 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLookWhere? Efficient Visual Recognition by Learning Where to Look and What to See from Self-Supervision
May 23, 2025Vision transformers are ever larger, more accurate, and more expensive to compute. The expense is even more extreme at high resolution as the number of tokens grows quadratically with the image size. We turn to adaptive computation to cope with this cost by learning to predict where to compute. Our LookWhere method divides the computation between a low-resolution selector and a high-resolution extractor without ever processing the full high-resolution input. We jointly pretrain the selector and extractor without task supervision by distillation from a self-supervised teacher, in effect, learning where and what to compute simultaneously. Unlike prior token reduction methods, which pay to save by pruning already-computed tokens, and prior token selection methods, which require complex and expensive per-task optimization, LookWhere economically and accurately selects and extracts transferrable representations of images. We show that LookWhere excels at sparse recognition on high-resolution inputs (Traffic Signs), maintaining accuracy while reducing FLOPs by up to 34x and time by 6x. It also excels at standard recognition tasks that are global (ImageNet classification) or local (ADE20K segmentation), improving accuracy while reducing time by 1.36x.
Simpler Fast Vision Transformers with a Jumbo CLS Token
Feb 20, 2025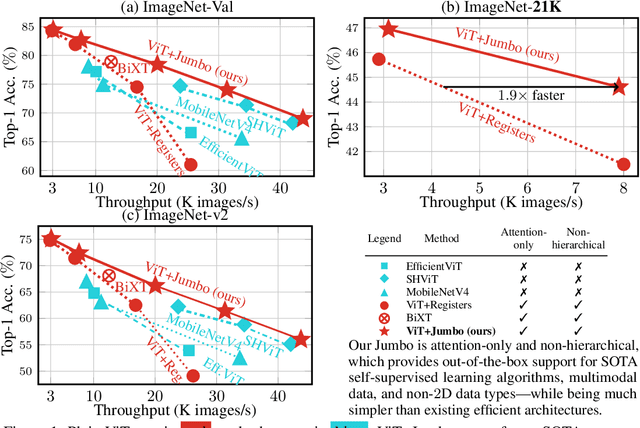
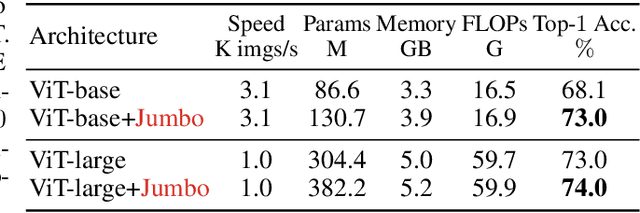
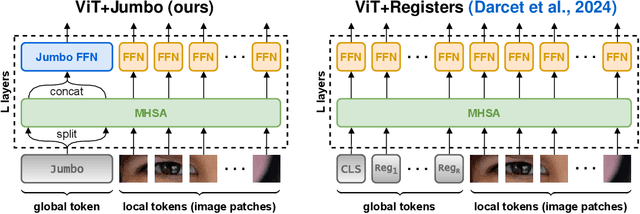

We introduce a simple enhancement to the global processing of vision transformers (ViTs) to improve accuracy while maintaining throughput. Our approach, Jumbo, creates a wider CLS token, which is split to match the patch token width before attention, processed with self-attention, and reassembled. After attention, Jumbo applies a dedicated, wider FFN to this token. Jumbo significantly improves over ViT+Registers on ImageNet-1K at high speeds (by 3.2% for ViT-tiny and 13.5% for ViT-nano); these Jumbo models even outperform specialized compute-efficient models while preserving the architectural advantages of plain ViTs. Although Jumbo sees no gains for ViT-small on ImageNet-1K, it gains 3.4% on ImageNet-21K over ViT+Registers. Both findings indicate that Jumbo is most helpful when the ViT is otherwise too narrow for the task. Finally, we show that Jumbo can be easily adapted to excel on data beyond images, e.g., time series.
LookHere: Vision Transformers with Directed Attention Generalize and Extrapolate
May 22, 2024High-resolution images offer more information about scenes that can improve model accuracy. However, the dominant model architecture in computer vision, the vision transformer (ViT), cannot effectively leverage larger images without finetuning -- ViTs poorly extrapolate to more patches at test time, although transformers offer sequence length flexibility. We attribute this shortcoming to the current patch position encoding methods, which create a distribution shift when extrapolating. We propose a drop-in replacement for the position encoding of plain ViTs that restricts attention heads to fixed fields of view, pointed in different directions, using 2D attention masks. Our novel method, called LookHere, provides translation-equivariance, ensures attention head diversity, and limits the distribution shift that attention heads face when extrapolating. We demonstrate that LookHere improves performance on classification (avg. 1.6%), against adversarial attack (avg. 5.4%), and decreases calibration error (avg. 1.5%) -- on ImageNet without extrapolation. With extrapolation, LookHere outperforms the current SoTA position encoding method, 2D-RoPE, by 21.7% on ImageNet when trained at $224^2$ px and tested at $1024^2$ px. Additionally, we release a high-resolution test set to improve the evaluation of high-resolution image classifiers, called ImageNet-HR.
Under the Cover Infant Pose Estimation using Multimodal Data
Oct 03, 2022



Infant pose monitoring during sleep has multiple applications in both healthcare and home settings. In a healthcare setting, pose detection can be used for region of interest detection and movement detection for noncontact based monitoring systems. In a home setting, pose detection can be used to detect sleep positions which has shown to have a strong influence on multiple health factors. However, pose monitoring during sleep is challenging due to heavy occlusions from blanket coverings and low lighting. To address this, we present a novel dataset, Simultaneously-collected multimodal Mannequin Lying pose (SMaL) dataset, for under the cover infant pose estimation. We collect depth and pressure imagery of an infant mannequin in different poses under various cover conditions. We successfully infer full body pose under the cover by training state-of-art pose estimation methods and leveraging existing multimodal adult pose datasets for transfer learning. We demonstrate a hierarchical pretraining strategy for transformer-based models to significantly improve performance on our dataset. Our best performing model was able to detect joints under the cover within 25mm 86% of the time with an overall mean error of 16.9mm. Data, code and models publicly available at https://github.com/DanielKyr/SMaL