 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoDa-4DGS: Dynamic Gaussian Splatting with Context and Deformation Awareness for Autonomous Driving
Mar 09, 2025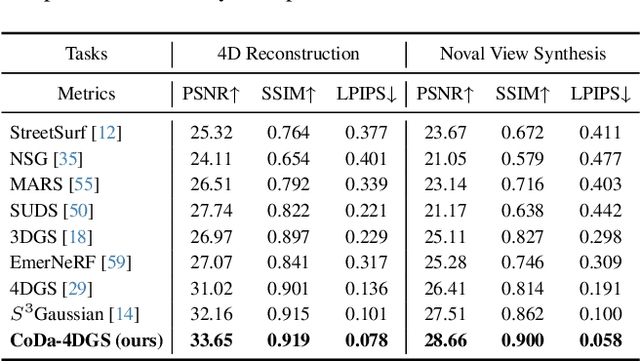
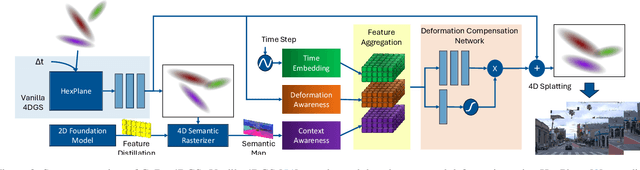
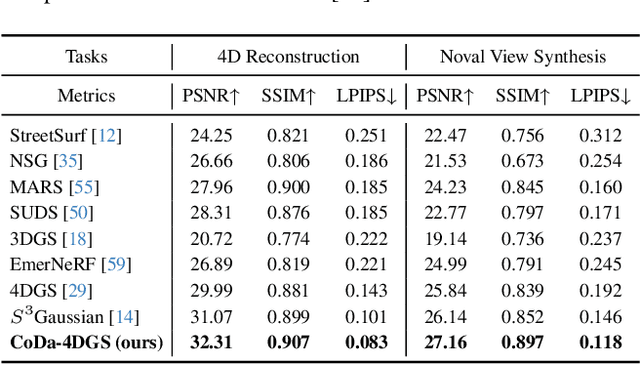

Dynamic scene rendering opens new avenues in autonomous driving by enabling closed-loop simulations with photorealistic data, which is crucial for validating end-to-end algorithms. However, the complex and highly dynamic nature of traffic environments presents significant challenges in accurately rendering these scenes. In this paper, we introduce a novel 4D Gaussian Splatting (4DGS) approach, which incorporates context and temporal deformation awareness to improve dynamic scene rendering. Specifically, we employ a 2D semantic segmentation foundation model to self-supervise the 4D semantic features of Gaussians, ensuring meaningful contextual embedding. Simultaneously, we track the temporal deformation of each Gaussian across adjacent frames. By aggregating and encoding both semantic and temporal deformation features, each Gaussian is equipped with cues for potential deformation compensation within 3D space, facilitating a more precise representation of dynamic scenes. Experimental results show that our method improves 4DGS's ability to capture fine details in dynamic scene rendering for autonomous driving and outperforms other self-supervised methods in 4D reconstruction and novel view synthesis. Furthermore, CoDa-4DGS deforms semantic features with each Gaussian, enabling broader applications.
Collaborative Semantic Occupancy Prediction with Hybrid Feature Fusion in Connected Automated Vehicles
Feb 12, 2024Collaborative perception in automated vehicles leverages the exchange of information between agents, aiming to elevate perception results. Previous camera-based collaborative 3D perception methods typically employ 3D bounding boxes or bird's eye views as representations of the environment. However, these approaches fall short in offering a comprehensive 3D environmental prediction. To bridge this gap, we introduce the first method for collaborative 3D semantic occupancy prediction. Particularly, it improves local 3D semantic occupancy predictions by hybrid fusion of (i) semantic and occupancy task features, and (ii) compressed orthogonal attention features shared between vehicles. Additionally, due to the lack of a collaborative perception dataset designed for semantic occupancy prediction, we augment a current collaborative perception dataset to include 3D collaborative semantic occupancy labels for a more robust evaluation. The experimental findings highlight that: (i) our collaborative semantic occupancy predictions excel above the results from single vehicles by over 30%, and (ii) models anchored on semantic occupancy outpace state-of-the-art collaborative 3D detection techniques in subsequent perception applications, showcasing enhanced accuracy and enriched semantic-awareness in road environments.