 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Appearance: A Video Representation for Action Recognition with Joint Training
Paper and Code
Nov 24, 2022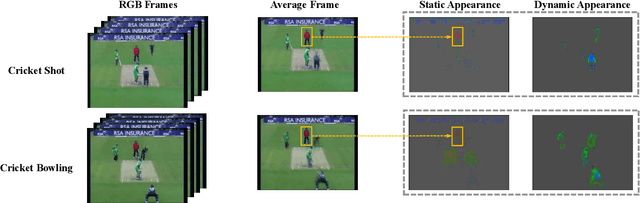
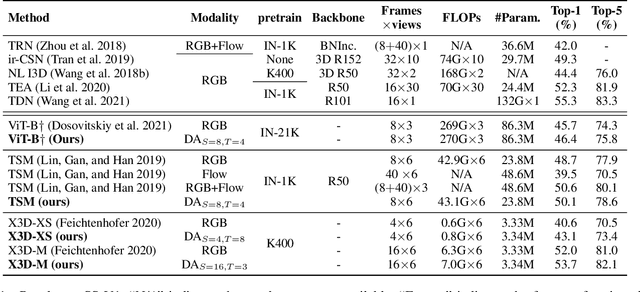
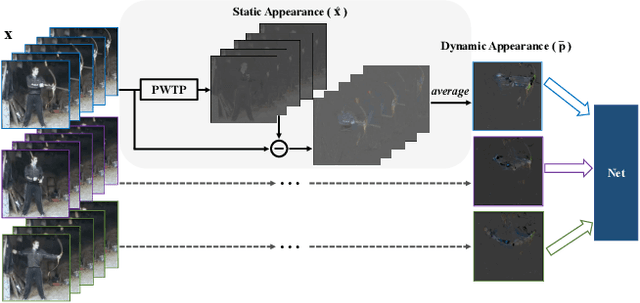
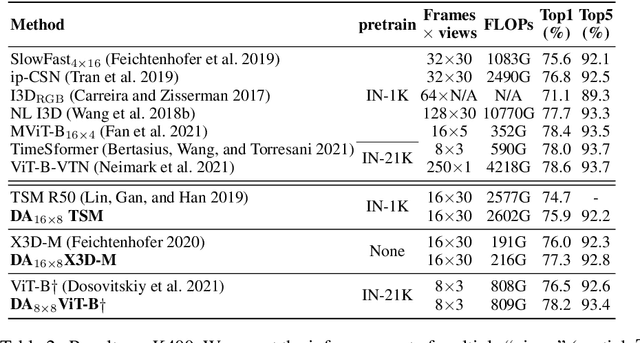
Static appearance of video may impede the ability of a deep neural network to learn motion-relevant features in video action recognition. In this paper, we introduce a new concept, Dynamic Appearance (DA), summarizing the appearance information relating to movement in a video while filtering out the static information considered unrelated to motion. We consider distilling the dynamic appearance from raw video data as a means of efficient video understanding. To this end, we propose the Pixel-Wise Temporal Projection (PWTP), which projects the static appearance of a video into a subspace within its original vector space, while the dynamic appearance is encoded in the projection residual describing a special motion pattern. Moreover, we integrate the PWTP module with a CNN or Transformer into an end-to-end training framework, which is optimized by utilizing multi-objective optimization algorithms. We provide extensive experimental results on four action recognition benchmarks: Kinetics400, Something-Something V1, UCF101 and HMDB51.