 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIC-AB NET: A Neural Network for Image Captioning with Spatial Attention and Text Attributes
Jul 14, 2023Image captioning is a significant field across computer vision and natural language processing. We propose and present AIC-AB NET, a novel Attribute-Information-Combined Attention-Based Network that combines spatial attention architecture and text attributes in an encoder-decoder. For caption generation, adaptive spatial attention determines which image region best represents the image and whether to attend to the visual features or the visual sentinel. Text attribute information is synchronously fed into the decoder to help image recognition and reduce uncertainty. We have tested and evaluated our AICAB NET on the MS COCO dataset and a new proposed Fashion dataset. The Fashion dataset is employed as a benchmark of single-object images. The results show the superior performance of the proposed model compared to the state-of-the-art baseline and ablated models on both the images from MSCOCO and our single-object images. Our AIC-AB NET outperforms the baseline adaptive attention network by 0.017 (CIDEr score) on the MS COCO dataset and 0.095 (CIDEr score) on the Fashion dataset.
A Multi-task Neural Approach for Emotion Attribution, Classification and Summarization
Dec 21, 2018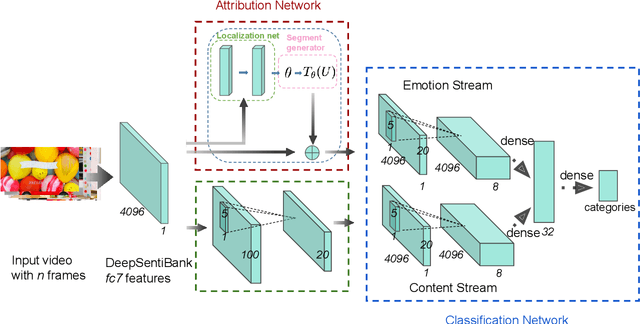
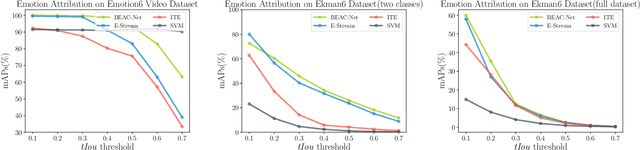
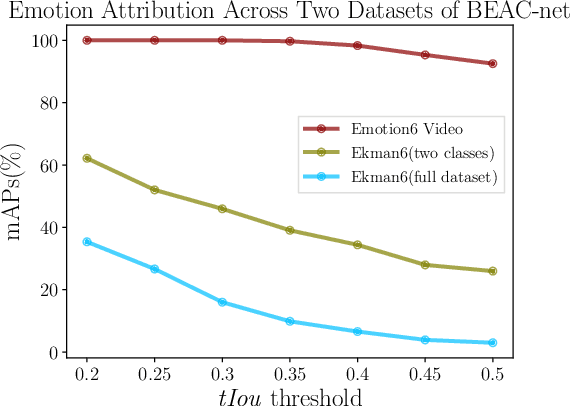

Emotional content is a crucial ingredient in user-generated videos. However, the sparsely expressed emotions in the user-generated video cause difficulties to emotions analysis in videos. In this paper, we propose a new neural approach---Bi-stream Emotion Attribution-Classification Network (BEAC-Net) to solve three related emotion analysis tasks: emotion recognition, emotion attribution and emotion-oriented summarization, in an integrated framework. BEAC-Net has two major constituents, an attribution network and a classification network. The attribution network extracts the main emotional segment that classification should focus on in order to mitigate the sparsity problem. The classification network utilizes both the extracted segment and the original video in a bi-stream architecture. We contribute a new dataset for the emotion attribution task with human-annotated ground-truth labels for emotion segments. Experiments on two video datasets demonstrate superior performance of the proposed framework and the complementary nature of the dual classification streams.