Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Initial Investigation for Detecting Vocoder Fingerprints of Fake Audio
Paper and Code


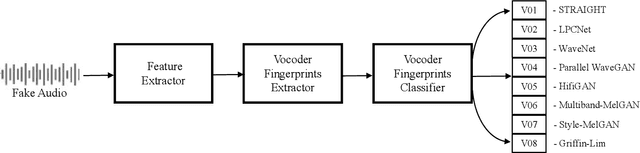
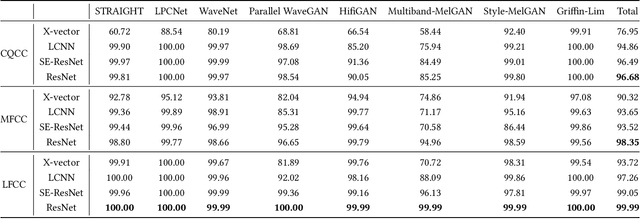
Many effective attempts have been made for fake audio detection. However, they can only provide detection results but no countermeasures to curb this harm. For many related practical applications, what model or algorithm generated the fake audio also is needed. Therefore, We propose a new problem for detecting vocoder fingerprints of fake audio. Experiments are conducted on the datasets synthesized by eight state-of-the-art vocoders. We have preliminarily explored the features and model architectures. The t-SNE visualization shows that different vocoders generate distinct vocoder fingerprints.
* Accepted by ACM Multimedia 2022 Workshop: First International
Workshop on Deepfake Detection for Audio Multimedia
View paper on