 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUNSET -- A Sensor-fUsioN based semantic SegmEnTation exemplar for ROS-based self-adaptation
Jan 20, 2026The fact that robots are getting deployed more often in dynamic environments, together with the increasing complexity of their software systems, raises the need for self-adaptive approaches. In these environments robotic software systems increasingly operate amid (1) uncertainties, where symptoms are easy to observe but root causes are ambiguous, or (2) multiple uncertainties appear concurrently. We present SUNSET, a ROS2-based exemplar that enables rigorous, repeatable evaluation of architecture-based self-adaptation in such conditions. It implements a sensor fusion semantic-segmentation pipeline driven by a trained Machine Learning (ML) model whose input preprocessing can be perturbed to induce realistic performance degradations. The exemplar exposes five observable symptoms, where each can be caused by different root causes and supports concurrent uncertainties spanning self-healing and self-optimisation. SUNSET includes the segmentation pipeline, a trained ML model, uncertainty-injection scripts, a baseline controller, and step-by-step integration and evaluation documentation to facilitate reproducible studies and fair comparison.
LGAR: Zero-Shot LLM-Guided Neural Ranking for Abstract Screening in Systematic Literature Reviews
May 30, 2025The scientific literature is growing rapidly, making it hard to keep track of the state-of-the-art. Systematic literature reviews (SLRs) aim to identify and evaluate all relevant papers on a topic. After retrieving a set of candidate papers, the abstract screening phase determines initial relevance. To date, abstract screening methods using large language models (LLMs) focus on binary classification settings; existing question answering (QA) based ranking approaches suffer from error propagation. LLMs offer a unique opportunity to evaluate the SLR's inclusion and exclusion criteria, yet, existing benchmarks do not provide them exhaustively. We manually extract these criteria as well as research questions for 57 SLRs, mostly in the medical domain, enabling principled comparisons between approaches. Moreover, we propose LGAR, a zero-shot LLM Guided Abstract Ranker composed of an LLM based graded relevance scorer and a dense re-ranker. Our extensive experiments show that LGAR outperforms existing QA-based methods by 5-10 pp. in mean average precision. Our code and data is publicly available.
Combining Quality of Service and System Health Metrics in MAPE-K based ROS Systems through Behavior Trees
Apr 29, 2025In recent years, the field of robotics has witnessed a significant shift from operating in structured environments to handling dynamic and unpredictable settings. To tackle these challenges, methodologies from the field of self-adaptive systems enabling these systems to react to unforeseen circumstances during runtime have been applied. The Monitoring-Analysis- Planning-Execution over Knowledge (MAPE-K) feedback loop model is a popular approach, often implemented in a managing subsystem, responsible for monitoring and adapting a managed subsystem. This work explores the implementation of the MAPE- K feedback loop based on Behavior Trees (BTs) within the Robot Operating System 2 (ROS2) framework. By delineating the managed and managing subsystems, our approach enhances the flexibility and adaptability of ROS-based systems, ensuring they not only meet Quality-of-Service (QoS), but also system health metric requirements, namely availability of ROS nodes and communication channels. Our implementation allows for the application of the method to new managed subsystems without needing custom BT nodes as the desired behavior can be configured within a specific rule set. We demonstrate the effectiveness of our method through various experiments on a system showcasing an aerial perception use case. By evaluating different failure cases, we show both an increased perception quality and a higher system availability. Our code is open source
Systematic Literature Review on Vehicular Collaborative Perception -- A Computer Vision Perspective
Apr 06, 2025The effectiveness of autonomous vehicles relies on reliable perception capabilities. Despite significant advancements in artificial intelligence and sensor fusion technologies, current single-vehicle perception systems continue to encounter limitations, notably visual occlusions and limited long-range detection capabilities. Collaborative Perception (CP), enabled by Vehicle-to-Vehicle (V2V) and Vehicle-to-Infrastructure (V2I) communication, has emerged as a promising solution to mitigate these issues and enhance the reliability of autonomous systems. Beyond advancements in communication, the computer vision community is increasingly focusing on improving vehicular perception through collaborative approaches. However, a systematic literature review that thoroughly examines existing work and reduces subjective bias is still lacking. Such a systematic approach helps identify research gaps, recognize common trends across studies, and inform future research directions. In response, this study follows the PRISMA 2020 guidelines and includes 106 peer-reviewed articles. These publications are analyzed based on modalities, collaboration schemes, and key perception tasks. Through a comparative analysis, this review illustrates how different methods address practical issues such as pose errors, temporal latency, communication constraints, domain shifts, heterogeneity, and adversarial attacks. Furthermore, it critically examines evaluation methodologies, highlighting a misalignment between current metrics and CP's fundamental objectives. By delving into all relevant topics in-depth, this review offers valuable insights into challenges, opportunities, and risks, serving as a reference for advancing research in vehicular collaborative perception.
R-LiViT: A LiDAR-Visual-Thermal Dataset Enabling Vulnerable Road User Focused Roadside Perception
Mar 21, 2025



In autonomous driving, the integration of roadside perception systems is essential for overcoming occlusion challenges and enhancing the safety of Vulnerable Road Users (VRUs). While LiDAR and visual (RGB) sensors are commonly used, thermal imaging remains underrepresented in datasets, despite its acknowledged advantages for VRU detection in extreme lighting conditions. In this paper, we present R-LiViT, the first dataset to combine LiDAR, RGB, and thermal imaging from a roadside perspective, with a strong focus on VRUs. R-LiViT captures three intersections during both day and night, ensuring a diverse dataset. It includes 10,000 LiDAR frames and 2,400 temporally and spatially aligned RGB and thermal images across over 150 traffic scenarios, with 6 and 8 annotated classes respectively, providing a comprehensive resource for tasks such as object detection and tracking. The dataset1 and the code for reproducing our evaluation results2 are made publicly available.
Semantic 3D scene segmentation for robotic assembly process execution
Mar 20, 2023
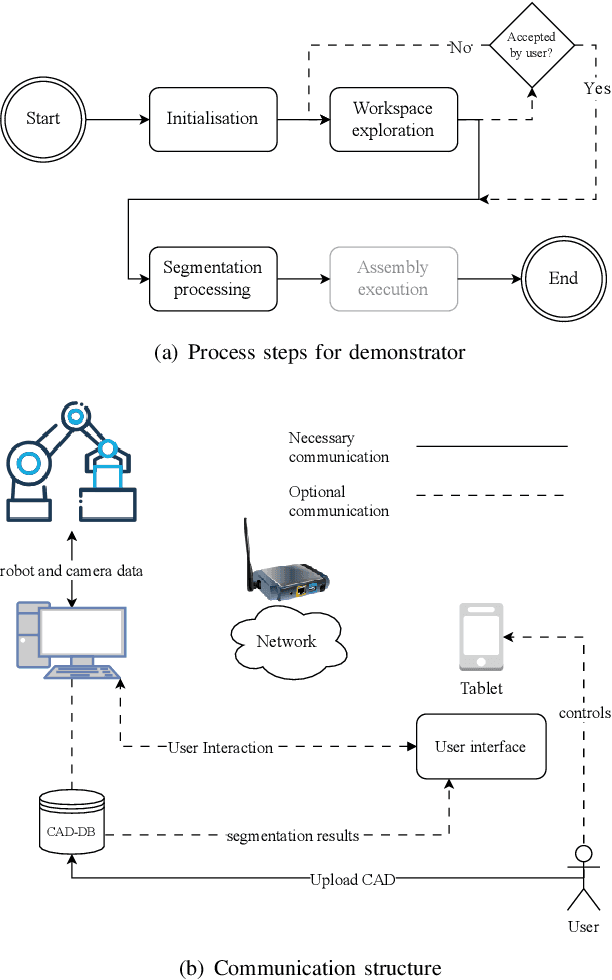


Adapting robot programmes to changes in the environment is a well-known industry problem, and it is the reason why many tedious tasks are not automated in small and medium-sized enterprises (SMEs). A semantic world model of a robot's previously unknown environment created from point clouds is one way for these companies to automate assembly tasks that are typically performed by humans. The semantic segmentation of point clouds for robot manipulators or cobots in industrial environments has received little attention due to a lack of suitable datasets. This paper describes a pipeline for creating synthetic point clouds for specific use cases in order to train a model for point cloud semantic segmentation. We show that models trained with our data achieve high per-class accuracy (> 90%) for semantic point cloud segmentation on unseen real-world data. Our approach is applicable not only to the 3D camera used in training data generation but also to other depth cameras based on different technologies. The application tested in this work is a industry-related peg-in-the-hole process. With our approach the necessity of user assistance during a robot's commissioning can be reduced to a minimum.