 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperimposed-Pilot OTFS Under Fractional Doppler: Modular End-to-End Learning
Jan 30, 2026Orthogonal time frequency space (OTFS) modulation has emerged as a promising candidate to overcome the performance degradation of orthogonal frequency division multiplexing (OFDM), which are commonly encountered in high-mobility wireless communication scenarios. However, conventional OTFS transceivers rely on multiple separately designed signal-processing modules, whose isolated optimization often limits global optimal performance. To overcome limitations, this paper proposes a modular deep learning (DL) based end-to-end OTFS transceiver framework that consists of trainable and interchangeable neural network (NN) modules, including constellation mapping/demapping, superimposed pilot placement, inverse Zak (IZak)/Zak transforms, and a U-Net-enhanced NN tailored for joint channel estimation and detection (JCED), while explicitly accounting for the impact of the cyclic prefix. This physics-informed modular architecture provides flexibility for integration with conventional OTFS systems and adaptability to different communication configurations. Simulations demonstrate that the proposed design significantly outperforms baseline methods in terms of both normalized mean squared error (NMSE) and detection reliability, maintaining robustness under integer and fractional Doppler conditions. The results highlight the potential of DL-based end-to-end optimization to enable practical and high-performance OTFS transceivers for next-generation high-mobility networks.
VALISENS: A Validated Innovative Multi-Sensor System for Cooperative Automated Driving
May 11, 2025Perception is a core capability of automated vehicles and has been significantly advanced through modern sensor technologies and artificial intelligence. However, perception systems still face challenges in complex real-world scenarios. To improve robustness against various external factors, multi-sensor fusion techniques are essential, combining the strengths of different sensor modalities. With recent developments in Vehicle-to-Everything (V2X communication, sensor fusion can now extend beyond a single vehicle to a cooperative multi-agent system involving Connected Automated Vehicle (CAV) and intelligent infrastructure. This paper presents VALISENS, an innovative multi-sensor system distributed across multiple agents. It integrates onboard and roadside LiDARs, radars, thermal cameras, and RGB cameras to enhance situational awareness and support cooperative automated driving. The thermal camera adds critical redundancy for perceiving Vulnerable Road User (VRU), while fusion with roadside sensors mitigates visual occlusions and extends the perception range beyond the limits of individual vehicles. We introduce the corresponding perception module built on this sensor system, which includes object detection, tracking, motion forecasting, and high-level data fusion. The proposed system demonstrates the potential of cooperative perception in real-world test environments and lays the groundwork for future Cooperative Intelligent Transport Systems (C-ITS) applications.
Systematic Literature Review on Vehicular Collaborative Perception -- A Computer Vision Perspective
Apr 06, 2025The effectiveness of autonomous vehicles relies on reliable perception capabilities. Despite significant advancements in artificial intelligence and sensor fusion technologies, current single-vehicle perception systems continue to encounter limitations, notably visual occlusions and limited long-range detection capabilities. Collaborative Perception (CP), enabled by Vehicle-to-Vehicle (V2V) and Vehicle-to-Infrastructure (V2I) communication, has emerged as a promising solution to mitigate these issues and enhance the reliability of autonomous systems. Beyond advancements in communication, the computer vision community is increasingly focusing on improving vehicular perception through collaborative approaches. However, a systematic literature review that thoroughly examines existing work and reduces subjective bias is still lacking. Such a systematic approach helps identify research gaps, recognize common trends across studies, and inform future research directions. In response, this study follows the PRISMA 2020 guidelines and includes 106 peer-reviewed articles. These publications are analyzed based on modalities, collaboration schemes, and key perception tasks. Through a comparative analysis, this review illustrates how different methods address practical issues such as pose errors, temporal latency, communication constraints, domain shifts, heterogeneity, and adversarial attacks. Furthermore, it critically examines evaluation methodologies, highlighting a misalignment between current metrics and CP's fundamental objectives. By delving into all relevant topics in-depth, this review offers valuable insights into challenges, opportunities, and risks, serving as a reference for advancing research in vehicular collaborative perception.
R-LiViT: A LiDAR-Visual-Thermal Dataset Enabling Vulnerable Road User Focused Roadside Perception
Mar 21, 2025



In autonomous driving, the integration of roadside perception systems is essential for overcoming occlusion challenges and enhancing the safety of Vulnerable Road Users (VRUs). While LiDAR and visual (RGB) sensors are commonly used, thermal imaging remains underrepresented in datasets, despite its acknowledged advantages for VRU detection in extreme lighting conditions. In this paper, we present R-LiViT, the first dataset to combine LiDAR, RGB, and thermal imaging from a roadside perspective, with a strong focus on VRUs. R-LiViT captures three intersections during both day and night, ensuring a diverse dataset. It includes 10,000 LiDAR frames and 2,400 temporally and spatially aligned RGB and thermal images across over 150 traffic scenarios, with 6 and 8 annotated classes respectively, providing a comprehensive resource for tasks such as object detection and tracking. The dataset1 and the code for reproducing our evaluation results2 are made publicly available.
The Components of Collaborative Joint Perception and Prediction -- A Conceptual Framework
Jan 27, 2025



Connected Autonomous Vehicles (CAVs) benefit from Vehicle-to-Everything (V2X) communication, which enables the exchange of sensor data to achieve Collaborative Perception (CP). To reduce cumulative errors in perception modules and mitigate the visual occlusion, this paper introduces a new task, Collaborative Joint Perception and Prediction (Co-P&P), and provides a conceptual framework for its implementation to improve motion prediction of surrounding objects, thereby enhancing vehicle awareness in complex traffic scenarios. The framework consists of two decoupled core modules, Collaborative Scene Completion (CSC) and Joint Perception and Prediction (P&P) module, which simplify practical deployment and enhance scalability. Additionally, we outline the challenges in Co-P&P and discuss future directions for this research area.
Weaver: Foundation Models for Creative Writing
Jan 30, 2024

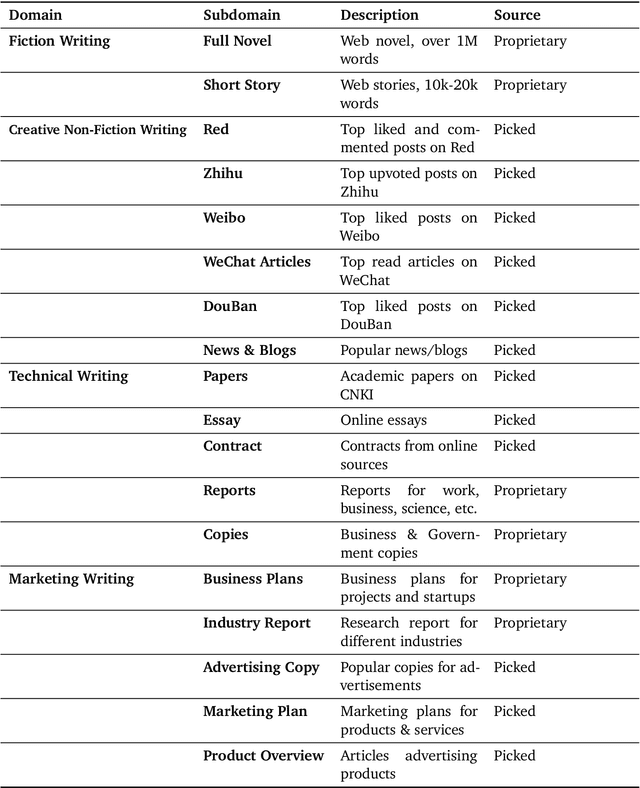

This work introduces Weaver, our first family of large language models (LLMs) dedicated to content creation. Weaver is pre-trained on a carefully selected corpus that focuses on improving the writing capabilities of large language models. We then fine-tune Weaver for creative and professional writing purposes and align it to the preference of professional writers using a suit of novel methods for instruction data synthesis and LLM alignment, making it able to produce more human-like texts and follow more diverse instructions for content creation. The Weaver family consists of models of Weaver Mini (1.8B), Weaver Base (6B), Weaver Pro (14B), and Weaver Ultra (34B) sizes, suitable for different applications and can be dynamically dispatched by a routing agent according to query complexity to balance response quality and computation cost. Evaluation on a carefully curated benchmark for assessing the writing capabilities of LLMs shows Weaver models of all sizes outperform generalist LLMs several times larger than them. Notably, our most-capable Weaver Ultra model surpasses GPT-4, a state-of-the-art generalist LLM, on various writing scenarios, demonstrating the advantage of training specialized LLMs for writing purposes. Moreover, Weaver natively supports retrieval-augmented generation (RAG) and function calling (tool usage). We present various use cases of these abilities for improving AI-assisted writing systems, including integration of external knowledge bases, tools, or APIs, and providing personalized writing assistance. Furthermore, we discuss and summarize a guideline and best practices for pre-training and fine-tuning domain-specific LLMs.
Implementation of a Binary Neural Network on a Passive Array of Magnetic Tunnel Junctions
Dec 16, 2021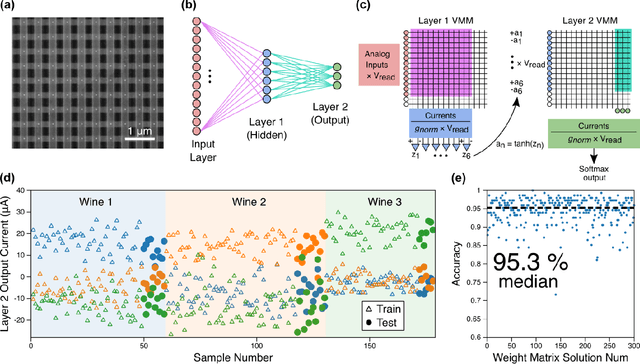

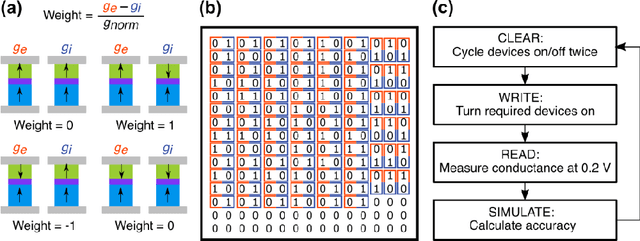
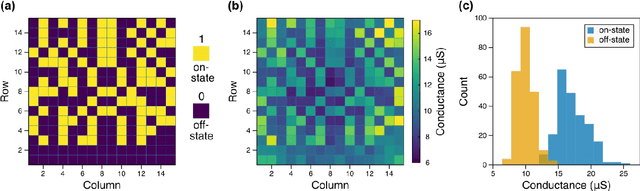
The increasing scale of neural networks and their growing application space have produced demand for more energy- and memory-efficient artificial-intelligence-specific hardware. Avenues to mitigate the main issue, the von Neumann bottleneck, include in-memory and near-memory architectures, as well as algorithmic approaches. Here we leverage the low-power and the inherently binary operation of magnetic tunnel junctions (MTJs) to demonstrate neural network hardware inference based on passive arrays of MTJs. In general, transferring a trained network model to hardware for inference is confronted by degradation in performance due to device-to-device variations, write errors, parasitic resistance, and nonidealities in the substrate. To quantify the effect of these hardware realities, we benchmark 300 unique weight matrix solutions of a 2-layer perceptron to classify the Wine dataset for both classification accuracy and write fidelity. Despite device imperfections, we achieve software-equivalent accuracy of up to 95.3 % with proper tuning of network parameters in 15 x 15 MTJ arrays having a range of device sizes. The success of this tuning process shows that new metrics are needed to characterize the performance and quality of networks reproduced in mixed signal hardware.
Joint CFO, Gridless Channel Estimation and Data Detection for Underwater Acoustic OFDM Systems
Jul 15, 2021


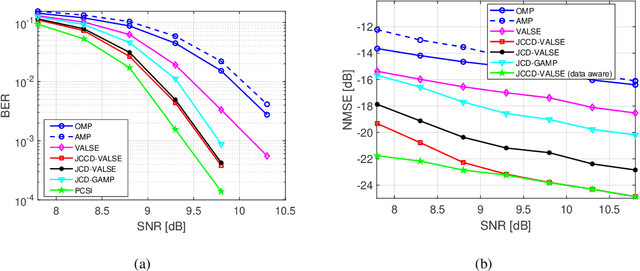
In this paper, we propose an iterative receiver based on gridless variational Bayesian line spectra estimation (VALSE) named JCCD-VALSE that \emph{j}ointly estimates the \emph{c}arrier frequency offset (CFO), the \emph{c}hannel with high resolution and carries out \emph{d}ata decoding. Based on a modularized point of view and motivated by the high resolution and low complexity gridless VALSE algorithm, three modules named the VALSE module, the minimum mean squared error (MMSE) module and the decoder module are built. Soft information is exchanged between the modules to progressively improve the channel estimation and data decoding accuracy. Since the delays of multipaths of the channel are treated as continuous parameters, instead of on a grid, the leakage effect is avoided. Besides, the proposed approach is a more complete Bayesian approach as all the nuisance parameters such as the noise variance, the parameters of the prior distribution of the channel, the number of paths are automatically estimated. Numerical simulations and sea test data are utilized to demonstrate that the proposed approach performs significantly better than the existing grid-based generalized approximate message passing (GAMP) based \emph{j}oint \emph{c}hannel and \emph{d}ata decoding approach (JCD-GAMP). Furthermore, it is also verified that joint processing including CFO estimation provides performance gain.