 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePocketDVDNet: Realtime Video Denoising for Real Camera Noise
Jan 23, 2026Live video denoising under realistic, multi-component sensor noise remains challenging for applications such as autofocus, autonomous driving, and surveillance. We propose PocketDVDNet, a lightweight video denoiser developed using our model compression framework that combines sparsity-guided structured pruning, a physics-informed noise model, and knowledge distillation to achieve high-quality restoration with reduced resource demands. Starting from a reference model, we induce sparsity, apply targeted channel pruning, and retrain a teacher on realistic multi-component noise. The student network learns implicit noise handling, eliminating the need for explicit noise-map inputs. PocketDVDNet reduces the original model size by 74% while improving denoising quality and processing 5-frame patches in real-time. These results demonstrate that aggressive compression, combined with domain-adapted distillation, can reconcile performance and efficiency for practical, real-time video denoising.
Towards a General-Purpose Zero-Shot Synthetic Low-Light Image and Video Pipeline
Apr 16, 2025



Low-light conditions pose significant challenges for both human and machine annotation. This in turn has led to a lack of research into machine understanding for low-light images and (in particular) videos. A common approach is to apply annotations obtained from high quality datasets to synthetically created low light versions. In addition, these approaches are often limited through the use of unrealistic noise models. In this paper, we propose a new Degradation Estimation Network (DEN), which synthetically generates realistic standard RGB (sRGB) noise without the requirement for camera metadata. This is achieved by estimating the parameters of physics-informed noise distributions, trained in a self-supervised manner. This zero-shot approach allows our method to generate synthetic noisy content with a diverse range of realistic noise characteristics, unlike other methods which focus on recreating the noise characteristics of the training data. We evaluate our proposed synthetic pipeline using various methods trained on its synthetic data for typical low-light tasks including synthetic noise replication, video enhancement, and object detection, showing improvements of up to 24\% KLD, 21\% LPIPS, and 62\% AP$_{50-95}$, respectively.
DaBiT: Depth and Blur informed Transformer for Joint Refocusing and Super-Resolution
Jul 01, 2024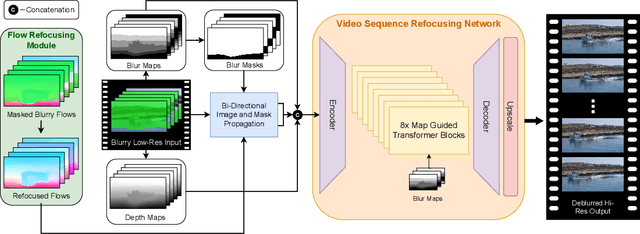
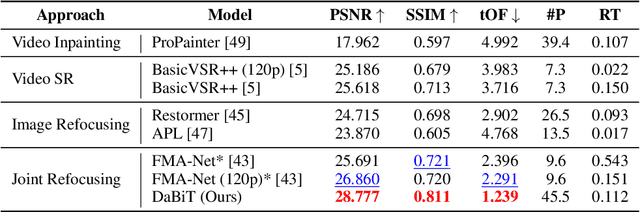
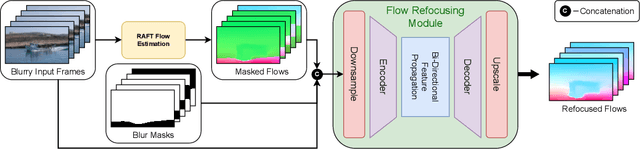

In many real-world scenarios, recorded videos suffer from accidental focus blur, and while video deblurring methods exist, most specifically target motion blur. This paper introduces a framework optimised for the joint task of focal deblurring (refocusing) and video super-resolution (VSR). The proposed method employs novel map guided transformers, in addition to image propagation, to effectively leverage the continuous spatial variance of focal blur and restore the footage. We also introduce a flow re-focusing module to efficiently align relevant features between the blurry and sharp domains. Additionally, we propose a novel technique for generating synthetic focal blur data, broadening the model's learning capabilities to include a wider array of content. We have made a new benchmark dataset, DAVIS-Blur, available. This dataset, a modified extension of the popular DAVIS video segmentation set, provides realistic out-of-focus blur degradations as well as the corresponding blur maps. Comprehensive experiments on DAVIS-Blur demonstrate the superiority of our approach. We achieve state-of-the-art results with an average PSNR performance over 1.9dB greater than comparable existing video restoration methods. Our source code will be made available at https://github.com/crispianm/DaBiT
ST-MFNet Mini: Knowledge Distillation-Driven Frame Interpolation
Feb 23, 2023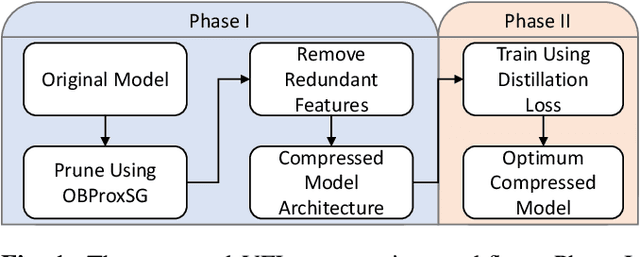
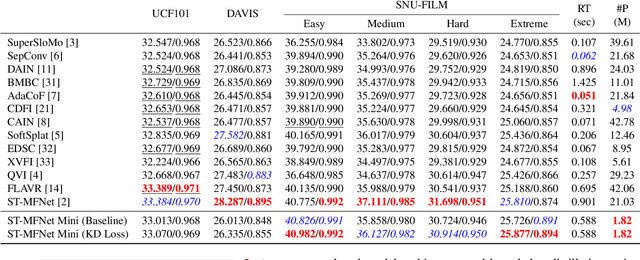
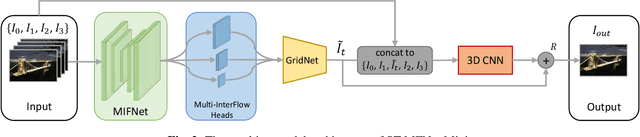

Currently, one of the major challenges in deep learning-based video frame interpolation (VFI) is the large model sizes and high computational complexity associated with many high performance VFI approaches. In this paper, we present a distillation-based two-stage workflow for obtaining compressed VFI models which perform competitively to the state of the arts, at a greatly reduced model size and complexity. Specifically, an optimisation-based network pruning method is first applied to a recently proposed frame interpolation model, ST-MFNet, which outperforms many other VFI methods but suffers from large model size. The resulting new network architecture achieves a 91% reduction in parameters and 35% increase in speed. Secondly, the performance of the new network is further enhanced through a teacher-student knowledge distillation training process using a Laplacian distillation loss. The final low complexity model, ST-MFNet Mini, achieves a comparable performance to most existing high-complex VFI methods, only outperformed by the original ST-MFNet. Our source code is available at https://github.com/crispianm/ST-MFNet-Mini