 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarine Snow Removal Using Internally Generated Pseudo Ground Truth
Apr 27, 2025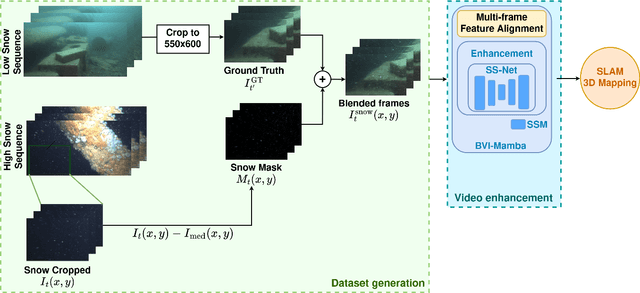


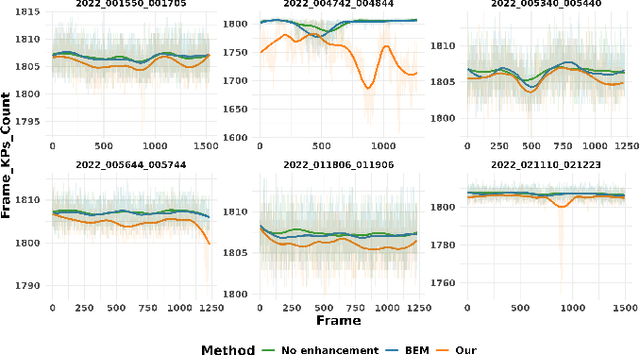
Underwater videos often suffer from degraded quality due to light absorption, scattering, and various noise sources. Among these, marine snow, which is suspended organic particles appearing as bright spots or noise, significantly impacts machine vision tasks, particularly those involving feature matching. Existing methods for removing marine snow are ineffective due to the lack of paired training data. To address this challenge, this paper proposes a novel enhancement framework that introduces a new approach for generating paired datasets from raw underwater videos. The resulting dataset consists of paired images of generated snowy and snow, free underwater videos, enabling supervised training for video enhancement. We describe the dataset creation process, highlight its key characteristics, and demonstrate its effectiveness in enhancing underwater image restoration in the absence of ground truth.
BVI-RLV: A Fully Registered Dataset and Benchmarks for Low-Light Video Enhancement
Jul 03, 2024
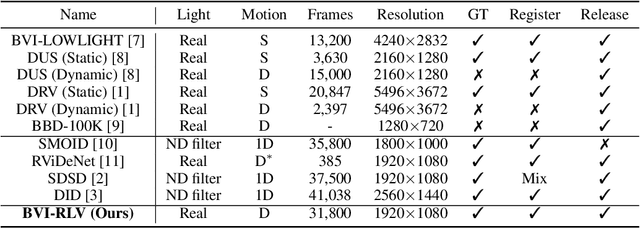
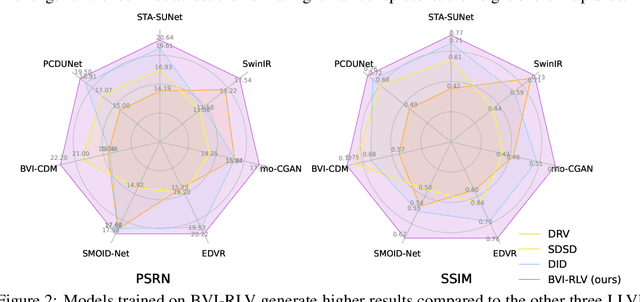
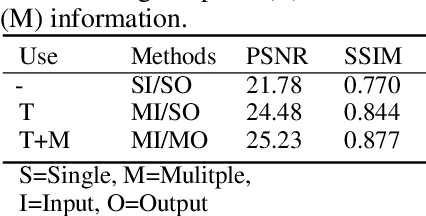
Low-light videos often exhibit spatiotemporal incoherent noise, compromising visibility and performance in computer vision applications. One significant challenge in enhancing such content using deep learning is the scarcity of training data. This paper introduces a novel low-light video dataset, consisting of 40 scenes with various motion scenarios under two distinct low-lighting conditions, incorporating genuine noise and temporal artifacts. We provide fully registered ground truth data captured in normal light using a programmable motorized dolly and refine it via an image-based approach for pixel-wise frame alignment across different light levels. We provide benchmarks based on four different technologies: convolutional neural networks, transformers, diffusion models, and state space models (mamba). Our experimental results demonstrate the significance of fully registered video pairs for low-light video enhancement (LLVE) and the comprehensive evaluation shows that the models trained with our dataset outperform those trained with the existing datasets. Our dataset and links to benchmarks are publicly available at https://doi.org/10.21227/mzny-8c77.
A Spatio-temporal Aligned SUNet Model for Low-light Video Enhancement
Mar 04, 2024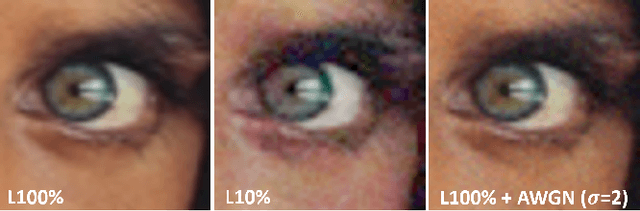


Distortions caused by low-light conditions are not only visually unpleasant but also degrade the performance of computer vision tasks. The restoration and enhancement have proven to be highly beneficial. However, there are only a limited number of enhancement methods explicitly designed for videos acquired in low-light conditions. We propose a Spatio-Temporal Aligned SUNet (STA-SUNet) model using a Swin Transformer as a backbone to capture low light video features and exploit their spatio-temporal correlations. The STA-SUNet model is trained on a novel, fully registered dataset (BVI), which comprises dynamic scenes captured under varying light conditions. It is further analysed comparatively against various other models over three test datasets. The model demonstrates superior adaptivity across all datasets, obtaining the highest PSNR and SSIM values. It is particularly effective in extreme low-light conditions, yielding fairly good visualisation results.
BVI-Lowlight: Fully Registered Benchmark Dataset for Low-Light Video Enhancement
Feb 03, 2024
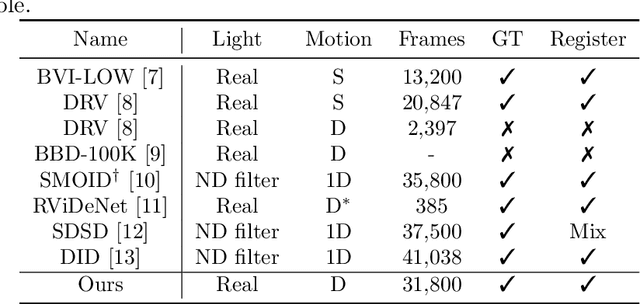

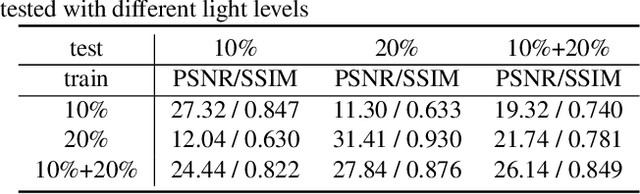
Low-light videos often exhibit spatiotemporal incoherent noise, leading to poor visibility and compromised performance across various computer vision applications. One significant challenge in enhancing such content using modern technologies is the scarcity of training data. This paper introduces a novel low-light video dataset, consisting of 40 scenes captured in various motion scenarios under two distinct low-lighting conditions, incorporating genuine noise and temporal artifacts. We provide fully registered ground truth data captured in normal light using a programmable motorized dolly, and subsequently, refine them via image-based post-processing to ensure the pixel-wise alignment of frames in different light levels. This paper also presents an exhaustive analysis of the low-light dataset, and demonstrates the extensive and representative nature of our dataset in the context of supervised learning. Our experimental results demonstrate the significance of fully registered video pairs in the development of low-light video enhancement methods and the need for comprehensive evaluation. Our dataset is available at DOI:10.21227/mzny-8c77.
Wavelet-based Topological Loss for Low-Light Image Denoising
Sep 20, 2023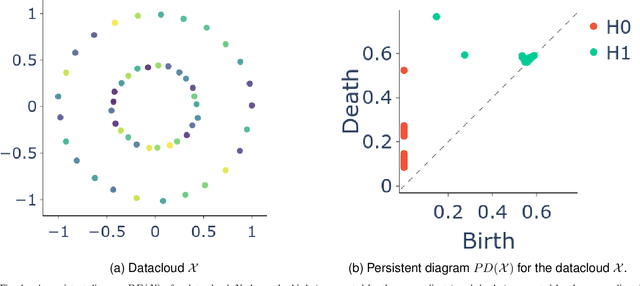
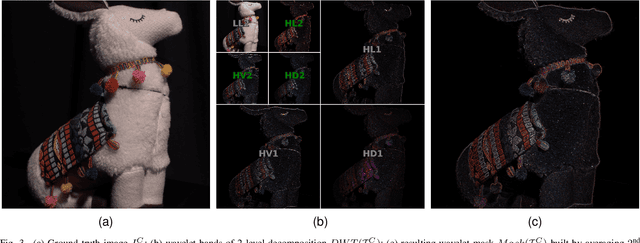
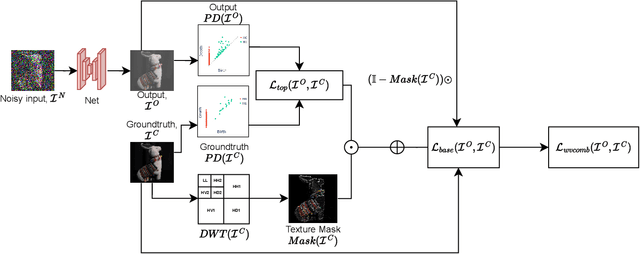
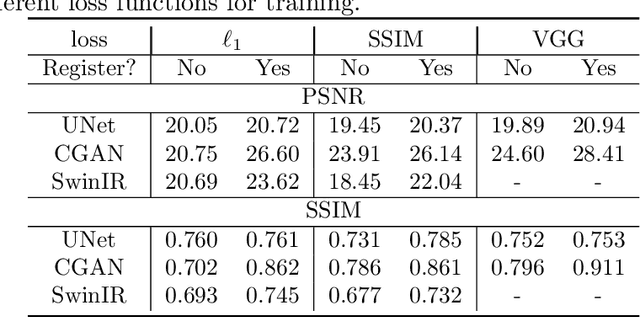
Despite extensive research conducted in the field of image denoising, many algorithms still heavily depend on supervised learning and their effectiveness primarily relies on the quality and diversity of training data. It is widely assumed that digital image distortions are caused by spatially invariant Additive White Gaussian Noise (AWGN). However, the analysis of real-world data suggests that this assumption is invalid. Therefore, this paper tackles image corruption by real noise, providing a framework to capture and utilise the underlying structural information of an image along with the spatial information conventionally used for deep learning tasks. We propose a novel denoising loss function that incorporates topological invariants and is informed by textural information extracted from the image wavelet domain. The effectiveness of this proposed method was evaluated by training state-of-the-art denoising models on the BVI-Lowlight dataset, which features a wide range of real noise distortions. Adding a topological term to common loss functions leads to a significant increase in the LPIPS (Learned Perceptual Image Patch Similarity) metric, with the improvement reaching up to 25\%. The results indicate that the proposed loss function enables neural networks to learn noise characteristics better. We demonstrate that they can consequently extract the topological features of noise-free images, resulting in enhanced contrast and preserved textural information.
A Topological Loss Function for Low-Light Image Denoising
Aug 18, 2022
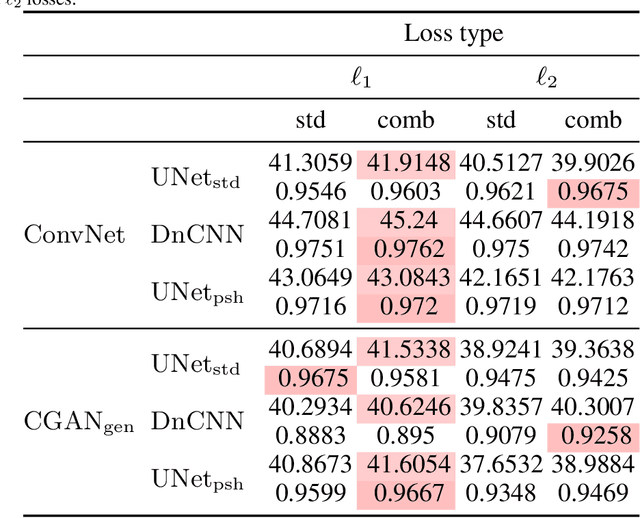

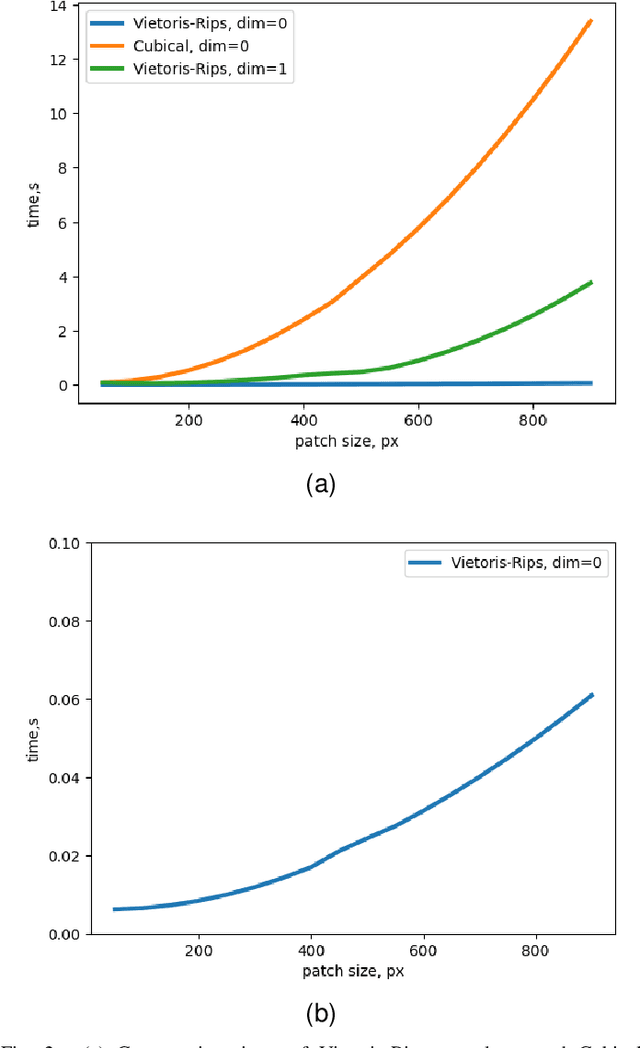
Although image denoising algorithms have attracted significant research attention, surprisingly few have been proposed for, or evaluated on, noise from imagery acquired under real low-light conditions. Moreover, noise characteristics are often assumed to be spatially invariant, leading to edges and textures being distorted after denoising. Here, we introduce a novel topological loss function which is based on persistent homology, offering true features with resistance to noise across multiple scales. The method performs in the space of image patches, where topological invariants are calculated and represented in persistent diagrams. The loss function is a combination of $\ell_1$ or $\ell_2$ losses with the new persistence-based topological loss. We compare its performance across popular denoising architectures, training the networks on our new comprehensive dataset of natural images captured in low-light conditions -- BVI-LOWLIGHT. Analysis reveals that this approach outperforms existing methods, adapting well to edges and complex structures and suppressing common artifacts.
Encoding in the Dark Grand Challenge: An Overview
May 07, 2020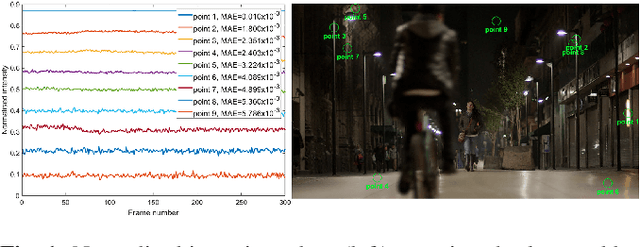
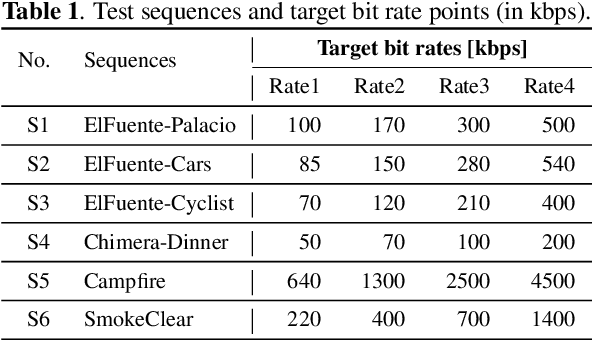

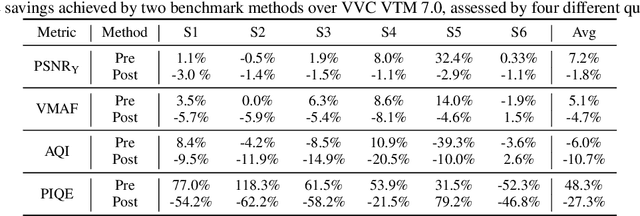
A big part of the video content we consume from video providers consists of genres featuring low-light aesthetics. Low light sequences have special characteristics, such as spatio-temporal varying acquisition noise and light flickering, that make the encoding process challenging. To deal with the spatio-temporal incoherent noise, higher bitrates are used to achieve high objective quality. Additionally, the quality assessment metrics and methods have not been designed, trained or tested for this type of content. This has inspired us to trigger research in that area and propose a Grand Challenge on encoding low-light video sequences. In this paper, we present an overview of the proposed challenge, and test state-of-the-art methods that will be part of the benchmark methods at the stage of the participants' deliverable assessment. From this exploration, our results show that VVC already achieves a high performance compared to simply denoising the video source prior to encoding. Moreover, the quality of the video streams can be further improved by employing a post-processing image enhancement method.