 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanding vs. Quality: Perceptual Impact and Objective Assessment
Feb 22, 2022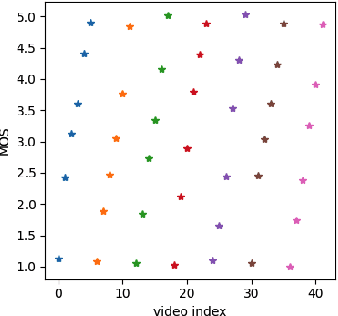
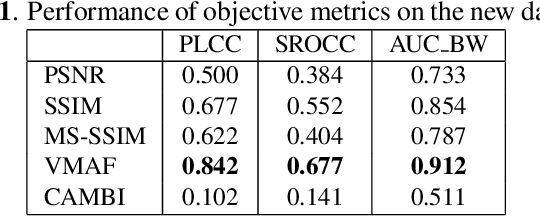
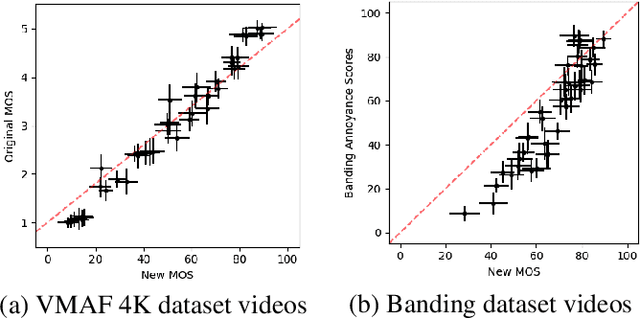
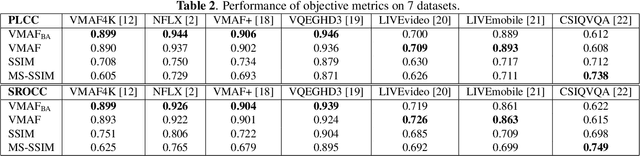
Staircase-like contours introduced to a video by quantization in flat areas, commonly known as banding, have been a long-standing problem in both video processing and quality assessment communities. The fact that even a relatively small change of the original pixel values can result in a strong impact on perceived quality makes banding especially difficult to be detected by objective quality metrics. In this paper, we study how banding annoyance compares to more commonly studied scaling and compression artifacts with respect to the overall perceptual quality. We further propose a simple combination of VMAF and the recently developed banding index, CAMBI, into a banding-aware video quality metric showing improved correlation with overall perceived quality.
Perceptually-inspired super-resolution of compressed videos
Jun 15, 2021Spatial resolution adaptation is a technique which has often been employed in video compression to enhance coding efficiency. This approach encodes a lower resolution version of the input video and reconstructs the original resolution during decoding. Instead of using conventional up-sampling filters, recent work has employed advanced super-resolution methods based on convolutional neural networks (CNNs) to further improve reconstruction quality. These approaches are usually trained to minimise pixel-based losses such as Mean-Squared Error (MSE), despite the fact that this type of loss metric does not correlate well with subjective opinions. In this paper, a perceptually-inspired super-resolution approach (M-SRGAN) is proposed for spatial up-sampling of compressed video using a modified CNN model, which has been trained using a generative adversarial network (GAN) on compressed content with perceptual loss functions. The proposed method was integrated with HEVC HM 16.20, and has been evaluated on the JVET Common Test Conditions (UHD test sequences) using the Random Access configuration. The results show evident perceptual quality improvement over the original HM 16.20, with an average bitrate saving of 35.6% (Bj{\o}ntegaard Delta measurement) based on a perceptual quality metric, VMAF.
VMAF-based Bitrate Ladder Estimation for Adaptive Streaming
Mar 12, 2021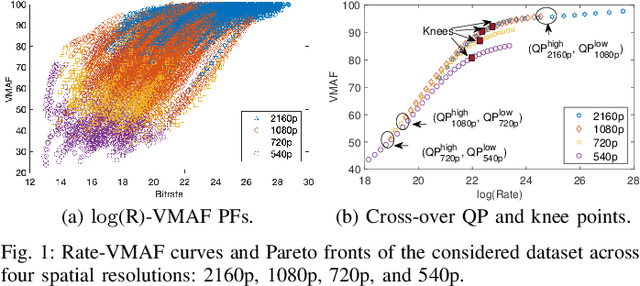
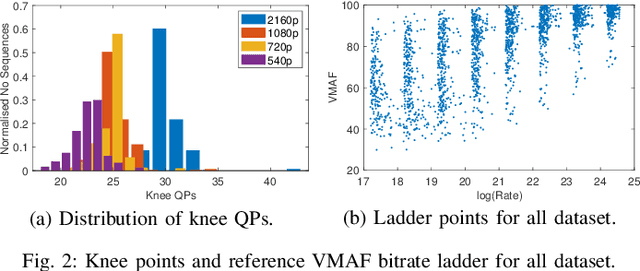
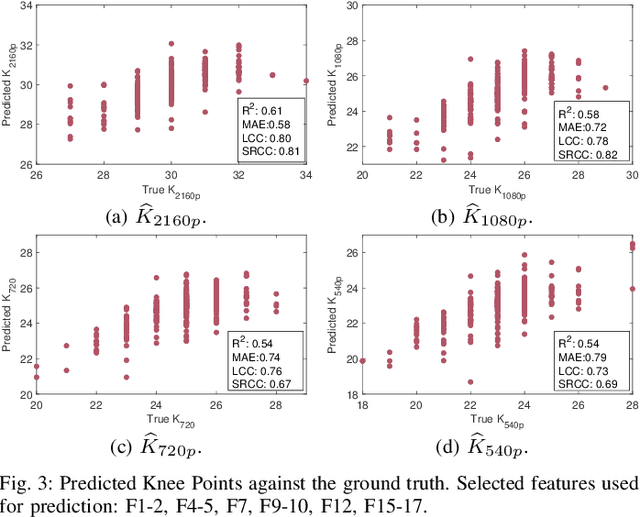
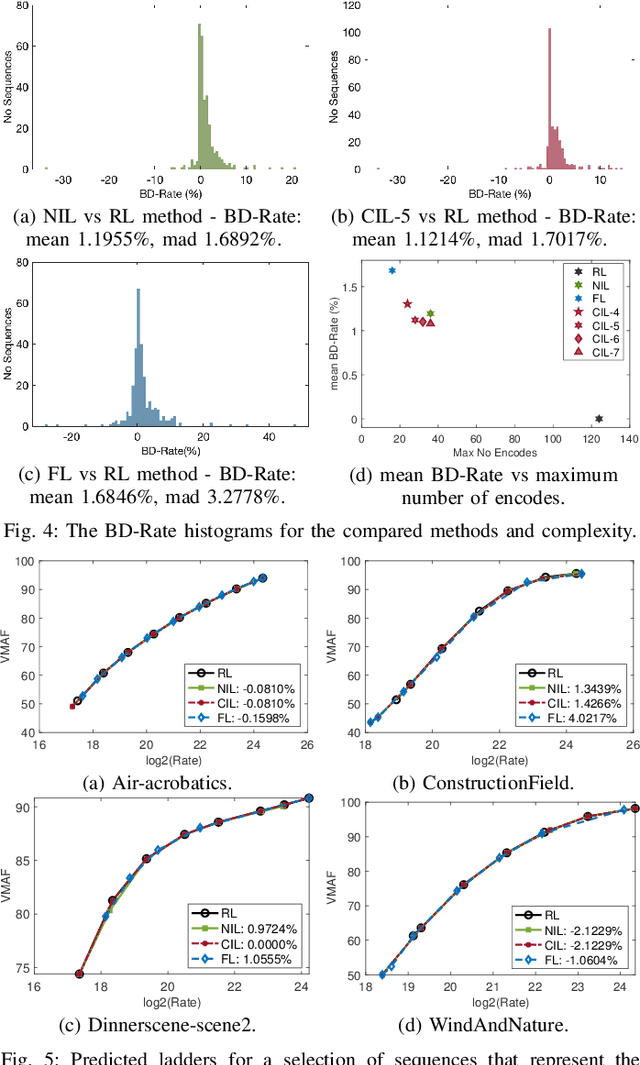
In HTTP Adaptive Streaming, video content is conventionally encoded by adapting its spatial resolution and quantization level to best match the prevailing network state and display characteristics. It is well known that the traditional solution, of using a fixed bitrate ladder, does not result in the highest quality of experience for the user. Hence, in this paper, we consider a content-driven approach for estimating the bitrate ladder, based on spatio-temporal features extracted from the uncompressed content. The method implements a content-driven interpolation. It uses the extracted features to train a machine learning model to infer the curvature points of the Rate-VMAF curves in order to guide a set of initial encodings. We employ the VMAF quality metric as a means of perceptually conditioning the estimation. When compared to exhaustive encoding that produces the reference ladder, the estimated ladder is composed by 74.3% of identical Rate-VMAF points with the reference ladder. The proposed method offers a significant reduction of the number of encodes required, 77.4%, at a small average Bj{\o}ntegaard Delta Rate cost, 1.12%.
Study of Compression Statistics and Prediction of Rate-Distortion Curves for Video Texture
Feb 08, 2021
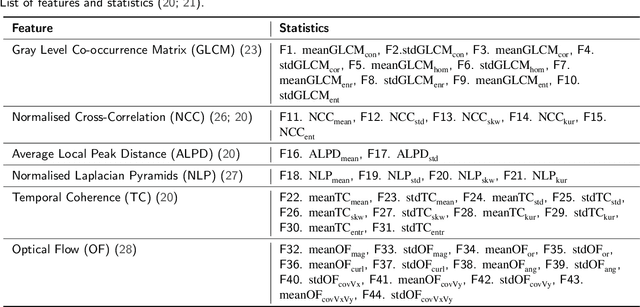
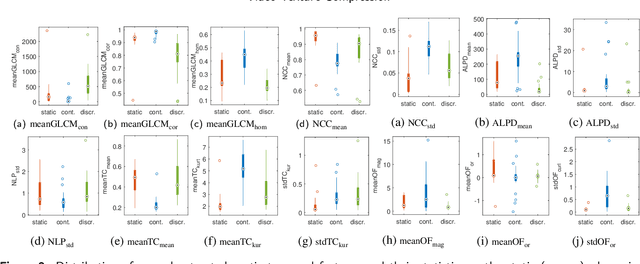
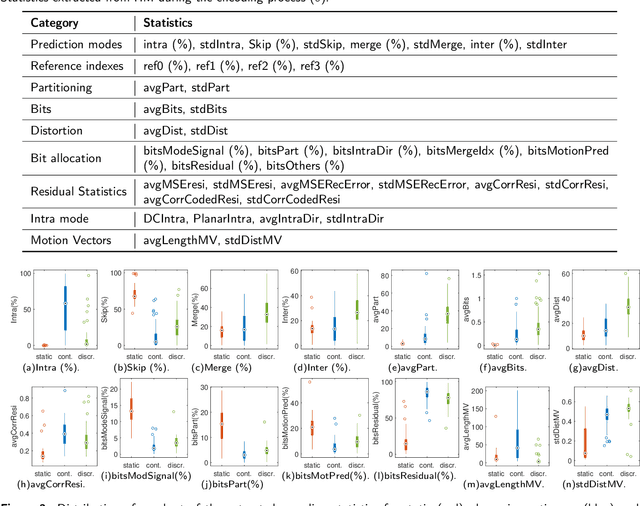
Encoding textural content remains a challenge for current standardised video codecs. It is therefore beneficial to understand video textures in terms of both their spatio-temporal characteristics and their encoding statistics in order to optimize encoding performance. In this paper, we analyse the spatio-temporal features and statistics of video textures, explore the rate-quality performance of different texture types and investigate models to mathematically describe them. For all considered theoretical models, we employ machine-learning regression to predict the rate-quality curves based solely on selected spatio-temporal features extracted from uncompressed content. All experiments were performed on homogeneous video textures to ensure validity of the observations. The results of the regression indicate that using an exponential model we can more accurately predict the expected rate-quality curve (with a mean Bj{\o}ntegaard Delta rate of 0.46% over the considered dataset) while maintaining a low relative complexity. This is expected to be adopted by in the loop processes for faster encoding decisions such as rate-distortion optimisation, adaptive quantization, partitioning, etc.
CAMBI: Contrast-aware Multiscale Banding Index
Jan 29, 2021
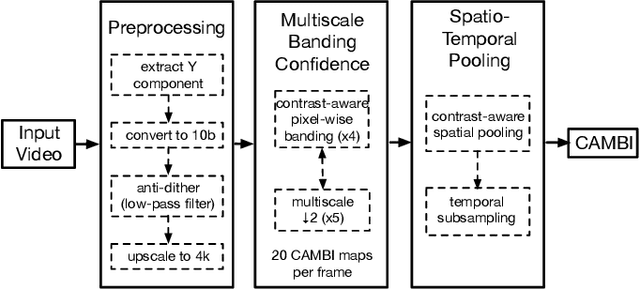
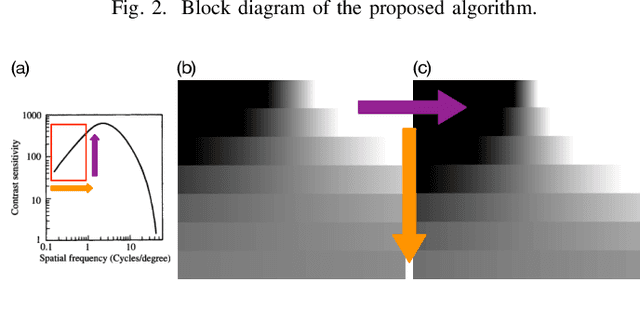
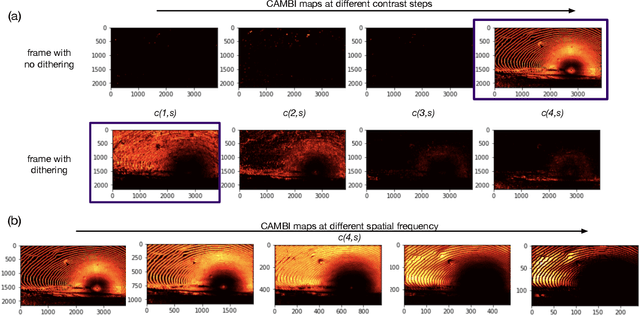
Banding artifacts are artificially-introduced contours arising from the quantization of a smooth region in a video. Despite the advent of recent higher quality video systems with more efficient codecs, these artifacts remain conspicuous, especially on larger displays. In this work, a comprehensive subjective study is performed to understand the dependence of the banding visibility on encoding parameters and dithering. We subsequently develop a simple and intuitive no-reference banding index called CAMBI (Contrast-aware Multiscale Banding Index) which uses insights from Contrast Sensitivity Function in the Human Visual System to predict banding visibility. CAMBI correlates well with subjective perception of banding while using only a few visually-motivated hyperparameters.
ViSTRA2: Video Coding using Spatial Resolution and Effective Bit Depth Adaptation
Nov 07, 2019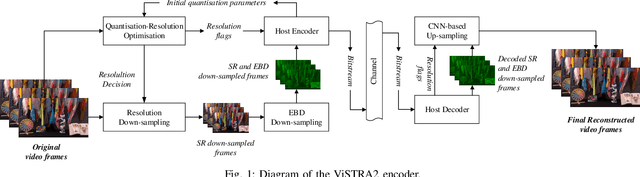
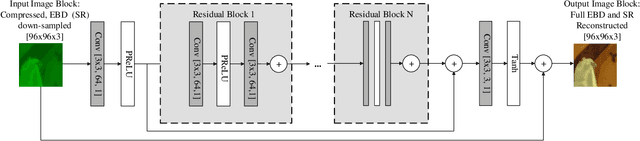
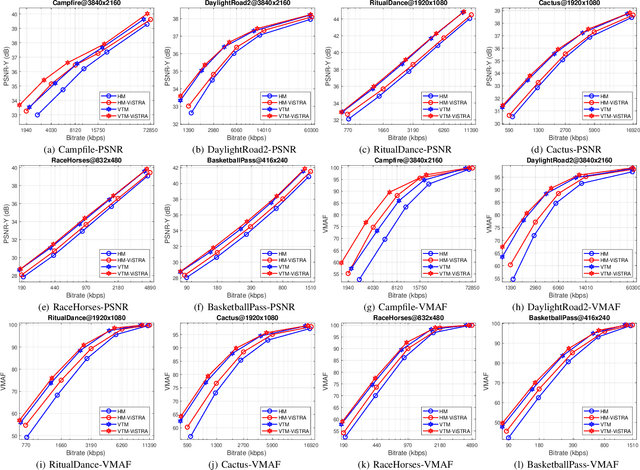

We present a new video compression framework (ViSTRA2) which exploits adaptation of spatial resolution and effective bit depth, down-sampling these parameters at the encoder based on perceptual criteria, and up-sampling at the decoder using a deep convolution neural network. ViSTRA2 has been integrated with the reference software of both the HEVC (HM 16.20) and VVC (VTM 4.01), and evaluated under the Joint Video Exploration Team Common Test Conditions using the Random Access configuration. Our results show consistent and significant compression gains against HM and VVC based on Bj{\o}negaard Delta measurements, with average BD-rate savings of 12.6% (PSNR) and 19.5% (VMAF) over HM and 5.5% (PSNR) and 8.6% (VMAF) over VTM.