 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a General-Purpose Zero-Shot Synthetic Low-Light Image and Video Pipeline
Apr 16, 2025



Low-light conditions pose significant challenges for both human and machine annotation. This in turn has led to a lack of research into machine understanding for low-light images and (in particular) videos. A common approach is to apply annotations obtained from high quality datasets to synthetically created low light versions. In addition, these approaches are often limited through the use of unrealistic noise models. In this paper, we propose a new Degradation Estimation Network (DEN), which synthetically generates realistic standard RGB (sRGB) noise without the requirement for camera metadata. This is achieved by estimating the parameters of physics-informed noise distributions, trained in a self-supervised manner. This zero-shot approach allows our method to generate synthetic noisy content with a diverse range of realistic noise characteristics, unlike other methods which focus on recreating the noise characteristics of the training data. We evaluate our proposed synthetic pipeline using various methods trained on its synthetic data for typical low-light tasks including synthetic noise replication, video enhancement, and object detection, showing improvements of up to 24\% KLD, 21\% LPIPS, and 62\% AP$_{50-95}$, respectively.
BVI-RLV: A Fully Registered Dataset and Benchmarks for Low-Light Video Enhancement
Jul 03, 2024
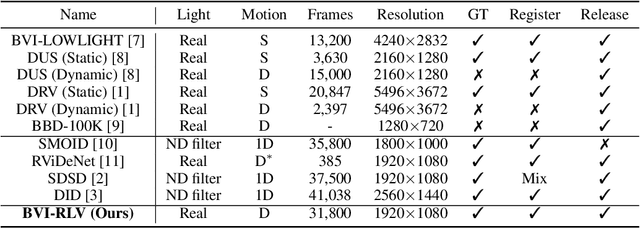
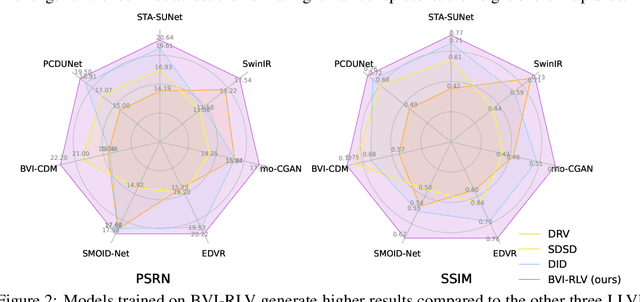
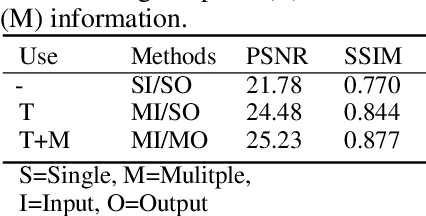
Low-light videos often exhibit spatiotemporal incoherent noise, compromising visibility and performance in computer vision applications. One significant challenge in enhancing such content using deep learning is the scarcity of training data. This paper introduces a novel low-light video dataset, consisting of 40 scenes with various motion scenarios under two distinct low-lighting conditions, incorporating genuine noise and temporal artifacts. We provide fully registered ground truth data captured in normal light using a programmable motorized dolly and refine it via an image-based approach for pixel-wise frame alignment across different light levels. We provide benchmarks based on four different technologies: convolutional neural networks, transformers, diffusion models, and state space models (mamba). Our experimental results demonstrate the significance of fully registered video pairs for low-light video enhancement (LLVE) and the comprehensive evaluation shows that the models trained with our dataset outperform those trained with the existing datasets. Our dataset and links to benchmarks are publicly available at https://doi.org/10.21227/mzny-8c77.
Feature Denoising For Low-Light Instance Segmentation Using Weighted Non-Local Blocks
Feb 28, 2024Instance segmentation for low-light imagery remains largely unexplored due to the challenges imposed by such conditions, for example shot noise due to low photon count, color distortions and reduced contrast. In this paper, we propose an end-to-end solution to address this challenging task. Based on Mask R-CNN, our proposed method implements weighted non-local (NL) blocks in the feature extractor. This integration enables an inherent denoising process at the feature level. As a result, our method eliminates the need for aligned ground truth images during training, thus supporting training on real-world low-light datasets. We introduce additional learnable weights at each layer in order to enhance the network's adaptability to real-world noise characteristics, which affect different feature scales in different ways. Experimental results show that the proposed method outperforms the pretrained Mask R-CNN with an Average Precision (AP) improvement of +10.0, with the introduction of weighted NL Blocks further enhancing AP by +1.0.