 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystem Fingerprints Detection for DeepFake Audio: An Initial Dataset and Investigation
Paper and Code
Aug 21, 2022
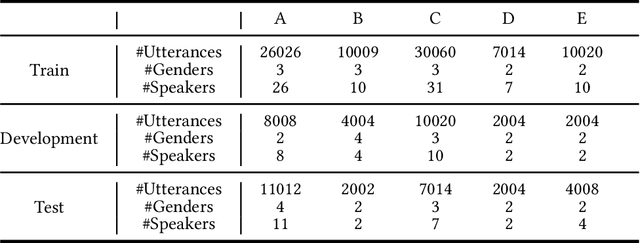
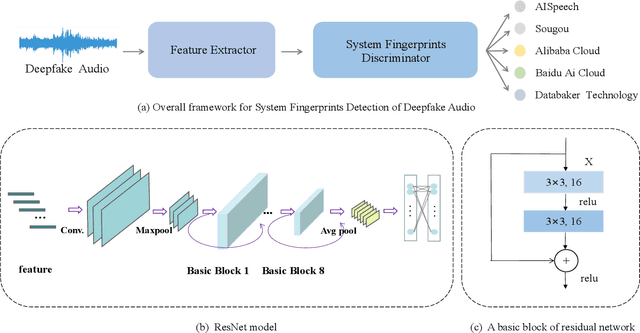
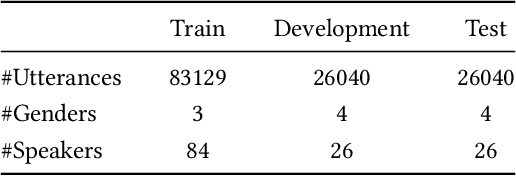
Many effective attempts have been made for deepfake audio detection. However, they can only distinguish between real and fake. For many practical application scenarios, what tool or algorithm generated the deepfake audio also is needed. This raises a question: Can we detect the system fingerprints of deepfake audio? Therefore, this paper conducts a preliminary investigation to detect system fingerprints of deepfake audio. Experiments are conducted on deepfake audio datasets from five latest deep-learning speech synthesis systems. The results show that LFCC features are relatively more suitable for system fingerprints detection. Moreover, the ResNet achieves the best detection results among LCNN and x-vector based models. The t-SNE visualization shows that different speech synthesis systems generate distinct system fingerprints.