 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Video Class-Incremental Learning via Deep Embedded Clustering Management
Jan 20, 2026Unsupervised video class incremental learning (uVCIL) represents an important learning paradigm for learning video information without forgetting, and without considering any data labels. Prior approaches have focused on supervised class-incremental learning, relying on using the knowledge of labels and task boundaries, which is costly, requires human annotation, or is simply not a realistic option. In this paper, we propose a simple yet effective approach to address the uVCIL. We first consider a deep feature extractor network, providing a set of representative video features during each task without assuming any class or task information. We then progressively build a series of deep clusters from the extracted features. During the successive task learning, the model updated from the previous task is used as an initial state in order to transfer knowledge to the current learning task. We perform in-depth evaluations on three standard video action recognition datasets, including UCF101, HMDB51, and Something-to-Something V2, by ignoring the labels from the supervised setting. Our approach significantly outperforms other baselines on all datasets.
Two-Stream temporal transformer for video action classification
Jan 20, 2026Motion representation plays an important role in video understanding and has many applications including action recognition, robot and autonomous guidance or others. Lately, transformer networks, through their self-attention mechanism capabilities, have proved their efficiency in many applications. In this study, we introduce a new two-stream transformer video classifier, which extracts spatio-temporal information from content and optical flow representing movement information. The proposed model identifies self-attention features across the joint optical flow and temporal frame domain and represents their relationships within the transformer encoder mechanism. The experimental results show that our proposed methodology provides excellent classification results on three well-known video datasets of human activities.
Inference-based GAN Video Generation
Dec 25, 2025



Video generation has seen remarkable progresses thanks to advancements in generative deep learning. Generated videos should not only display coherent and continuous movement but also meaningful movement in successions of scenes. Generating models such as Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs) and more recently Diffusion Networks have been used for generating short video sequences, usually of up to 16 frames. In this paper, we first propose a new type of video generator by enabling adversarial-based unconditional video generators with a variational encoder, akin to a VAE-GAN hybrid structure, in order to enable the generation process with inference capabilities. The proposed model, as in other video deep learning-based processing frameworks, incorporates two processing branches, one for content and another for movement. However, existing models struggle with the temporal scaling of the generated videos. In classical approaches when aiming to increase the generated video length, the resulting video quality degrades, particularly when considering generating significantly long sequences. To overcome this limitation, our research study extends the initially proposed VAE-GAN video generation model by employing a novel, memory-efficient approach to generate long videos composed of hundreds or thousands of frames ensuring their temporal continuity, consistency and dynamics. Our approach leverages a Markov chain framework with a recall mechanism, with each state representing a VAE-GAN short-length video generator. This setup allows for the sequential connection of generated video sub-sequences, enabling temporal dependencies, resulting in meaningful long video sequences.
Unsupervised Video Continual Learning via Non-Parametric Deep Embedded Clustering
Aug 29, 2025We propose a realistic scenario for the unsupervised video learning where neither task boundaries nor labels are provided when learning a succession of tasks. We also provide a non-parametric learning solution for the under-explored problem of unsupervised video continual learning. Videos represent a complex and rich spatio-temporal media information, widely used in many applications, but which have not been sufficiently explored in unsupervised continual learning. Prior studies have only focused on supervised continual learning, relying on the knowledge of labels and task boundaries, while having labeled data is costly and not practical. To address this gap, we study the unsupervised video continual learning (uVCL). uVCL raises more challenges due to the additional computational and memory requirements of processing videos when compared to images. We introduce a general benchmark experimental protocol for uVCL by considering the learning of unstructured video data categories during each task. We propose to use the Kernel Density Estimation (KDE) of deep embedded video features extracted by unsupervised video transformer networks as a non-parametric probabilistic representation of the data. We introduce a novelty detection criterion for the incoming new task data, dynamically enabling the expansion of memory clusters, aiming to capture new knowledge when learning a succession of tasks. We leverage the use of transfer learning from the previous tasks as an initial state for the knowledge transfer to the current learning task. We found that the proposed methodology substantially enhances the performance of the model when successively learning many tasks. We perform in-depth evaluations on three standard video action recognition datasets, including UCF101, HMDB51, and Something-to-Something V2, without using any labels or class boundaries.
Masked Image Residual Learning for Scaling Deeper Vision Transformers
Sep 25, 2023Deeper Vision Transformers (ViTs) are more challenging to train. We expose a degradation problem in deeper layers of ViT when using masked image modeling (MIM) for pre-training. To ease the training of deeper ViTs, we introduce a self-supervised learning framework called \textbf{M}asked \textbf{I}mage \textbf{R}esidual \textbf{L}earning (\textbf{MIRL}), which significantly alleviates the degradation problem, making scaling ViT along depth a promising direction for performance upgrade. We reformulate the pre-training objective for deeper layers of ViT as learning to recover the residual of the masked image. We provide extensive empirical evidence showing that deeper ViTs can be effectively optimized using MIRL and easily gain accuracy from increased depth. With the same level of computational complexity as ViT-Base and ViT-Large, we instantiate 4.5{$\times$} and 2{$\times$} deeper ViTs, dubbed ViT-S-54 and ViT-B-48. The deeper ViT-S-54, costing 3{$\times$} less than ViT-Large, achieves performance on par with ViT-Large. ViT-B-48 achieves 86.2\% top-1 accuracy on ImageNet. On one hand, deeper ViTs pre-trained with MIRL exhibit excellent generalization capabilities on downstream tasks, such as object detection and semantic segmentation. On the other hand, MIRL demonstrates high pre-training efficiency. With less pre-training time, MIRL yields competitive performance compared to other approaches.
Dynamic Appearance: A Video Representation for Action Recognition with Joint Training
Nov 24, 2022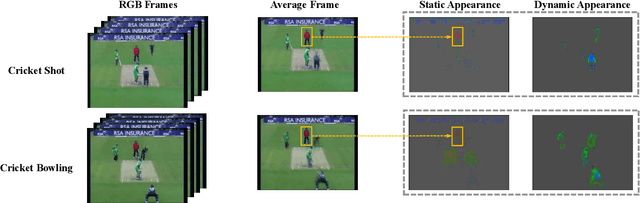
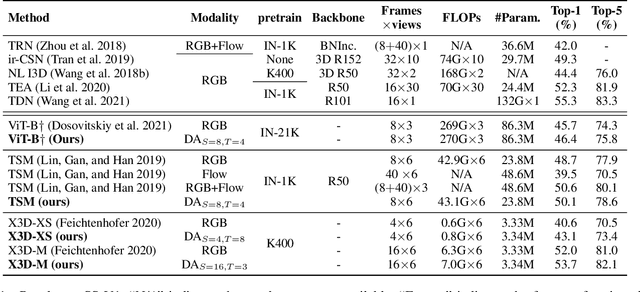
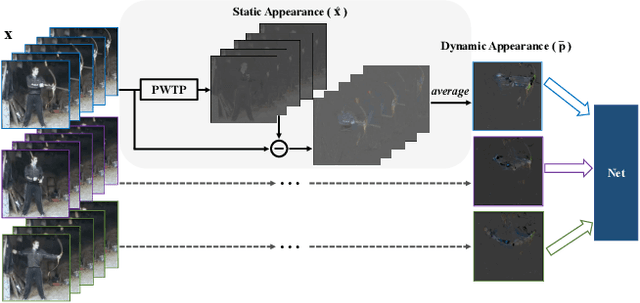
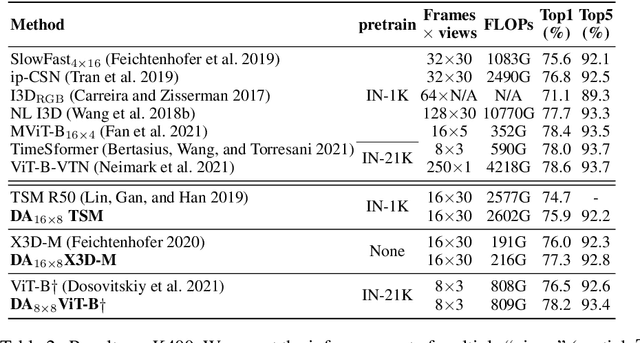
Static appearance of video may impede the ability of a deep neural network to learn motion-relevant features in video action recognition. In this paper, we introduce a new concept, Dynamic Appearance (DA), summarizing the appearance information relating to movement in a video while filtering out the static information considered unrelated to motion. We consider distilling the dynamic appearance from raw video data as a means of efficient video understanding. To this end, we propose the Pixel-Wise Temporal Projection (PWTP), which projects the static appearance of a video into a subspace within its original vector space, while the dynamic appearance is encoded in the projection residual describing a special motion pattern. Moreover, we integrate the PWTP module with a CNN or Transformer into an end-to-end training framework, which is optimized by utilizing multi-objective optimization algorithms. We provide extensive experimental results on four action recognition benchmarks: Kinetics400, Something-Something V1, UCF101 and HMDB51.
Task-Free Continual Learning via Online Discrepancy Distance Learning
Oct 12, 2022
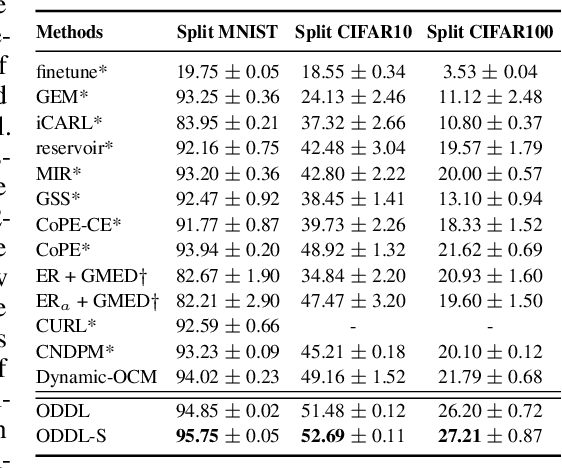

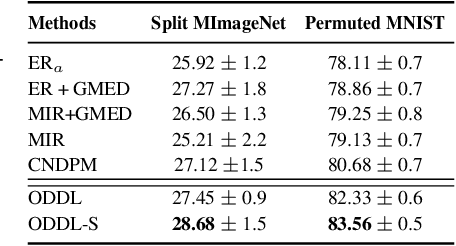
Learning from non-stationary data streams, also called Task-Free Continual Learning (TFCL) remains challenging due to the absence of explicit task information. Although recently some methods have been proposed for TFCL, they lack theoretical guarantees. Moreover, forgetting analysis during TFCL was not studied theoretically before. This paper develops a new theoretical analysis framework which provides generalization bounds based on the discrepancy distance between the visited samples and the entire information made available for training the model. This analysis gives new insights into the forgetting behaviour in classification tasks. Inspired by this theoretical model, we propose a new approach enabled by the dynamic component expansion mechanism for a mixture model, namely the Online Discrepancy Distance Learning (ODDL). ODDL estimates the discrepancy between the probabilistic representation of the current memory buffer and the already accumulated knowledge and uses it as the expansion signal to ensure a compact network architecture with optimal performance. We then propose a new sample selection approach that selectively stores the most relevant samples into the memory buffer through the discrepancy-based measure, further improving the performance. We perform several TFCL experiments with the proposed methodology, which demonstrate that the proposed approach achieves the state of the art performance.
Continual Variational Autoencoder Learning via Online Cooperative Memorization
Jul 20, 2022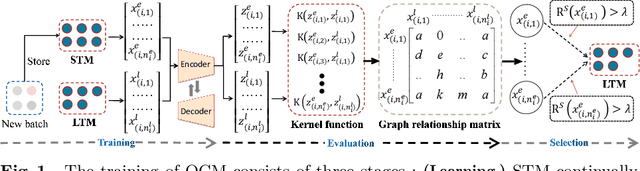
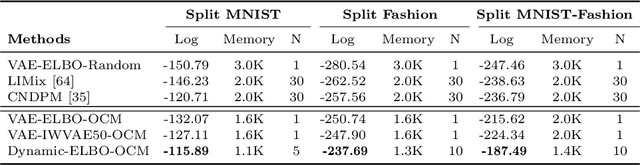

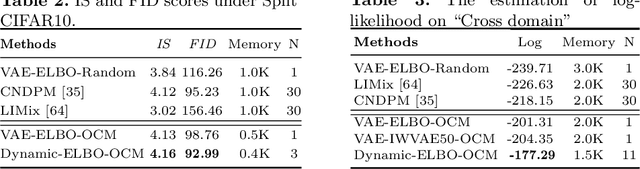
Due to their inference, data representation and reconstruction properties, Variational Autoencoders (VAE) have been successfully used in continual learning classification tasks. However, their ability to generate images with specifications corresponding to the classes and databases learned during Continual Learning (CL) is not well understood and catastrophic forgetting remains a significant challenge. In this paper, we firstly analyze the forgetting behaviour of VAEs by developing a new theoretical framework that formulates CL as a dynamic optimal transport problem. This framework proves approximate bounds to the data likelihood without requiring the task information and explains how the prior knowledge is lost during the training process. We then propose a novel memory buffering approach, namely the Online Cooperative Memorization (OCM) framework, which consists of a Short-Term Memory (STM) that continually stores recent samples to provide future information for the model, and a Long-Term Memory (LTM) aiming to preserve a wide diversity of samples. The proposed OCM transfers certain samples from STM to LTM according to the information diversity selection criterion without requiring any supervised signals. The OCM framework is then combined with a dynamic VAE expansion mixture network for further enhancing its performance.
Learning an evolved mixture model for task-free continual learning
Jul 11, 2022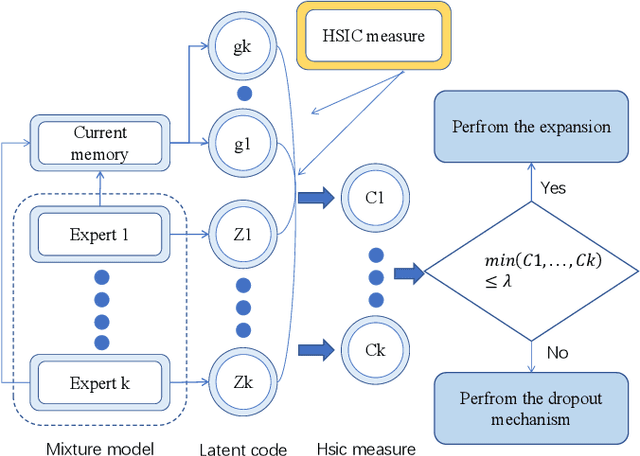

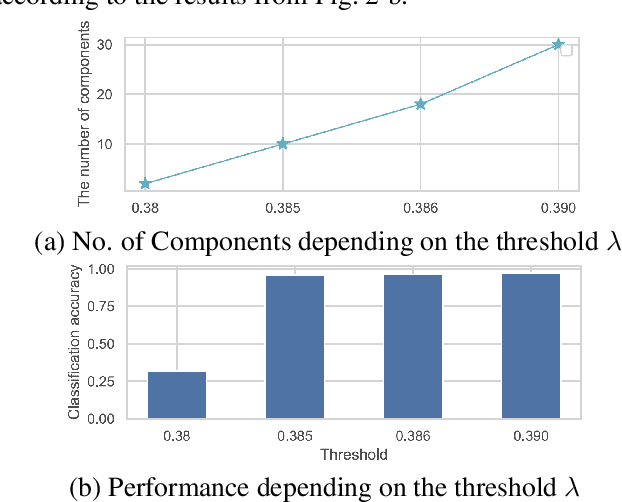
Recently, continual learning (CL) has gained significant interest because it enables deep learning models to acquire new knowledge without forgetting previously learnt information. However, most existing works require knowing the task identities and boundaries, which is not realistic in a real context. In this paper, we address a more challenging and realistic setting in CL, namely the Task-Free Continual Learning (TFCL) in which a model is trained on non-stationary data streams with no explicit task information. To address TFCL, we introduce an evolved mixture model whose network architecture is dynamically expanded to adapt to the data distribution shift. We implement this expansion mechanism by evaluating the probability distance between the knowledge stored in each mixture model component and the current memory buffer using the Hilbert Schmidt Independence Criterion (HSIC). We further introduce two simple dropout mechanisms to selectively remove stored examples in order to avoid memory overload while preserving memory diversity. Empirical results demonstrate that the proposed approach achieves excellent performance.
Supplemental Material: Lifelong Generative Modelling Using Dynamic Expansion Graph Model
Mar 25, 2022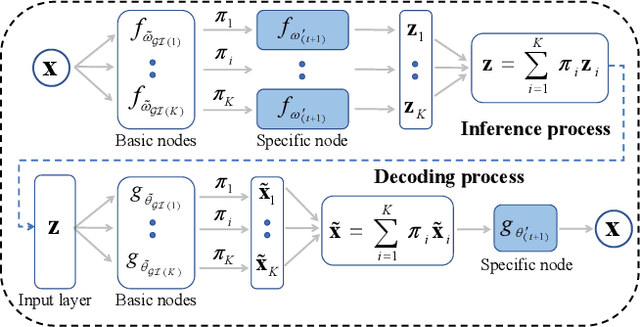
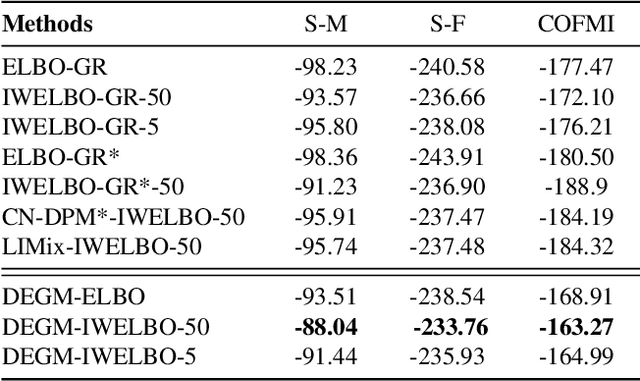
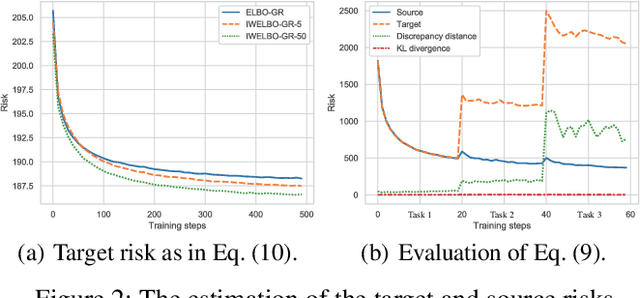
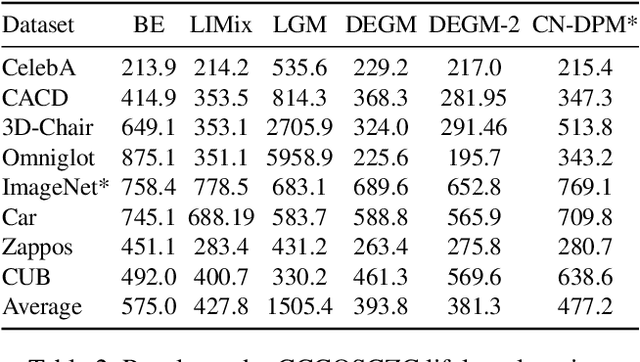
In this article, we provide the appendix for Lifelong Generative Modelling Using Dynamic Expansion Graph Model. This appendix includes additional visual results as well as the numerical results on the challenging datasets. In addition, we also provide detailed proofs for the proposed theoretical analysis framework. The source code can be found in https://github.com/dtuzi123/Expansion-Graph-Model.