 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Literature Review on Vehicular Collaborative Perception -- A Computer Vision Perspective
Apr 06, 2025The effectiveness of autonomous vehicles relies on reliable perception capabilities. Despite significant advancements in artificial intelligence and sensor fusion technologies, current single-vehicle perception systems continue to encounter limitations, notably visual occlusions and limited long-range detection capabilities. Collaborative Perception (CP), enabled by Vehicle-to-Vehicle (V2V) and Vehicle-to-Infrastructure (V2I) communication, has emerged as a promising solution to mitigate these issues and enhance the reliability of autonomous systems. Beyond advancements in communication, the computer vision community is increasingly focusing on improving vehicular perception through collaborative approaches. However, a systematic literature review that thoroughly examines existing work and reduces subjective bias is still lacking. Such a systematic approach helps identify research gaps, recognize common trends across studies, and inform future research directions. In response, this study follows the PRISMA 2020 guidelines and includes 106 peer-reviewed articles. These publications are analyzed based on modalities, collaboration schemes, and key perception tasks. Through a comparative analysis, this review illustrates how different methods address practical issues such as pose errors, temporal latency, communication constraints, domain shifts, heterogeneity, and adversarial attacks. Furthermore, it critically examines evaluation methodologies, highlighting a misalignment between current metrics and CP's fundamental objectives. By delving into all relevant topics in-depth, this review offers valuable insights into challenges, opportunities, and risks, serving as a reference for advancing research in vehicular collaborative perception.
CoDa-4DGS: Dynamic Gaussian Splatting with Context and Deformation Awareness for Autonomous Driving
Mar 09, 2025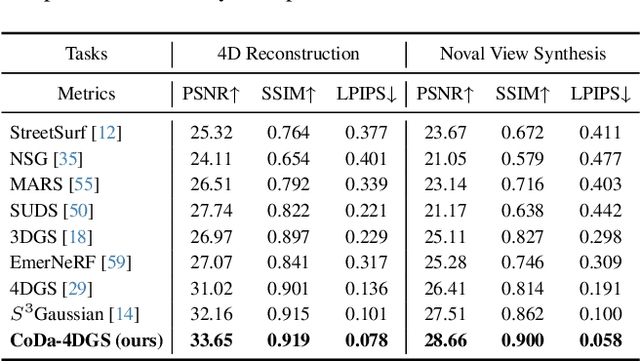
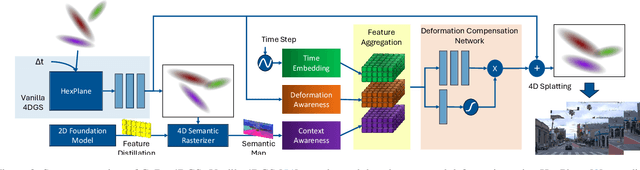
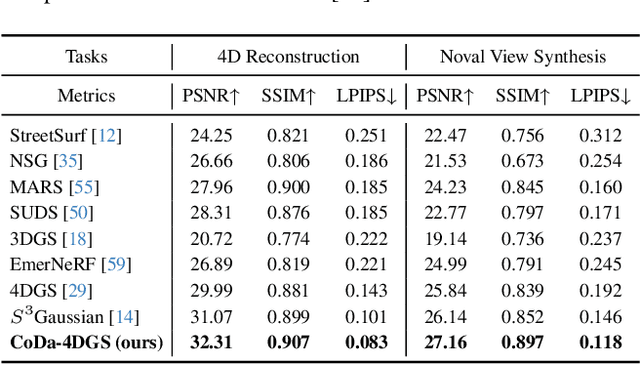

Dynamic scene rendering opens new avenues in autonomous driving by enabling closed-loop simulations with photorealistic data, which is crucial for validating end-to-end algorithms. However, the complex and highly dynamic nature of traffic environments presents significant challenges in accurately rendering these scenes. In this paper, we introduce a novel 4D Gaussian Splatting (4DGS) approach, which incorporates context and temporal deformation awareness to improve dynamic scene rendering. Specifically, we employ a 2D semantic segmentation foundation model to self-supervise the 4D semantic features of Gaussians, ensuring meaningful contextual embedding. Simultaneously, we track the temporal deformation of each Gaussian across adjacent frames. By aggregating and encoding both semantic and temporal deformation features, each Gaussian is equipped with cues for potential deformation compensation within 3D space, facilitating a more precise representation of dynamic scenes. Experimental results show that our method improves 4DGS's ability to capture fine details in dynamic scene rendering for autonomous driving and outperforms other self-supervised methods in 4D reconstruction and novel view synthesis. Furthermore, CoDa-4DGS deforms semantic features with each Gaussian, enabling broader applications.
Collaborative Semantic Occupancy Prediction with Hybrid Feature Fusion in Connected Automated Vehicles
Feb 12, 2024Collaborative perception in automated vehicles leverages the exchange of information between agents, aiming to elevate perception results. Previous camera-based collaborative 3D perception methods typically employ 3D bounding boxes or bird's eye views as representations of the environment. However, these approaches fall short in offering a comprehensive 3D environmental prediction. To bridge this gap, we introduce the first method for collaborative 3D semantic occupancy prediction. Particularly, it improves local 3D semantic occupancy predictions by hybrid fusion of (i) semantic and occupancy task features, and (ii) compressed orthogonal attention features shared between vehicles. Additionally, due to the lack of a collaborative perception dataset designed for semantic occupancy prediction, we augment a current collaborative perception dataset to include 3D collaborative semantic occupancy labels for a more robust evaluation. The experimental findings highlight that: (i) our collaborative semantic occupancy predictions excel above the results from single vehicles by over 30%, and (ii) models anchored on semantic occupancy outpace state-of-the-art collaborative 3D detection techniques in subsequent perception applications, showcasing enhanced accuracy and enriched semantic-awareness in road environments.
V2X-Boosted Federated Learning for Cooperative Intelligent Transportation Systems with Contextual Client Selection
May 19, 2023Machine learning (ML) has revolutionized transportation systems, enabling autonomous driving and smart traffic services. Federated learning (FL) overcomes privacy constraints by training ML models in distributed systems, exchanging model parameters instead of raw data. However, the dynamic states of connected vehicles affect the network connection quality and influence the FL performance. To tackle this challenge, we propose a contextual client selection pipeline that uses Vehicle-to-Everything (V2X) messages to select clients based on the predicted communication latency. The pipeline includes: (i) fusing V2X messages, (ii) predicting future traffic topology, (iii) pre-clustering clients based on local data distribution similarity, and (iv) selecting clients with minimal latency for future model aggregation. Experiments show that our pipeline outperforms baselines on various datasets, particularly in non-iid settings.
FedBEVT: Federated Learning Bird's Eye View Perception Transformer in Road Traffic Systems
Apr 04, 2023



Bird's eye view (BEV) perception is becoming increasingly important in the field of autonomous driving. It uses multi-view camera data to learn a transformer model that directly projects the perception of the road environment onto the BEV perspective. However, training a transformer model often requires a large amount of data, and as camera data for road traffic is often private, it is typically not shared. Federated learning offers a solution that enables clients to collaborate and train models without exchanging data. In this paper, we propose FedBEVT, a federated transformer learning approach for BEV perception. We address two common data heterogeneity issues in FedBEVT: (i) diverse sensor poses and (ii) varying sensor numbers in perception systems. We present federated learning with camera-attentive personalization~(FedCaP) and adaptive multi-camera masking~(AMCM) to enhance the performance in real-world scenarios. To evaluate our method in real-world settings, we create a dataset consisting of four typical federated use cases. Our findings suggest that FedBEVT outperforms the baseline approaches in all four use cases, demonstrating the potential of our approach for improving BEV perception in autonomous driving. We will make all codes and data publicly available.
ResFed: Communication Efficient Federated Learning by Transmitting Deep Compressed Residuals
Dec 11, 2022Federated learning enables cooperative training among massively distributed clients by sharing their learned local model parameters. However, with increasing model size, deploying federated learning requires a large communication bandwidth, which limits its deployment in wireless networks. To address this bottleneck, we introduce a residual-based federated learning framework (ResFed), where residuals rather than model parameters are transmitted in communication networks for training. In particular, we integrate two pairs of shared predictors for the model prediction in both server-to-client and client-to-server communication. By employing a common prediction rule, both locally and globally updated models are always fully recoverable in clients and the server. We highlight that the residuals only indicate the quasi-update of a model in a single inter-round, and hence contain more dense information and have a lower entropy than the model, comparing to model weights and gradients. Based on this property, we further conduct lossy compression of the residuals by sparsification and quantization and encode them for efficient communication. The experimental evaluation shows that our ResFed needs remarkably less communication costs and achieves better accuracy by leveraging less sensitive residuals, compared to standard federated learning. For instance, to train a 4.08 MB CNN model on CIFAR-10 with 10 clients under non-independent and identically distributed (Non-IID) setting, our approach achieves a compression ratio over 700X in each communication round with minimum impact on the accuracy. To reach an accuracy of 70%, it saves around 99% of the total communication volume from 587.61 Mb to 6.79 Mb in up-streaming and to 4.61 Mb in down-streaming on average for all clients.
Federated Learning via Decentralized Dataset Distillation in Resource-Constrained Edge Environments
Aug 31, 2022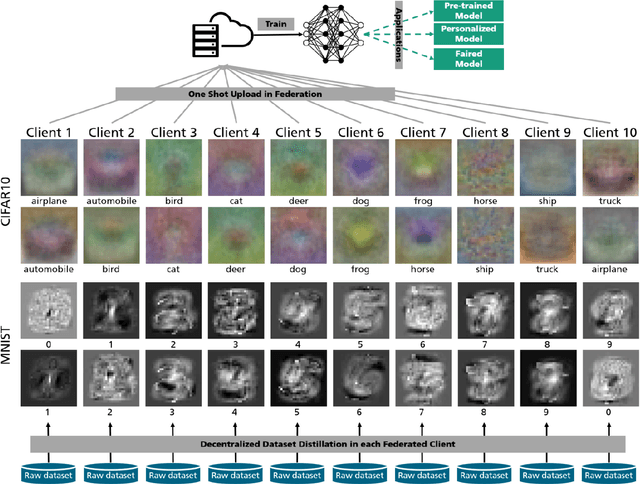
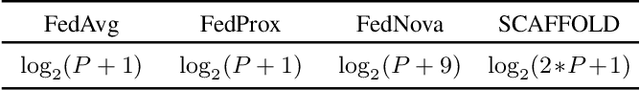
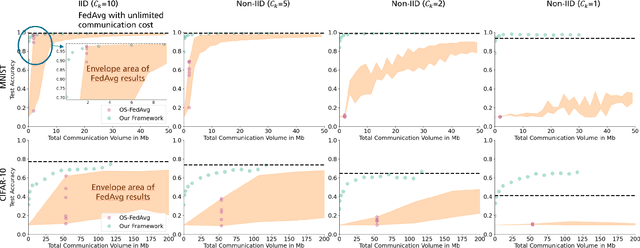
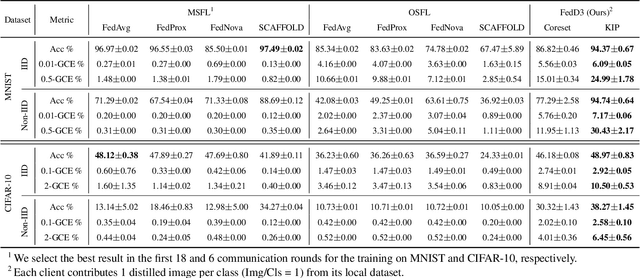
We introduce a novel federated learning framework, FedD3, which reduces the overall communication volume and with that opens up the concept of federated learning to more application scenarios in network-constrained environments. It achieves this by leveraging local dataset distillation instead of traditional learning approaches (i) to significantly reduce communication volumes and (ii) to limit transfers to one-shot communication, rather than iterative multiway communication. Instead of sharing model updates, as in other federated learning approaches, FedD3 allows the connected clients to distill the local datasets independently, and then aggregates those decentralized distilled datasets (typically in the form a few unrecognizable images, which are normally smaller than a model) across the network only once to form the final model. Our experimental results show that FedD3 significantly outperforms other federated learning frameworks in terms of needed communication volumes, while it provides the additional benefit to be able to balance the trade-off between accuracy and communication cost, depending on usage scenario or target dataset. For instance, for training an AlexNet model on a Non-IID CIFAR-10 dataset with 10 clients, FedD3 can either increase the accuracy by over 71% with a similar communication volume, or save 98% of communication volume, while reaching the same accuracy, comparing to other one-shot federated learning approaches.
Edge-Aided Sensor Data Sharing in Vehicular Communication Networks
Jun 17, 2022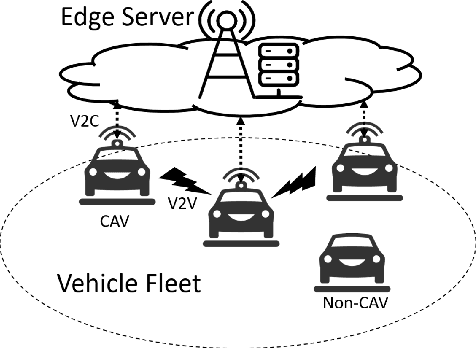
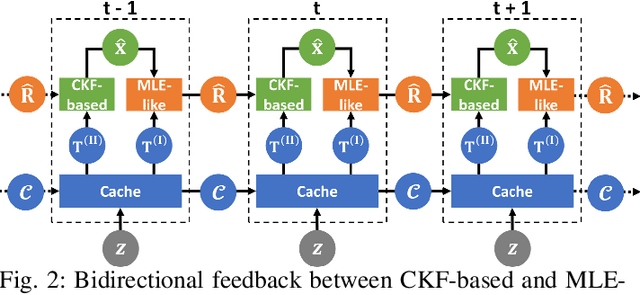
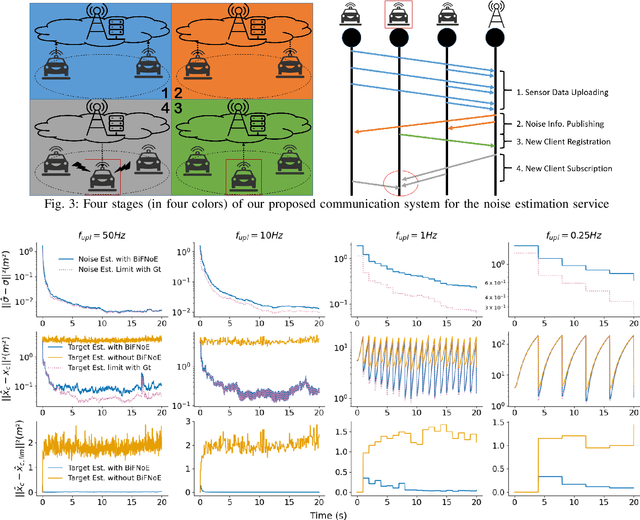
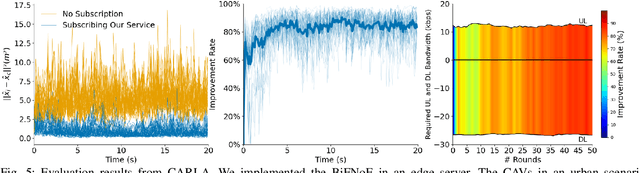
Sensor data sharing in vehicular networks can significantly improve the range and accuracy of environmental perception for connected automated vehicles. Different concepts and schemes for dissemination and fusion of sensor data have been developed. It is common to these schemes that measurement errors of the sensors impair the perception quality and can result in road traffic accidents. Specifically, when the measurement error from the sensors (also referred as measurement noise) is unknown and time varying, the performance of the data fusion process is restricted, which represents a major challenge in the calibration of sensors. In this paper, we consider sensor data sharing and fusion in a vehicular network with both, vehicle-to-infrastructure and vehicle-to-vehicle communication. We propose a method, named Bidirectional Feedback Noise Estimation (BiFNoE), in which an edge server collects and caches sensor measurement data from vehicles. The edge estimates the noise and the targets alternately in double dynamic sliding time windows and enhances the distributed cooperative environment sensing at each vehicle with low communication costs. We evaluate the proposed algorithm and data dissemination strategy in an application scenario by simulation and show that the perception accuracy is on average improved by around 80 % with only 12 kbps uplink and 28 kbps downlink bandwidth.
Federated Learning Framework Coping with Hierarchical Heterogeneity in Cooperative ITS
Apr 11, 2022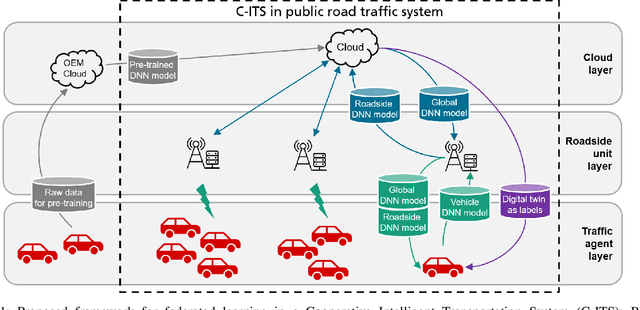
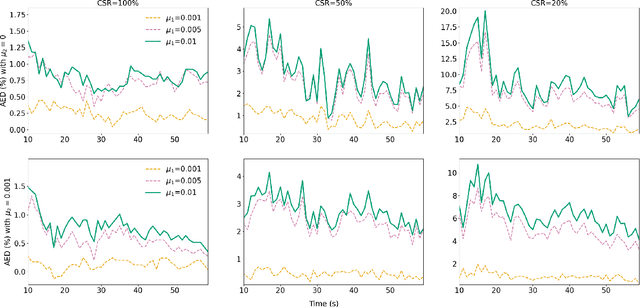
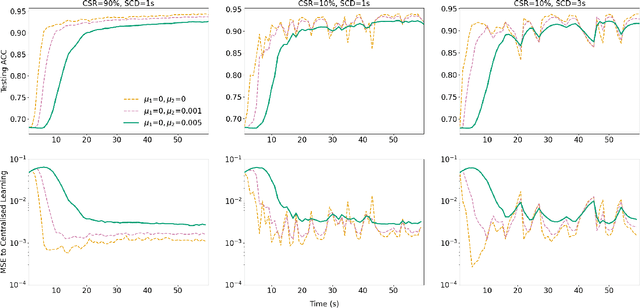
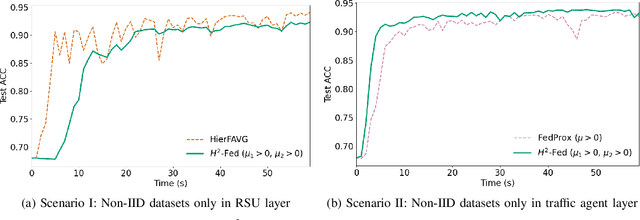
In this paper, we introduce a federated learning framework coping with Hierarchical Heterogeneity (H2-Fed), which can notably enhance the conventional pre-trained deep learning model. The framework exploits data from connected public traffic agents in vehicular networks without affecting user data privacy. By coordinating existing traffic infrastructure, including roadside units and road traffic clouds, the model parameters are efficiently disseminated by vehicular communications and hierarchically aggregated. Considering the individual heterogeneity of data distribution, computational and communication capabilities across traffic agents and roadside units, we employ a novel method that addresses the heterogeneity of different aggregation layers of the framework architecture, i.e., aggregation in layers of roadside units and cloud. The experiment results indicate that our method can well balance the learning accuracy and stability according to the knowledge of heterogeneity in current communication networks. Compared to other baseline approaches, the evaluation on a Non-IID MNIST dataset shows that our framework is more general and capable especially in application scenarios with low communication quality. Even when 90% of the agents are timely disconnected, the pre-trained deep learning model can still be forced to converge stably, and its accuracy can be enhanced from 68% to over 90% after convergence.