 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMissing Pattern Tree based Decision Grouping and Ensemble for Deep Incomplete Multi-View Clustering
Dec 25, 2025Real-world multi-view data usually exhibits highly inconsistent missing patterns which challenges the effectiveness of incomplete multi-view clustering (IMVC). Although existing IMVC methods have made progress from both imputation-based and imputation-free routes, they have overlooked the pair under-utilization issue, i.e., inconsistent missing patterns make the incomplete but available multi-view pairs unable to be fully utilized, thereby limiting the model performance. To address this, we propose a novel missing-pattern tree based IMVC framework entitled TreeEIC. Specifically, to achieve full exploitation of available multi-view pairs, TreeEIC first defines the missing-pattern tree model to group data into multiple decision sets according to different missing patterns, and then performs multi-view clustering within each set. Furthermore, a multi-view decision ensemble module is proposed to aggregate clustering results from all decision sets, which infers uncertainty-based weights to suppress unreliable clustering decisions and produce robust decisions. Finally, an ensemble-to-individual knowledge distillation module transfers the ensemble knowledge to view-specific clustering models, which enables ensemble and individual modules to promote each other by optimizing cross-view consistency and inter-cluster discrimination losses. Extensive experiments on multiple benchmark datasets demonstrate that our TreeEIC achieves state-of-the-art IMVC performance and exhibits superior robustness under highly inconsistent missing patterns.
Joint Prediction and Time Estimation of COVID-19 Developing Severe Symptoms using Chest CT Scan
May 07, 2020
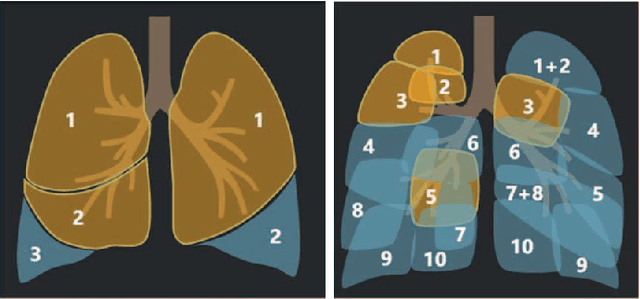
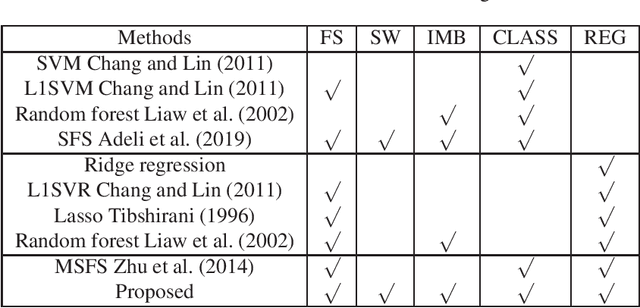
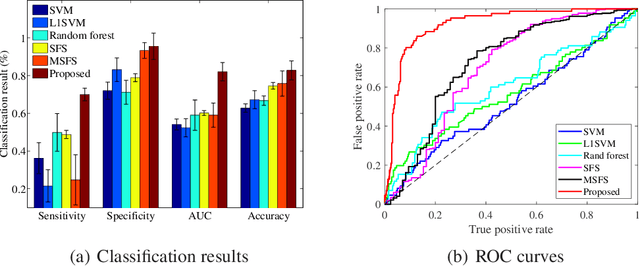
With the rapidly worldwide spread of Coronavirus disease (COVID-19), it is of great importance to conduct early diagnosis of COVID-19 and predict the time that patients might convert to the severe stage, for designing effective treatment plan and reducing the clinicians' workloads. In this study, we propose a joint classification and regression method to determine whether the patient would develop severe symptoms in the later time, and if yes, predict the possible conversion time that the patient would spend to convert to the severe stage. To do this, the proposed method takes into account 1) the weight for each sample to reduce the outliers' influence and explore the problem of imbalance classification, and 2) the weight for each feature via a sparsity regularization term to remove the redundant features of high-dimensional data and learn the shared information across the classification task and the regression task. To our knowledge, this study is the first work to predict the disease progression and the conversion time, which could help clinicians to deal with the potential severe cases in time or even save the patients' lives. Experimental analysis was conducted on a real data set from two hospitals with 422 chest computed tomography (CT) scans, where 52 cases were converted to severe on average 5.64 days and 34 cases were severe at admission. Results show that our method achieves the best classification (e.g., 85.91% of accuracy) and regression (e.g., 0.462 of the correlation coefficient) performance, compared to all comparison methods. Moreover, our proposed method yields 76.97% of accuracy for predicting the severe cases, 0.524 of the correlation coefficient, and 0.55 days difference for the converted time.