 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCROMA: Remote Sensing Representations with Contrastive Radar-Optical Masked Autoencoders
Nov 01, 2023A vital and rapidly growing application, remote sensing offers vast yet sparsely labeled, spatially aligned multimodal data; this makes self-supervised learning algorithms invaluable. We present CROMA: a framework that combines contrastive and reconstruction self-supervised objectives to learn rich unimodal and multimodal representations. Our method separately encodes masked-out multispectral optical and synthetic aperture radar samples -- aligned in space and time -- and performs cross-modal contrastive learning. Another encoder fuses these sensors, producing joint multimodal encodings that are used to predict the masked patches via a lightweight decoder. We show that these objectives are complementary when leveraged on spatially aligned multimodal data. We also introduce X- and 2D-ALiBi, which spatially biases our cross- and self-attention matrices. These strategies improve representations and allow our models to effectively extrapolate to images up to 17.6x larger at test-time. CROMA outperforms the current SoTA multispectral model, evaluated on: four classification benchmarks -- finetuning (avg. 1.8%), linear (avg. 2.4%) and nonlinear (avg. 1.4%) probing, kNN classification (avg. 3.5%), and K-means clustering (avg. 8.4%); and three segmentation benchmarks (avg. 6.4%). CROMA's rich, optionally multimodal representations can be widely leveraged across remote sensing applications.
Transfer Learning with Pretrained Remote Sensing Transformers
Sep 28, 2022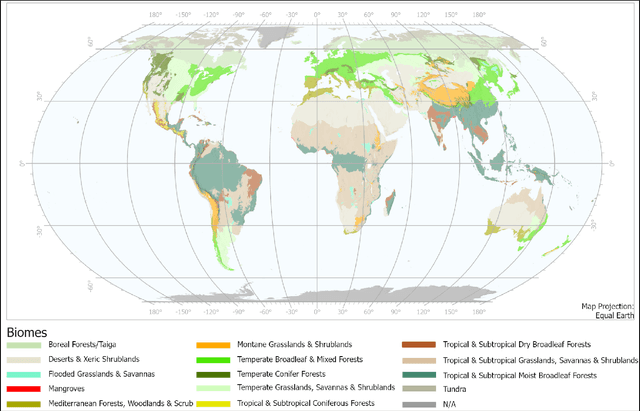
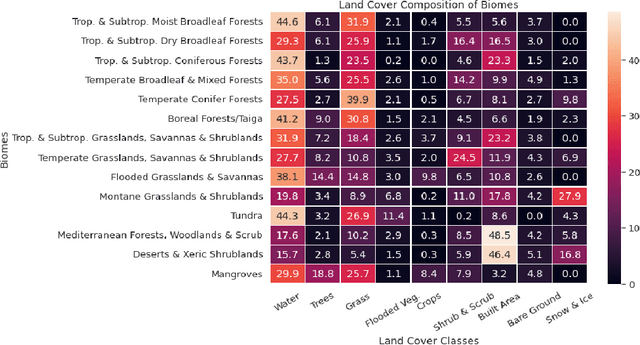
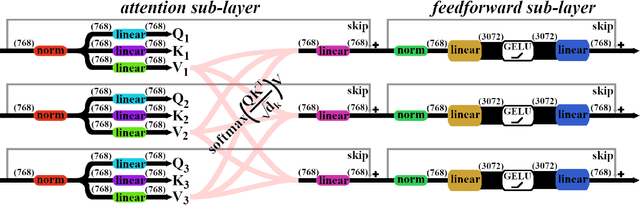
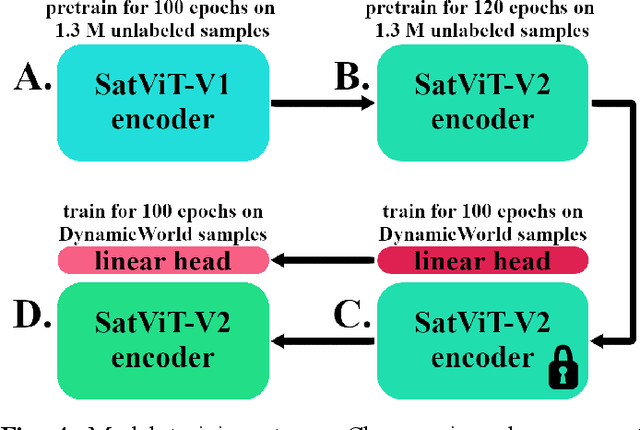
Although the remote sensing (RS) community has begun to pretrain transformers (intended to be fine-tuned on RS tasks), it is unclear how these models perform under distribution shifts. Here, we pretrain a new RS transformer--called SatViT-V2--on 1.3 million satellite-derived RS images, then fine-tune it (along with five other models) to investigate how it performs on distributions not seen during training. We split an expertly labeled land cover dataset into 14 datasets based on source biome. We train each model on each biome separately and test them on all other biomes. In all, this amounts to 1638 biome transfer experiments. After fine-tuning, we find that SatViT-V2 outperforms SatViT-V1 by 3.1% on in-distribution (matching biomes) and 2.8% on out-of-distribution (mismatching biomes) data. Additionally, we find that initializing fine-tuning from the linear probed solution (i.e., leveraging LPFT [1]) improves SatViT-V2's performance by another 1.2% on in-distribution and 2.4% on out-of-distribution data. Next, we find that pretrained RS transformers are better calibrated under distribution shifts than non-pretrained models and leveraging LPFT results in further improvements in model calibration. Lastly, we find that five measures of distribution shift are moderately correlated with biome transfer performance. We share code and pretrained model weights. (https://github.com/antofuller/SatViT)