 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Distillation by Automatic Training Trajectories
Jul 19, 2024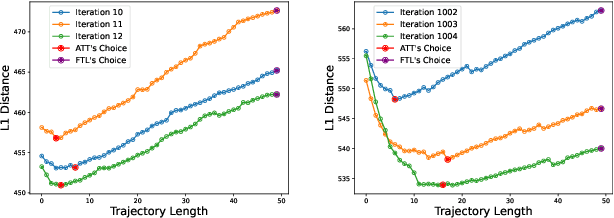
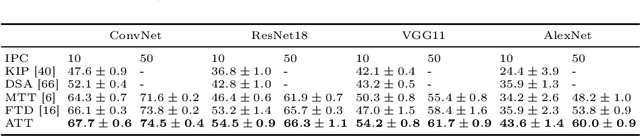
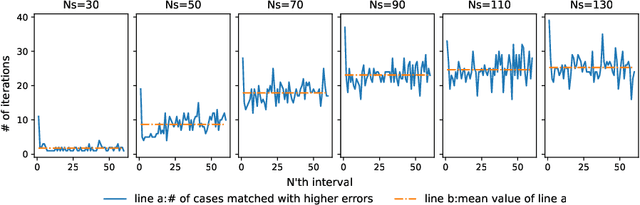
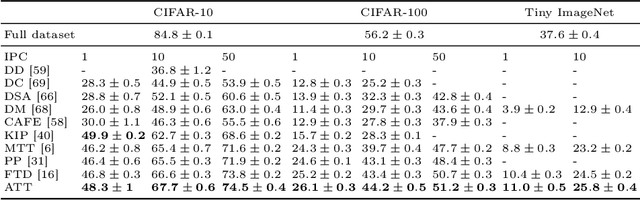
Dataset Distillation is used to create a concise, yet informative, synthetic dataset that can replace the original dataset for training purposes. Some leading methods in this domain prioritize long-range matching, involving the unrolling of training trajectories with a fixed number of steps (NS) on the synthetic dataset to align with various expert training trajectories. However, traditional long-range matching methods possess an overfitting-like problem, the fixed step size NS forces synthetic dataset to distortedly conform seen expert training trajectories, resulting in a loss of generality-especially to those from unencountered architecture. We refer to this as the Accumulated Mismatching Problem (AMP), and propose a new approach, Automatic Training Trajectories (ATT), which dynamically and adaptively adjusts trajectory length NS to address the AMP. Our method outperforms existing methods particularly in tests involving cross-architectures. Moreover, owing to its adaptive nature, it exhibits enhanced stability in the face of parameter variations.
Federated Learning via Decentralized Dataset Distillation in Resource-Constrained Edge Environments
Aug 31, 2022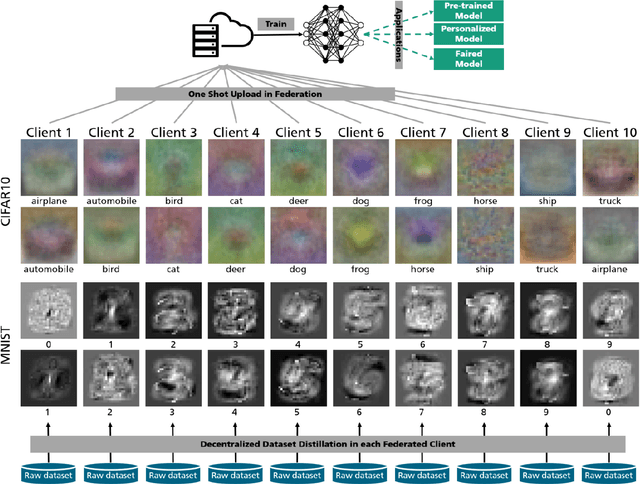
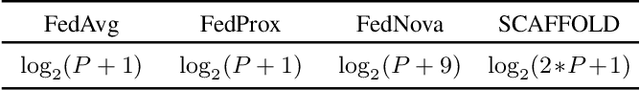
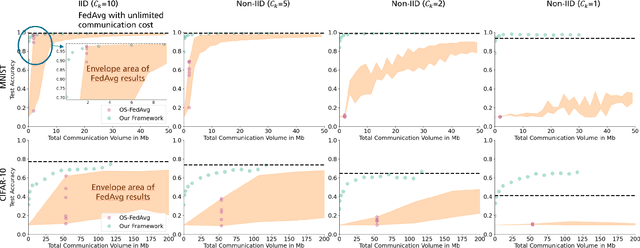
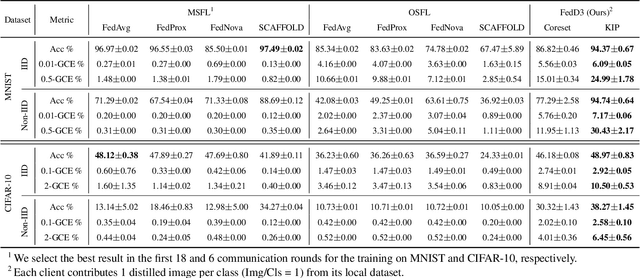
We introduce a novel federated learning framework, FedD3, which reduces the overall communication volume and with that opens up the concept of federated learning to more application scenarios in network-constrained environments. It achieves this by leveraging local dataset distillation instead of traditional learning approaches (i) to significantly reduce communication volumes and (ii) to limit transfers to one-shot communication, rather than iterative multiway communication. Instead of sharing model updates, as in other federated learning approaches, FedD3 allows the connected clients to distill the local datasets independently, and then aggregates those decentralized distilled datasets (typically in the form a few unrecognizable images, which are normally smaller than a model) across the network only once to form the final model. Our experimental results show that FedD3 significantly outperforms other federated learning frameworks in terms of needed communication volumes, while it provides the additional benefit to be able to balance the trade-off between accuracy and communication cost, depending on usage scenario or target dataset. For instance, for training an AlexNet model on a Non-IID CIFAR-10 dataset with 10 clients, FedD3 can either increase the accuracy by over 71% with a similar communication volume, or save 98% of communication volume, while reaching the same accuracy, comparing to other one-shot federated learning approaches.