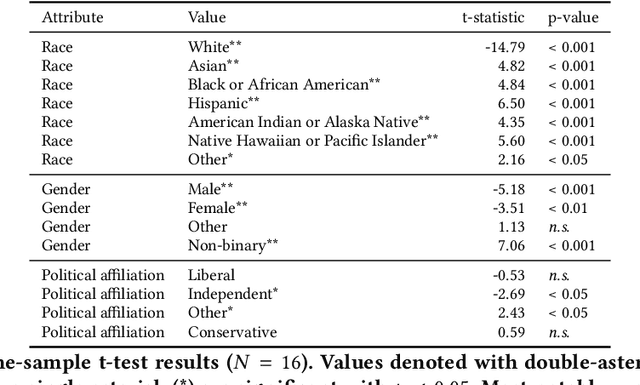

Whose labels should a machine learning (ML) algorithm learn to emulate? For ML tasks ranging from online comment toxicity to misinformation detection to medical diagnosis, different groups in society may have irreconcilable disagreements about ground truth labels. Supervised ML today resolves these label disagreements implicitly using majority vote, which overrides minority groups' labels. We introduce jury learning, a supervised ML approach that resolves these disagreements explicitly through the metaphor of a jury: defining which people or groups, in what proportion, determine the classifier's prediction. For example, a jury learning model for online toxicity might centrally feature women and Black jurors, who are commonly targets of online harassment. To enable jury learning, we contribute a deep learning architecture that models every annotator in a dataset, samples from annotators' models to populate the jury, then runs inference to classify. Our architecture enables juries that dynamically adapt their composition, explore counterfactuals, and visualize dissent.
Neo: Generalizing Confusion Matrix Visualization to Hierarchical and Multi-Output Labels
Oct 24, 2021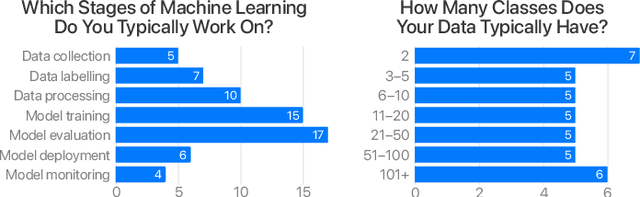

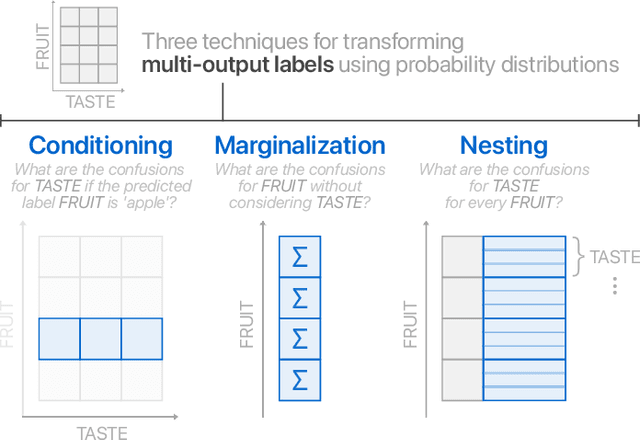

The confusion matrix, a ubiquitous visualization for helping people evaluate machine learning models, is a tabular layout that compares predicted class labels against actual class labels over all data instances. We conduct formative research with machine learning practitioners at a large technology company and find that conventional confusion matrices do not support more complex data-structures found in modern-day applications, such as hierarchical and multi-output labels. To express such variations of confusion matrices, we design an algebra that models confusion matrices as probability distributions. Based on this algebra, we develop Neo, a visual analytics system that enables practitioners to flexibly author and interact with hierarchical and multi-output confusion matrices, visualize derived metrics, renormalize confusions, and share matrix specifications. Finally, we demonstrate Neo's utility with three case studies that help people better understand model performance and reveal hidden confusions.