 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVMAF-based Bitrate Ladder Estimation for Adaptive Streaming
Mar 12, 2021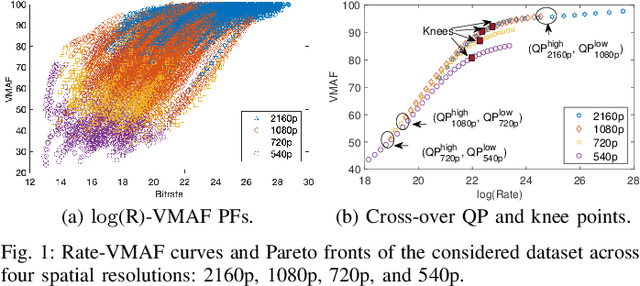
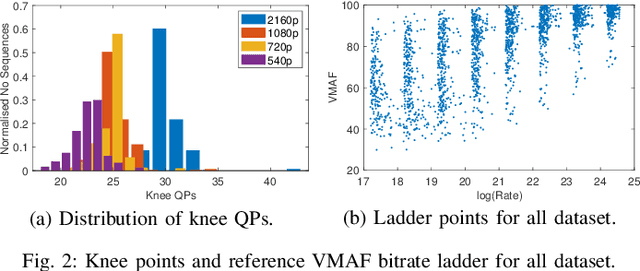
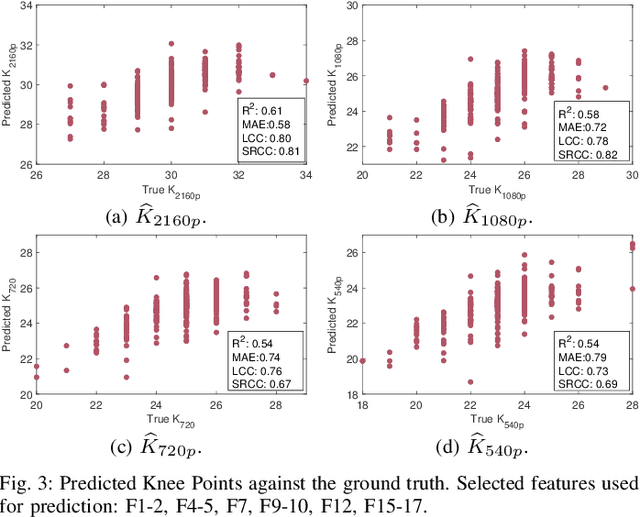
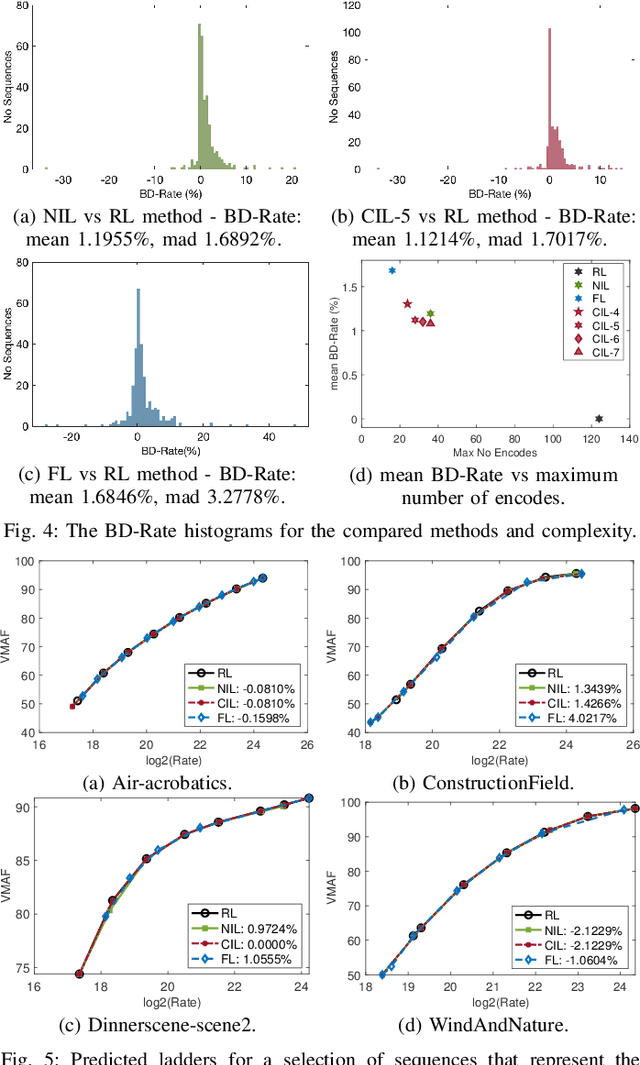
In HTTP Adaptive Streaming, video content is conventionally encoded by adapting its spatial resolution and quantization level to best match the prevailing network state and display characteristics. It is well known that the traditional solution, of using a fixed bitrate ladder, does not result in the highest quality of experience for the user. Hence, in this paper, we consider a content-driven approach for estimating the bitrate ladder, based on spatio-temporal features extracted from the uncompressed content. The method implements a content-driven interpolation. It uses the extracted features to train a machine learning model to infer the curvature points of the Rate-VMAF curves in order to guide a set of initial encodings. We employ the VMAF quality metric as a means of perceptually conditioning the estimation. When compared to exhaustive encoding that produces the reference ladder, the estimated ladder is composed by 74.3% of identical Rate-VMAF points with the reference ladder. The proposed method offers a significant reduction of the number of encodes required, 77.4%, at a small average Bj{\o}ntegaard Delta Rate cost, 1.12%.
Efficient Bitrate Ladder Construction for Content-Optimized Adaptive Video Streaming
Feb 08, 2021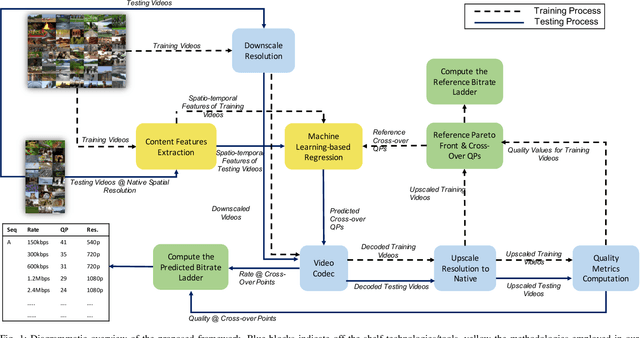
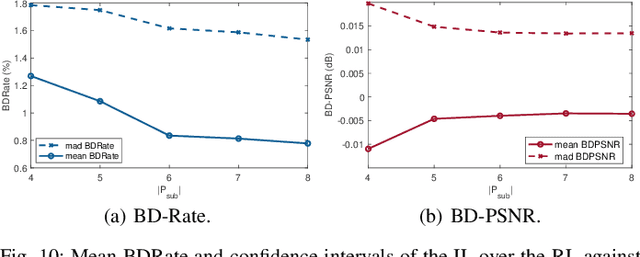

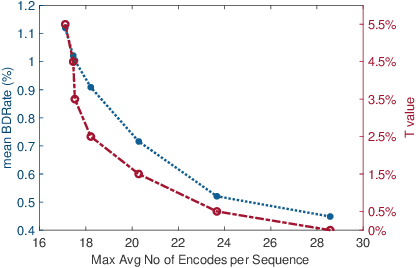
One of the challenges faced by many video providers is the heterogeneity of network specifications, user requirements, and content compression performance. The universal solution of a fixed bitrate ladder is inadequate in ensuring a high quality of user experience without re-buffering or introducing annoying compression artifacts. However, a content-tailored solution, based on extensively encoding across all resolutions and over a wide quality range is highly expensive in terms of computational, financial, and energy costs. Inspired by this, we propose an approach that exploits machine learning to predict a content-optimized bitrate ladder. The method extracts spatio-temporal features from the uncompressed content, trains machine-learning models to predict the Pareto front parameters, and, based on that, builds the ladder within a defined bitrate range. The method has the benefit of significantly reducing the number of encodes required per sequence. The presented results, based on 100 HEVC-encoded sequences, demonstrate a reduction in the number of encodes required when compared to an exhaustive search and an interpolation-based method, by 89.06% and 61.46%, respectively, at the cost of an average Bj{\o}ntegaard Delta Rate difference of 1.78% compared to the exhaustive approach. Finally, a hybrid method is introduced that selects either the proposed or the interpolation-based method depending on the sequence features. This results in an overall 83.83% reduction of required encodings at the cost of an average Bj{\o}ntegaard Delta Rate difference of 1.26%.
Study of Compression Statistics and Prediction of Rate-Distortion Curves for Video Texture
Feb 08, 2021
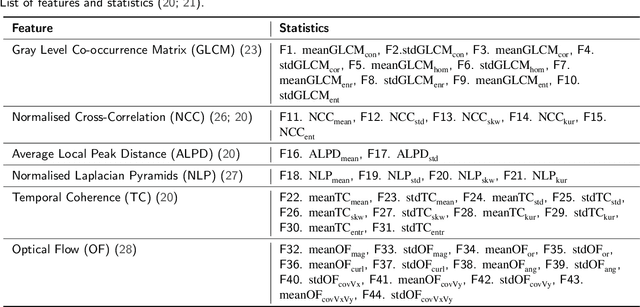
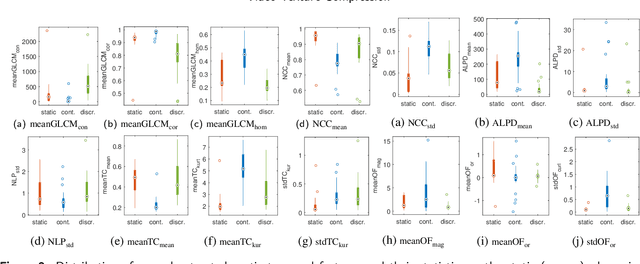
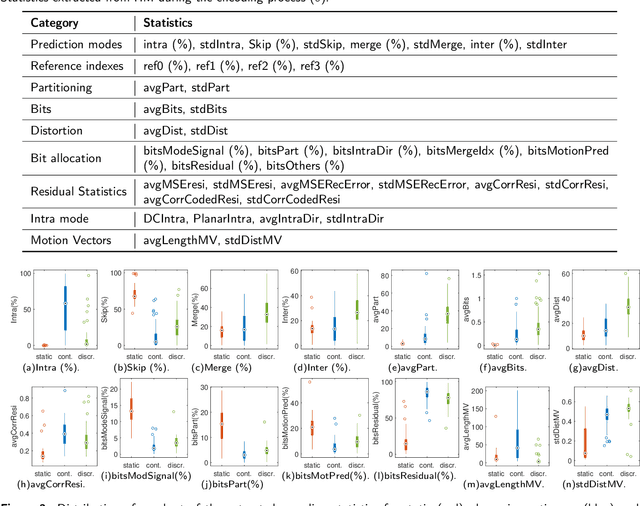
Encoding textural content remains a challenge for current standardised video codecs. It is therefore beneficial to understand video textures in terms of both their spatio-temporal characteristics and their encoding statistics in order to optimize encoding performance. In this paper, we analyse the spatio-temporal features and statistics of video textures, explore the rate-quality performance of different texture types and investigate models to mathematically describe them. For all considered theoretical models, we employ machine-learning regression to predict the rate-quality curves based solely on selected spatio-temporal features extracted from uncompressed content. All experiments were performed on homogeneous video textures to ensure validity of the observations. The results of the regression indicate that using an exponential model we can more accurately predict the expected rate-quality curve (with a mean Bj{\o}ntegaard Delta rate of 0.46% over the considered dataset) while maintaining a low relative complexity. This is expected to be adopted by in the loop processes for faster encoding decisions such as rate-distortion optimisation, adaptive quantization, partitioning, etc.