 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReject Threshold Adaptation for Open-Set Model Attribution of Deepfake Audio
Dec 02, 2024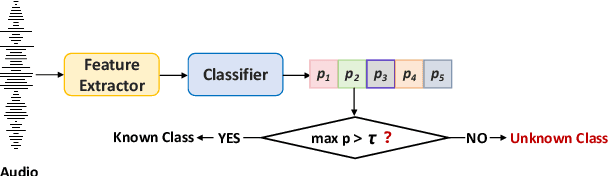

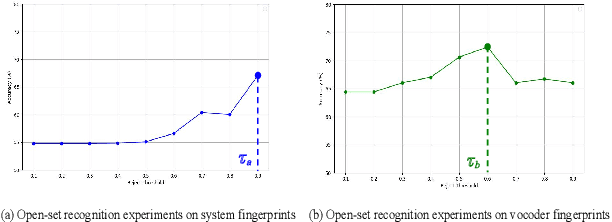

Open environment oriented open set model attribution of deepfake audio is an emerging research topic, aiming to identify the generation models of deepfake audio. Most previous work requires manually setting a rejection threshold for unknown classes to compare with predicted probabilities. However, models often overfit training instances and generate overly confident predictions. Moreover, thresholds that effectively distinguish unknown categories in the current dataset may not be suitable for identifying known and unknown categories in another data distribution. To address the issues, we propose a novel framework for open set model attribution of deepfake audio with rejection threshold adaptation (ReTA). Specifically, the reconstruction error learning module trains by combining the representation of system fingerprints with labels corresponding to either the target class or a randomly chosen other class label. This process generates matching and non-matching reconstructed samples, establishing the reconstruction error distributions for each class and laying the foundation for the reject threshold calculation module. The reject threshold calculation module utilizes gaussian probability estimation to fit the distributions of matching and non-matching reconstruction errors. It then computes adaptive reject thresholds for all classes through probability minimization criteria. The experimental results demonstrate the effectiveness of ReTA in improving the open set model attributes of deepfake audio.
WMCodec: End-to-End Neural Speech Codec with Deep Watermarking for Authenticity Verification
Sep 18, 2024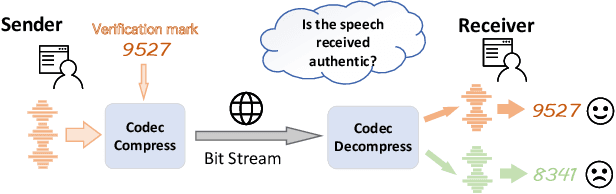
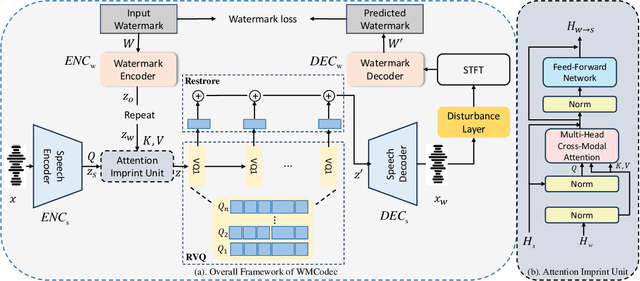
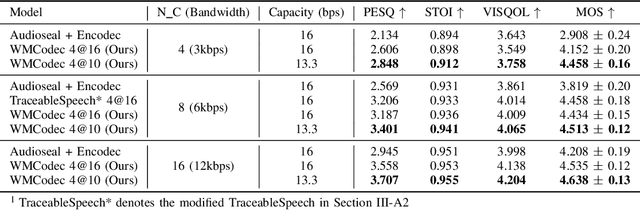
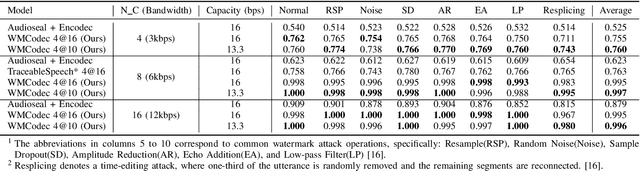
Recent advances in speech spoofing necessitate stronger verification mechanisms in neural speech codecs to ensure authenticity. Current methods embed numerical watermarks before compression and extract them from reconstructed speech for verification, but face limitations such as separate training processes for the watermark and codec, and insufficient cross-modal information integration, leading to reduced watermark imperceptibility, extraction accuracy, and capacity. To address these issues, we propose WMCodec, the first neural speech codec to jointly train compression-reconstruction and watermark embedding-extraction in an end-to-end manner, optimizing both imperceptibility and extractability of the watermark. Furthermore, We design an iterative Attention Imprint Unit (AIU) for deeper feature integration of watermark and speech, reducing the impact of quantization noise on the watermark. Experimental results show WMCodec outperforms AudioSeal with Encodec in most quality metrics for watermark imperceptibility and consistently exceeds both AudioSeal with Encodec and reinforced TraceableSpeech in extraction accuracy of watermark. At bandwidth of 6 kbps with a watermark capacity of 16 bps, WMCodec maintains over 99% extraction accuracy under common attacks, demonstrating strong robustness.
ADD 2023: Towards Audio Deepfake Detection and Analysis in the Wild
Aug 09, 2024



The growing prominence of the field of audio deepfake detection is driven by its wide range of applications, notably in protecting the public from potential fraud and other malicious activities, prompting the need for greater attention and research in this area. The ADD 2023 challenge goes beyond binary real/fake classification by emulating real-world scenarios, such as the identification of manipulated intervals in partially fake audio and determining the source responsible for generating any fake audio, both with real-life implications, notably in audio forensics, law enforcement, and construction of reliable and trustworthy evidence. To further foster research in this area, in this article, we describe the dataset that was used in the fake game, manipulation region location and deepfake algorithm recognition tracks of the challenge. We also focus on the analysis of the technical methodologies by the top-performing participants in each task and note the commonalities and differences in their approaches. Finally, we discuss the current technical limitations as identified through the technical analysis, and provide a roadmap for future research directions. The dataset is available for download.
TraceableSpeech: Towards Proactively Traceable Text-to-Speech with Watermarking
Jun 07, 2024



Various threats posed by the progress in text-to-speech (TTS) have prompted the need to reliably trace synthesized speech. However, contemporary approaches to this task involve adding watermarks to the audio separately after generation, a process that hurts both speech quality and watermark imperceptibility. In addition, these approaches are limited in robustness and flexibility. To address these problems, we propose TraceableSpeech, a novel TTS model that directly generates watermarked speech, improving watermark imperceptibility and speech quality. Furthermore, We design the frame-wise imprinting and extraction of watermarks, achieving higher robustness against resplicing attacks and temporal flexibility in operation. Experimental results show that TraceableSpeech outperforms the strong baseline where VALL-E or HiFicodec individually uses WavMark in watermark imperceptibility, speech quality and resilience against resplicing attacks. It also can apply to speech of various durations.
ADD 2023: the Second Audio Deepfake Detection Challenge
May 23, 2023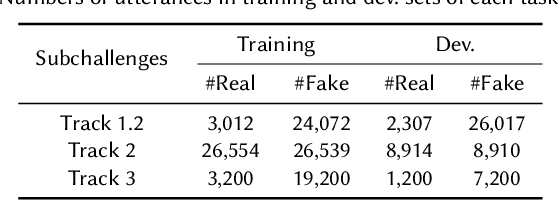
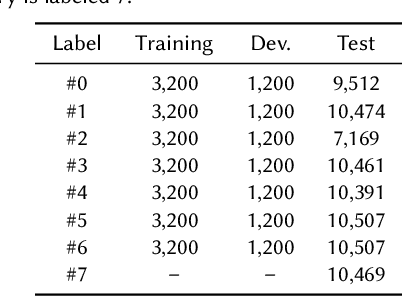
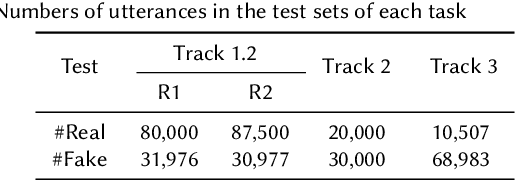

Audio deepfake detection is an emerging topic in the artificial intelligence community. The second Audio Deepfake Detection Challenge (ADD 2023) aims to spur researchers around the world to build new innovative technologies that can further accelerate and foster research on detecting and analyzing deepfake speech utterances. Different from previous challenges (e.g. ADD 2022), ADD 2023 focuses on surpassing the constraints of binary real/fake classification, and actually localizing the manipulated intervals in a partially fake speech as well as pinpointing the source responsible for generating any fake audio. Furthermore, ADD 2023 includes more rounds of evaluation for the fake audio game sub-challenge. The ADD 2023 challenge includes three subchallenges: audio fake game (FG), manipulation region location (RL) and deepfake algorithm recognition (AR). This paper describes the datasets, evaluation metrics, and protocols. Some findings are also reported in audio deepfake detection tasks.