 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBVI-Mamba: Video Enhancement Using a Visual State-Space Model for Low-Light and Underwater Environments
Apr 26, 2026Videos captured in low-light and underwater conditions often suffer from distortions such as noise, low contrast, color imbalance, and blur. These issues not only limit visibility but also degrade automatic tasks like detection. Post-processing is typically required but can be time-consuming. AI-based tools for video enhancement also demand significantly more computational resources compared to image-based methods. This paper introduces a novel framework, Visual Mamba, designed to reduce memory usage and computational time by leveraging the Visual State Space (VSS) model. The framework consists of two modules: (i) a feature alignment module, where spatio-temporal displacement between input frames is registered in the feature space, and (ii) an enhancement module, where noise removal and brightness adjustment are performed using a UNet-like architecture, with all convolutional layers replaced by VSS blocks. Experimental results show that the Visual Mamba technique outperforms Transformer and convolution-based models in both low-light and underwater video enhancement tasks. Code is available on line at https://github.com/russellllaputa/BVI-Mamba.
PocketDVDNet: Realtime Video Denoising for Real Camera Noise
Jan 23, 2026Live video denoising under realistic, multi-component sensor noise remains challenging for applications such as autofocus, autonomous driving, and surveillance. We propose PocketDVDNet, a lightweight video denoiser developed using our model compression framework that combines sparsity-guided structured pruning, a physics-informed noise model, and knowledge distillation to achieve high-quality restoration with reduced resource demands. Starting from a reference model, we induce sparsity, apply targeted channel pruning, and retrain a teacher on realistic multi-component noise. The student network learns implicit noise handling, eliminating the need for explicit noise-map inputs. PocketDVDNet reduces the original model size by 74% while improving denoising quality and processing 5-frame patches in real-time. These results demonstrate that aggressive compression, combined with domain-adapted distillation, can reconcile performance and efficiency for practical, real-time video denoising.
ST-MFNet Mini: Knowledge Distillation-Driven Frame Interpolation
Feb 23, 2023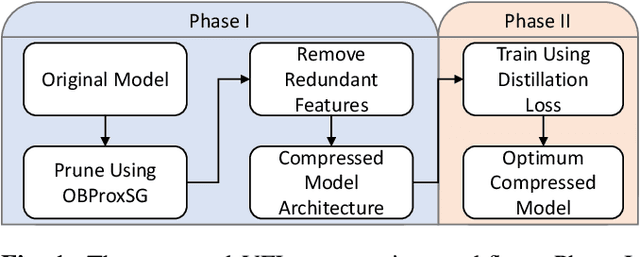
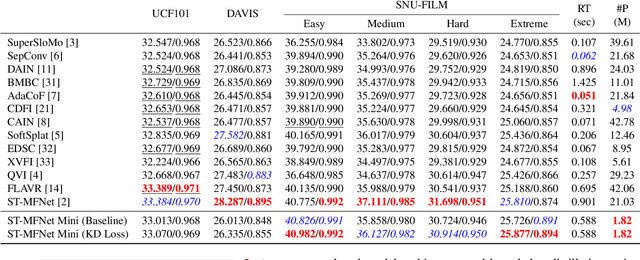

Currently, one of the major challenges in deep learning-based video frame interpolation (VFI) is the large model sizes and high computational complexity associated with many high performance VFI approaches. In this paper, we present a distillation-based two-stage workflow for obtaining compressed VFI models which perform competitively to the state of the arts, at a greatly reduced model size and complexity. Specifically, an optimisation-based network pruning method is first applied to a recently proposed frame interpolation model, ST-MFNet, which outperforms many other VFI methods but suffers from large model size. The resulting new network architecture achieves a 91% reduction in parameters and 35% increase in speed. Secondly, the performance of the new network is further enhanced through a teacher-student knowledge distillation training process using a Laplacian distillation loss. The final low complexity model, ST-MFNet Mini, achieves a comparable performance to most existing high-complex VFI methods, only outperformed by the original ST-MFNet. Our source code is available at https://github.com/crispianm/ST-MFNet-Mini
Deep VQA based on a Novel Hybrid Training Methodology
Feb 17, 2022In recent years, deep learning techniques have been widely applied to video quality assessment (VQA), showing significant potential to achieve higher correlation performance with subjective opinions compared to conventional approaches. However, these methods are often developed based on limited training materials and evaluated through cross validation, due to the lack of large scale subjective databases. In this context, this paper proposes a new hybrid training methodology, which generates large volumes of training data by using quality indices from an existing perceptual quality metric, VMAF, as training targets, instead of actual subjective opinion scores. An additional shallow CNN is also employed for temporal pooling, which was trained based on a small subjective video database. The resulting Deep Video Quality Metric (based on Hybrid Training), DVQM-HT, has been fully tested on eight HD subjective video databases, and consistently exhibits higher correlation with perceptual quality compared to other deep quality assessment methods, with an average SROCC value of 0.8263.
Perceptually-inspired super-resolution of compressed videos
Jun 15, 2021Spatial resolution adaptation is a technique which has often been employed in video compression to enhance coding efficiency. This approach encodes a lower resolution version of the input video and reconstructs the original resolution during decoding. Instead of using conventional up-sampling filters, recent work has employed advanced super-resolution methods based on convolutional neural networks (CNNs) to further improve reconstruction quality. These approaches are usually trained to minimise pixel-based losses such as Mean-Squared Error (MSE), despite the fact that this type of loss metric does not correlate well with subjective opinions. In this paper, a perceptually-inspired super-resolution approach (M-SRGAN) is proposed for spatial up-sampling of compressed video using a modified CNN model, which has been trained using a generative adversarial network (GAN) on compressed content with perceptual loss functions. The proposed method was integrated with HEVC HM 16.20, and has been evaluated on the JVET Common Test Conditions (UHD test sequences) using the Random Access configuration. The results show evident perceptual quality improvement over the original HM 16.20, with an average bitrate saving of 35.6% (Bj{\o}ntegaard Delta measurement) based on a perceptual quality metric, VMAF.
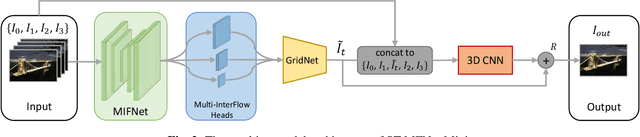
An adaptive Lagrange multiplier determination method for rate-distortion optimisation in hybrid video codecs
Jun 15, 2021

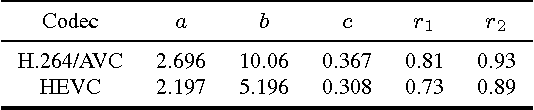

This paper describes an adaptive Lagrange multiplier determination method for rate-quality optimisation in video compression. Inspired by the experimental results of a Lagrange multiplier selection test, the presented approach adaptively estimates the optimum Lagrange multiplier for different video content, based on distortion statistics of recently encoded frames. The proposed algorithm has been fully integrated into both the H.264 and HEVC reference codecs, and is used in rate-distortion optimisation for encoding B frames. The results show promising (up to 11% on the sequences tested) overall bitrate savings, for a minimal increase in complexity, on various types of test content based on Bjontegaard delta measurements.
Quality assessment methods for perceptual video compression
Jun 15, 2021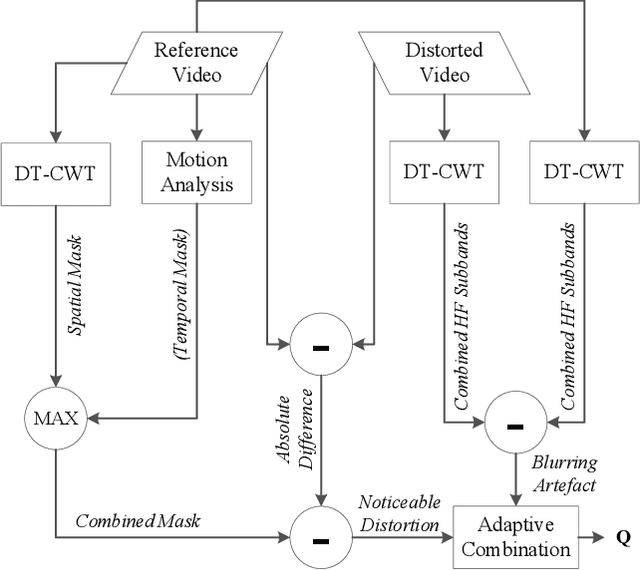
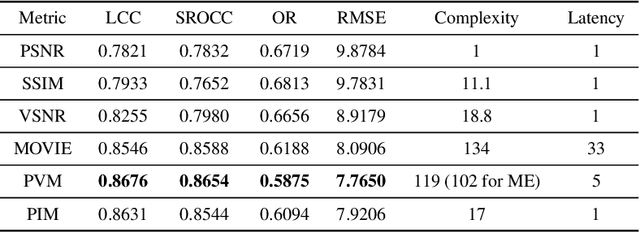
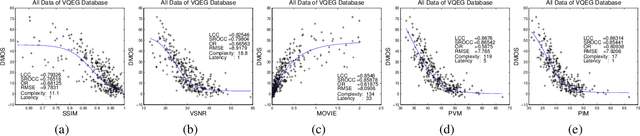
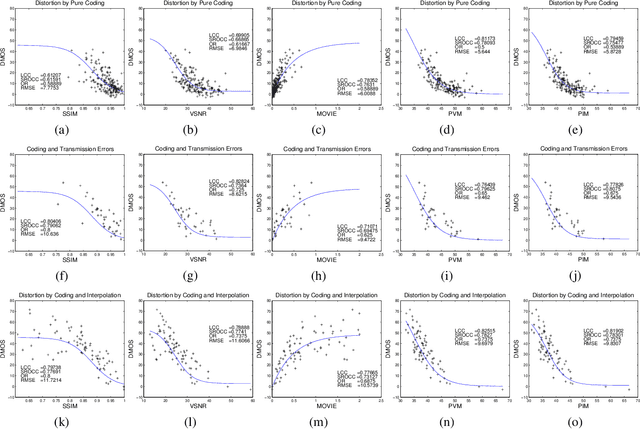
This paper describes a quality assessment model for perceptual video compression applications (PVM), which stimulates visual masking and distortion-artefact perception using an adaptive combination of noticeable distortions and blurring artefacts. The method shows significant improvement over existing quality metrics based on the VQEG database, and provides compatibility with in-loop rate-quality optimisation for next generation video codecs due to its latency and complexity attributes. Performance comparison are validated against a range of different distortion types.
VMAF-based Bitrate Ladder Estimation for Adaptive Streaming
Mar 12, 2021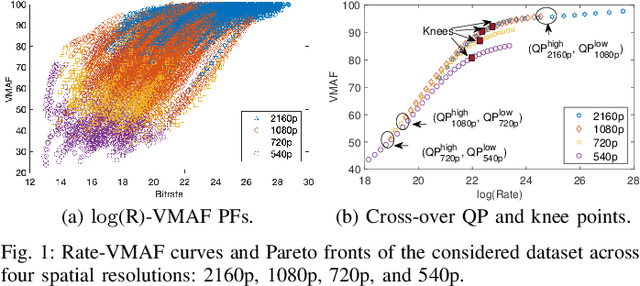
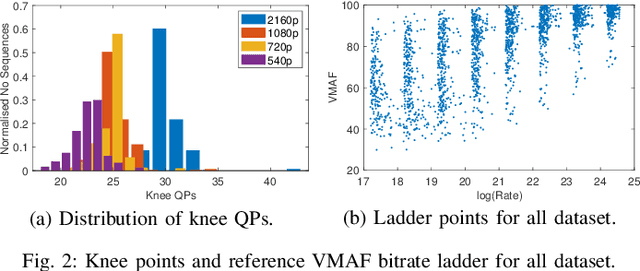
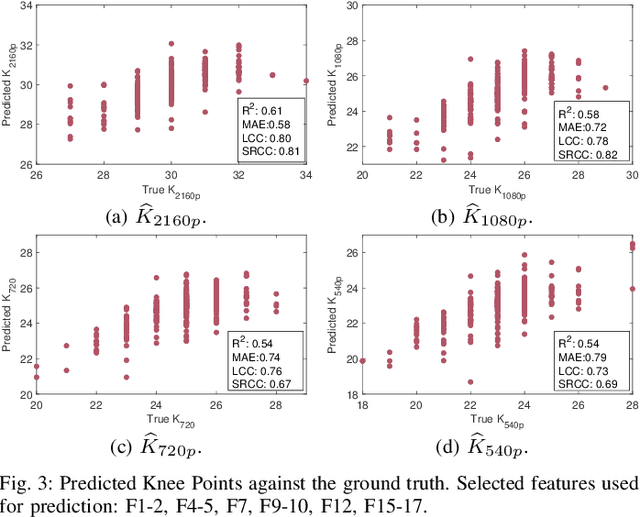
In HTTP Adaptive Streaming, video content is conventionally encoded by adapting its spatial resolution and quantization level to best match the prevailing network state and display characteristics. It is well known that the traditional solution, of using a fixed bitrate ladder, does not result in the highest quality of experience for the user. Hence, in this paper, we consider a content-driven approach for estimating the bitrate ladder, based on spatio-temporal features extracted from the uncompressed content. The method implements a content-driven interpolation. It uses the extracted features to train a machine learning model to infer the curvature points of the Rate-VMAF curves in order to guide a set of initial encodings. We employ the VMAF quality metric as a means of perceptually conditioning the estimation. When compared to exhaustive encoding that produces the reference ladder, the estimated ladder is composed by 74.3% of identical Rate-VMAF points with the reference ladder. The proposed method offers a significant reduction of the number of encodes required, 77.4%, at a small average Bj{\o}ntegaard Delta Rate cost, 1.12%.
Efficient Bitrate Ladder Construction for Content-Optimized Adaptive Video Streaming
Feb 08, 2021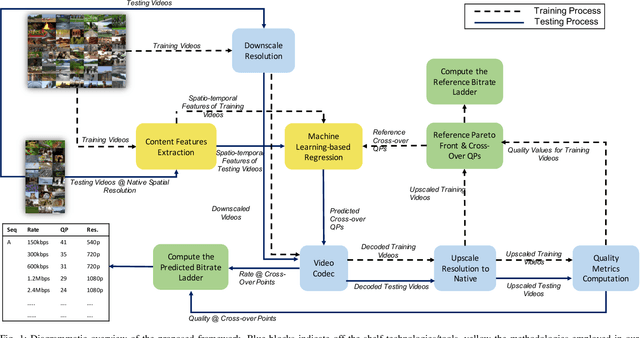
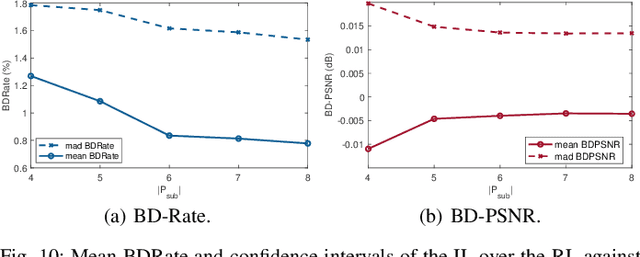

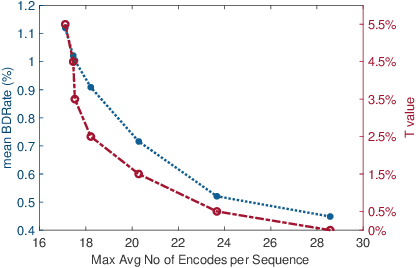
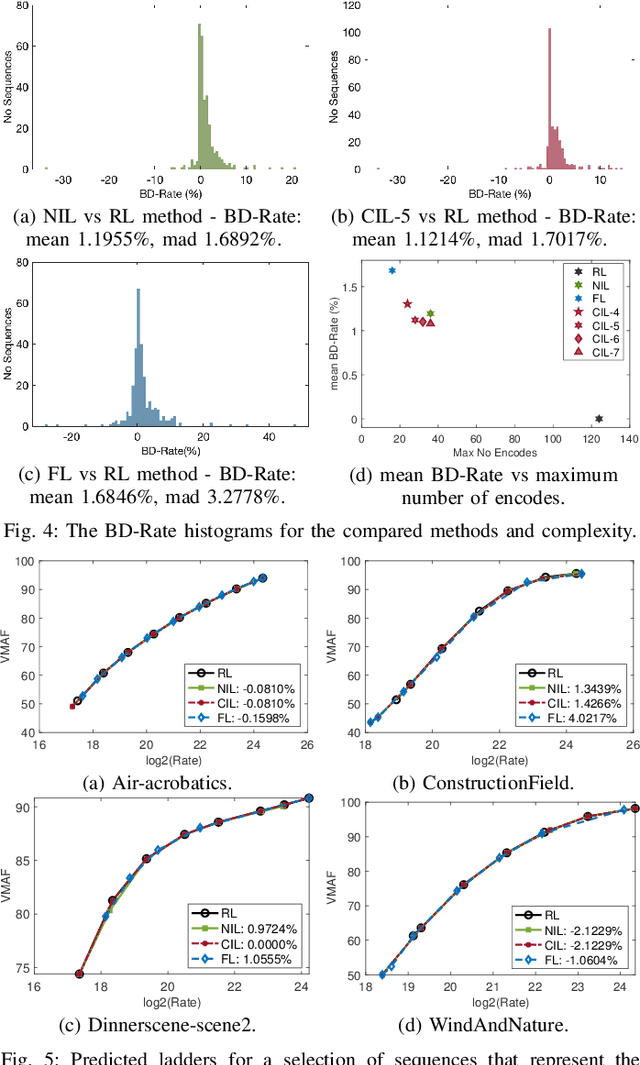
One of the challenges faced by many video providers is the heterogeneity of network specifications, user requirements, and content compression performance. The universal solution of a fixed bitrate ladder is inadequate in ensuring a high quality of user experience without re-buffering or introducing annoying compression artifacts. However, a content-tailored solution, based on extensively encoding across all resolutions and over a wide quality range is highly expensive in terms of computational, financial, and energy costs. Inspired by this, we propose an approach that exploits machine learning to predict a content-optimized bitrate ladder. The method extracts spatio-temporal features from the uncompressed content, trains machine-learning models to predict the Pareto front parameters, and, based on that, builds the ladder within a defined bitrate range. The method has the benefit of significantly reducing the number of encodes required per sequence. The presented results, based on 100 HEVC-encoded sequences, demonstrate a reduction in the number of encodes required when compared to an exhaustive search and an interpolation-based method, by 89.06% and 61.46%, respectively, at the cost of an average Bj{\o}ntegaard Delta Rate difference of 1.78% compared to the exhaustive approach. Finally, a hybrid method is introduced that selects either the proposed or the interpolation-based method depending on the sequence features. This results in an overall 83.83% reduction of required encodings at the cost of an average Bj{\o}ntegaard Delta Rate difference of 1.26%.
Study of Compression Statistics and Prediction of Rate-Distortion Curves for Video Texture
Feb 08, 2021
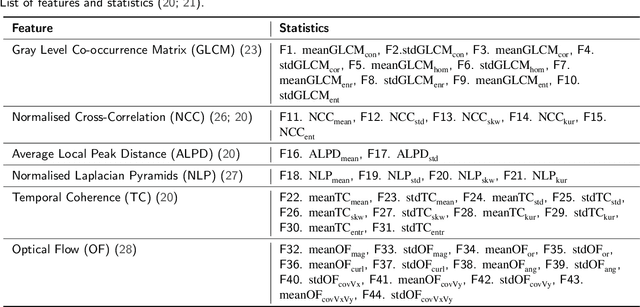
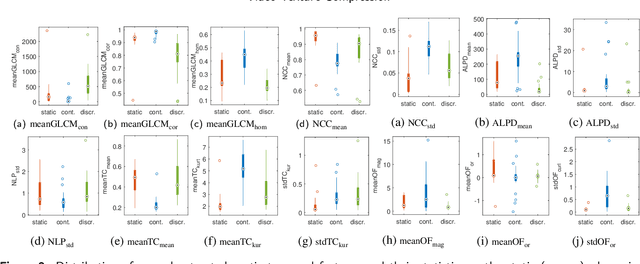
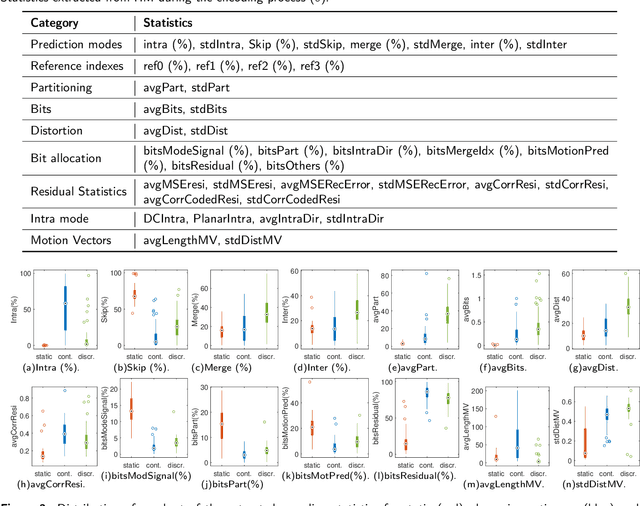
Encoding textural content remains a challenge for current standardised video codecs. It is therefore beneficial to understand video textures in terms of both their spatio-temporal characteristics and their encoding statistics in order to optimize encoding performance. In this paper, we analyse the spatio-temporal features and statistics of video textures, explore the rate-quality performance of different texture types and investigate models to mathematically describe them. For all considered theoretical models, we employ machine-learning regression to predict the rate-quality curves based solely on selected spatio-temporal features extracted from uncompressed content. All experiments were performed on homogeneous video textures to ensure validity of the observations. The results of the regression indicate that using an exponential model we can more accurately predict the expected rate-quality curve (with a mean Bj{\o}ntegaard Delta rate of 0.46% over the considered dataset) while maintaining a low relative complexity. This is expected to be adopted by in the loop processes for faster encoding decisions such as rate-distortion optimisation, adaptive quantization, partitioning, etc.