 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Image Fusion Using Deep Image Priors
Oct 24, 2021
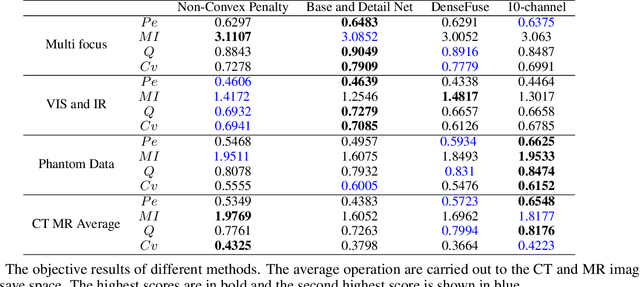

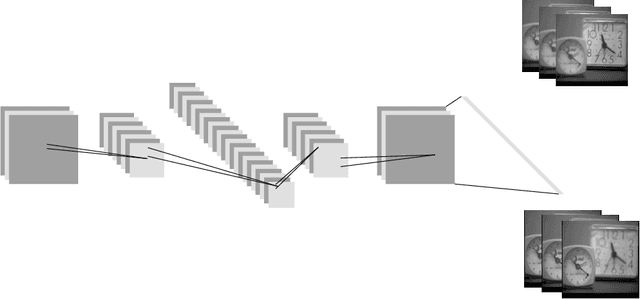
A significant number of researchers have recently applied deep learning methods to image fusion. However, most of these works either require a large amount of training data or depend on pre-trained models or frameworks. This inevitably encounters a shortage of training data or a mismatch between the framework and the actual problem. Recently, the publication of Deep Image Prior (DIP) method made it possible to do image restoration totally training-data-free. However, the original design of DIP is hard to be generalized to multi-image processing problems. This paper introduces a novel loss calculation structure, in the framework of DIP, while formulating image fusion as an inverse problem. This enables the extension of DIP to general multisensor/multifocus image fusion problems. Secondly, we propose a multi-channel approach to improve the effect of DIP. Finally, an evaluation is conducted using several commonly used image fusion assessment metrics. The results are compared with state-of-the-art traditional and deep learning image fusion methods. Our method outperforms previous techniques for a range of metrics. In particular, it is shown to provide the best objective results for most metrics when applied to medical images.
Encoding in the Dark Grand Challenge: An Overview
May 07, 2020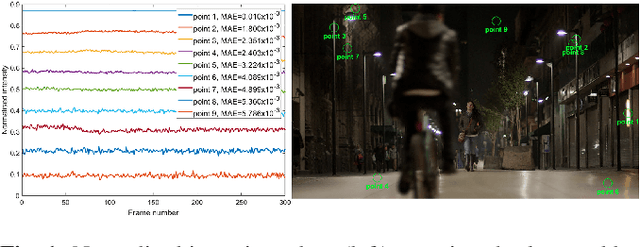
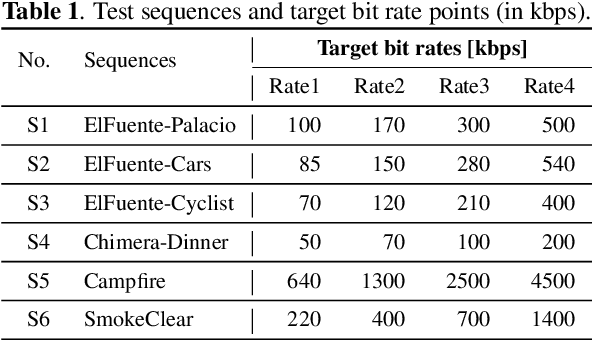

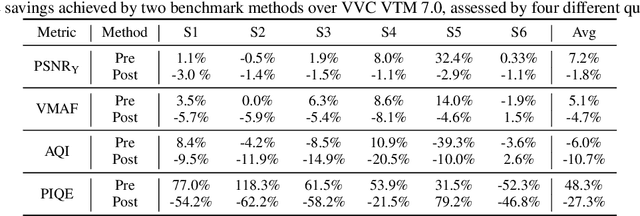
A big part of the video content we consume from video providers consists of genres featuring low-light aesthetics. Low light sequences have special characteristics, such as spatio-temporal varying acquisition noise and light flickering, that make the encoding process challenging. To deal with the spatio-temporal incoherent noise, higher bitrates are used to achieve high objective quality. Additionally, the quality assessment metrics and methods have not been designed, trained or tested for this type of content. This has inspired us to trigger research in that area and propose a Grand Challenge on encoding low-light video sequences. In this paper, we present an overview of the proposed challenge, and test state-of-the-art methods that will be part of the benchmark methods at the stage of the participants' deliverable assessment. From this exploration, our results show that VVC already achieves a high performance compared to simply denoising the video source prior to encoding. Moreover, the quality of the video streams can be further improved by employing a post-processing image enhancement method.