 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDD-Ranking: Rethinking the Evaluation of Dataset Distillation
May 19, 2025



In recent years, dataset distillation has provided a reliable solution for data compression, where models trained on the resulting smaller synthetic datasets achieve performance comparable to those trained on the original datasets. To further improve the performance of synthetic datasets, various training pipelines and optimization objectives have been proposed, greatly advancing the field of dataset distillation. Recent decoupled dataset distillation methods introduce soft labels and stronger data augmentation during the post-evaluation phase and scale dataset distillation up to larger datasets (e.g., ImageNet-1K). However, this raises a question: Is accuracy still a reliable metric to fairly evaluate dataset distillation methods? Our empirical findings suggest that the performance improvements of these methods often stem from additional techniques rather than the inherent quality of the images themselves, with even randomly sampled images achieving superior results. Such misaligned evaluation settings severely hinder the development of DD. Therefore, we propose DD-Ranking, a unified evaluation framework, along with new general evaluation metrics to uncover the true performance improvements achieved by different methods. By refocusing on the actual information enhancement of distilled datasets, DD-Ranking provides a more comprehensive and fair evaluation standard for future research advancements.
Dataset Distillation by Automatic Training Trajectories
Jul 19, 2024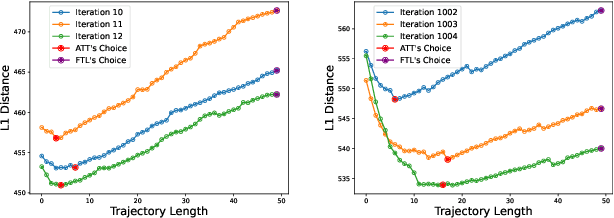
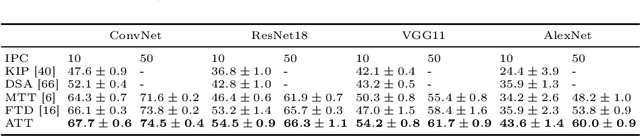
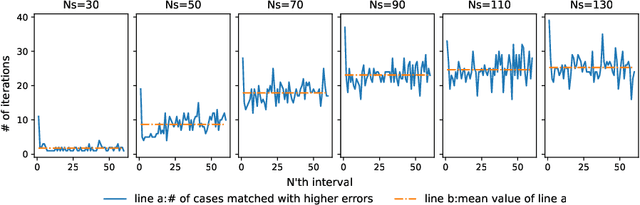
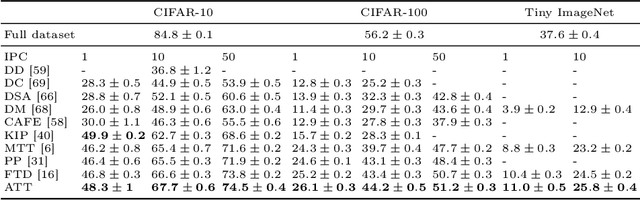
Dataset Distillation is used to create a concise, yet informative, synthetic dataset that can replace the original dataset for training purposes. Some leading methods in this domain prioritize long-range matching, involving the unrolling of training trajectories with a fixed number of steps (NS) on the synthetic dataset to align with various expert training trajectories. However, traditional long-range matching methods possess an overfitting-like problem, the fixed step size NS forces synthetic dataset to distortedly conform seen expert training trajectories, resulting in a loss of generality-especially to those from unencountered architecture. We refer to this as the Accumulated Mismatching Problem (AMP), and propose a new approach, Automatic Training Trajectories (ATT), which dynamically and adaptively adjusts trajectory length NS to address the AMP. Our method outperforms existing methods particularly in tests involving cross-architectures. Moreover, owing to its adaptive nature, it exhibits enhanced stability in the face of parameter variations.
Hierarchical Resource Partitioning on Modern GPUs: A Reinforcement Learning Approach
May 14, 2024GPU-based heterogeneous architectures are now commonly used in HPC clusters. Due to their architectural simplicity specialized for data-level parallelism, GPUs can offer much higher computational throughput and memory bandwidth than CPUs in the same generation do. However, as the available resources in GPUs have increased exponentially over the past decades, it has become increasingly difficult for a single program to fully utilize them. As a consequence, the industry has started supporting several resource partitioning features in order to improve the resource utilization by co-scheduling multiple programs on the same GPU die at the same time. Driven by the technological trend, this paper focuses on hierarchical resource partitioning on modern GPUs, and as an example, we utilize a combination of two different features available on recent NVIDIA GPUs in a hierarchical manner: MPS (Multi-Process Service), a finer-grained logical partitioning; and MIG (Multi-Instance GPU), a coarse-grained physical partitioning. We propose a method for comprehensively co-optimizing the setup of hierarchical partitioning and the selection of co-scheduling groups from a given set of jobs, based on reinforcement learning using their profiles. Our thorough experimental results demonstrate that our approach can successfully set up job concurrency, partitioning, and co-scheduling group selections simultaneously. This results in a maximum throughput improvement by a factor of 1.87 compared to the time-sharing scheduling.
Federated Learning via Decentralized Dataset Distillation in Resource-Constrained Edge Environments
Aug 31, 2022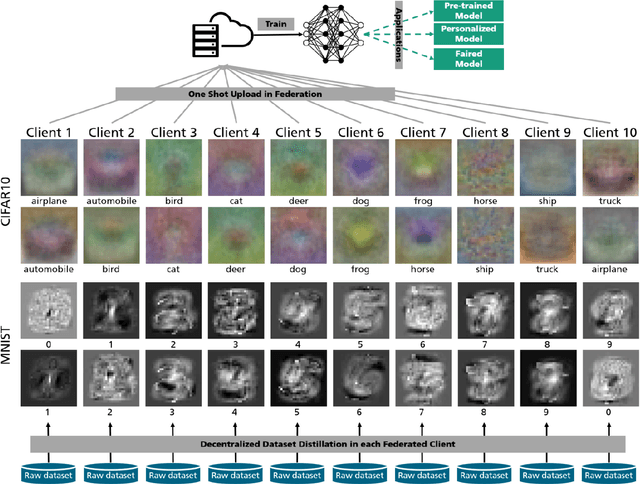
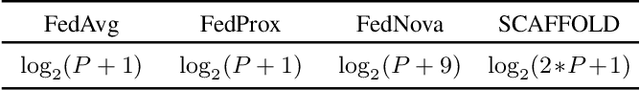
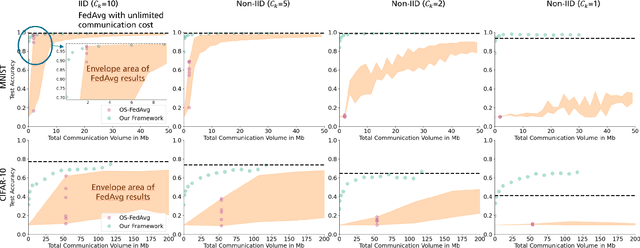
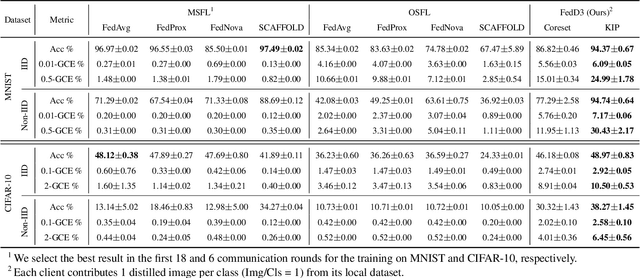
We introduce a novel federated learning framework, FedD3, which reduces the overall communication volume and with that opens up the concept of federated learning to more application scenarios in network-constrained environments. It achieves this by leveraging local dataset distillation instead of traditional learning approaches (i) to significantly reduce communication volumes and (ii) to limit transfers to one-shot communication, rather than iterative multiway communication. Instead of sharing model updates, as in other federated learning approaches, FedD3 allows the connected clients to distill the local datasets independently, and then aggregates those decentralized distilled datasets (typically in the form a few unrecognizable images, which are normally smaller than a model) across the network only once to form the final model. Our experimental results show that FedD3 significantly outperforms other federated learning frameworks in terms of needed communication volumes, while it provides the additional benefit to be able to balance the trade-off between accuracy and communication cost, depending on usage scenario or target dataset. For instance, for training an AlexNet model on a Non-IID CIFAR-10 dataset with 10 clients, FedD3 can either increase the accuracy by over 71% with a similar communication volume, or save 98% of communication volume, while reaching the same accuracy, comparing to other one-shot federated learning approaches.