 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
AdaptThink: Reasoning Models Can Learn When to Think
May 19, 2025Recently, large reasoning models have achieved impressive performance on various tasks by employing human-like deep thinking. However, the lengthy thinking process substantially increases inference overhead, making efficiency a critical bottleneck. In this work, we first demonstrate that NoThinking, which prompts the reasoning model to skip thinking and directly generate the final solution, is a better choice for relatively simple tasks in terms of both performance and efficiency. Motivated by this, we propose AdaptThink, a novel RL algorithm to teach reasoning models to choose the optimal thinking mode adaptively based on problem difficulty. Specifically, AdaptThink features two core components: (1) a constrained optimization objective that encourages the model to choose NoThinking while maintaining the overall performance; (2) an importance sampling strategy that balances Thinking and NoThinking samples during on-policy training, thereby enabling cold start and allowing the model to explore and exploit both thinking modes throughout the training process. Our experiments indicate that AdaptThink significantly reduces the inference costs while further enhancing performance. Notably, on three math datasets, AdaptThink reduces the average response length of DeepSeek-R1-Distill-Qwen-1.5B by 53% and improves its accuracy by 2.4%, highlighting the promise of adaptive thinking-mode selection for optimizing the balance between reasoning quality and efficiency. Our codes and models are available at https://github.com/THU-KEG/AdaptThink.
From MOOC to MAIC: Reshaping Online Teaching and Learning through LLM-driven Agents
Sep 05, 2024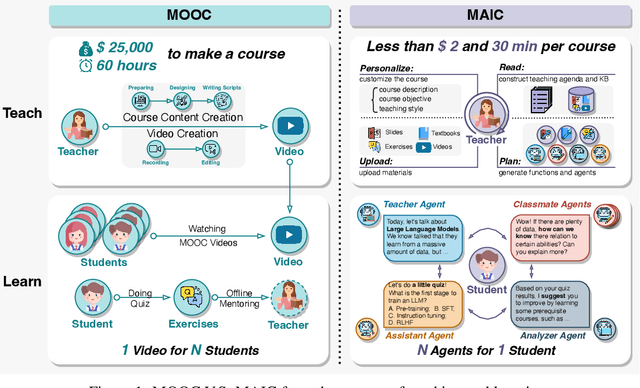
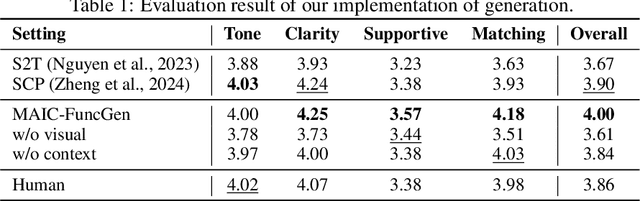
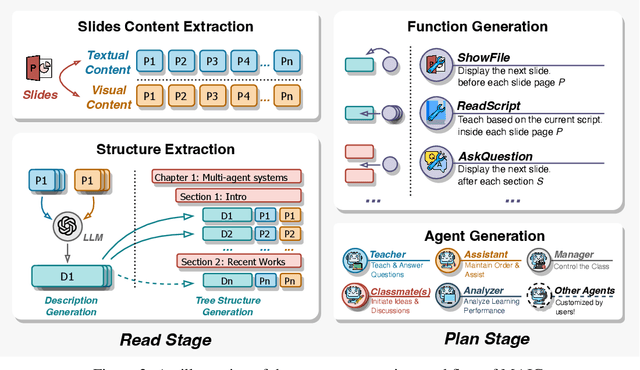

Since the first instances of online education, where courses were uploaded to accessible and shared online platforms, this form of scaling the dissemination of human knowledge to reach a broader audience has sparked extensive discussion and widespread adoption. Recognizing that personalized learning still holds significant potential for improvement, new AI technologies have been continuously integrated into this learning format, resulting in a variety of educational AI applications such as educational recommendation and intelligent tutoring. The emergence of intelligence in large language models (LLMs) has allowed for these educational enhancements to be built upon a unified foundational model, enabling deeper integration. In this context, we propose MAIC (Massive AI-empowered Course), a new form of online education that leverages LLM-driven multi-agent systems to construct an AI-augmented classroom, balancing scalability with adaptivity. Beyond exploring the conceptual framework and technical innovations, we conduct preliminary experiments at Tsinghua University, one of China's leading universities. Drawing from over 100,000 learning records of more than 500 students, we obtain a series of valuable observations and initial analyses. This project will continue to evolve, ultimately aiming to establish a comprehensive open platform that supports and unifies research, technology, and applications in exploring the possibilities of online education in the era of large model AI. We envision this platform as a collaborative hub, bringing together educators, researchers, and innovators to collectively explore the future of AI-driven online education.
Advancing Geometric Problem Solving: A Comprehensive Benchmark for Multimodal Model Evaluation
Apr 07, 2024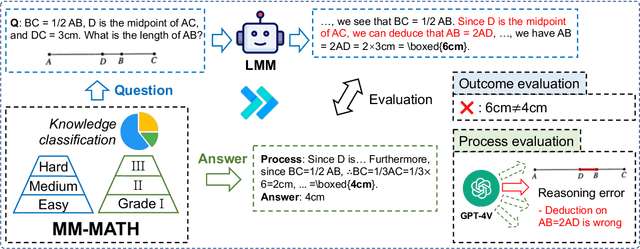

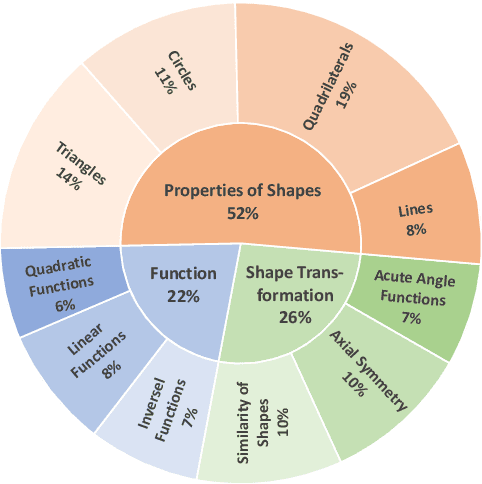
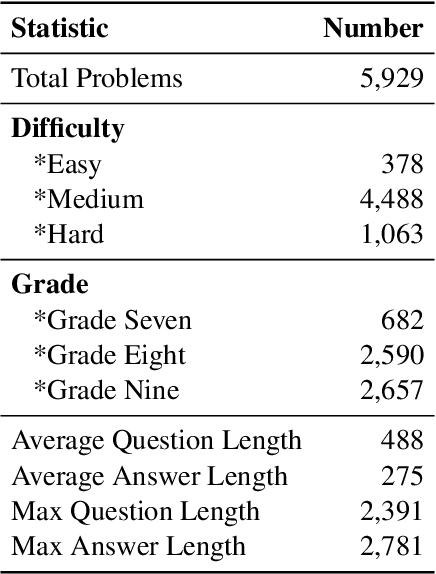
In this work, we present the MM-MATH dataset, a novel benchmark developed to rigorously evaluate the performance of advanced large language and multimodal models - including but not limited to GPT-4, GPT-4V, and Claude - within the domain of geometric computation. This dataset comprises 5,929 meticulously crafted geometric problems, each paired with a corresponding image, aimed at mirroring the complexity and requirements typical of ninth-grade mathematics. The motivation behind MM-MATH stems from the burgeoning interest and significant strides in multimodal technology, which necessitates a paradigm shift in assessment methodologies from mere outcome analysis to a more holistic evaluation encompassing reasoning and procedural correctness. Despite impressive gains in various benchmark performances, our analysis uncovers a persistent and notable deficiency in these models' ability to parse and interpret geometric information accurately from images, accounting for over 60% of observed errors. By deploying a dual-focused evaluation approach, examining both the end results and the underlying problem-solving processes, we unearthed a marked discrepancy between the capabilities of current multimodal models and human-level proficiency. The introduction of MM-MATH represents a tripartite contribution to the field: it not only serves as a comprehensive and challenging benchmark for assessing geometric problem-solving prowess but also illuminates critical gaps in textual and visual comprehension that current models exhibit. Through this endeavor, we aspire to catalyze further research and development aimed at bridging these gaps, thereby advancing the state of multimodal model capabilities to new heights.
Reverse That Number! Decoding Order Matters in Arithmetic Learning
Mar 09, 2024



Recent advancements in pretraining have demonstrated that modern Large Language Models (LLMs) possess the capability to effectively learn arithmetic operations. However, despite acknowledging the significance of digit order in arithmetic computation, current methodologies predominantly rely on sequential, step-by-step approaches for teaching LLMs arithmetic, resulting in a conclusion where obtaining better performance involves fine-grained step-by-step. Diverging from this conventional path, our work introduces a novel strategy that not only reevaluates the digit order by prioritizing output from the least significant digit but also incorporates a step-by-step methodology to substantially reduce complexity. We have developed and applied this method in a comprehensive set of experiments. Compared to the previous state-of-the-art (SOTA) method, our findings reveal an overall improvement of in accuracy while requiring only a third of the tokens typically used during training. For the purpose of facilitating replication and further research, we have made our code and dataset publicly available at \url{https://anonymous.4open.science/r/RAIT-9FB7/}.
KoLA: Carefully Benchmarking World Knowledge of Large Language Models
Jun 15, 2023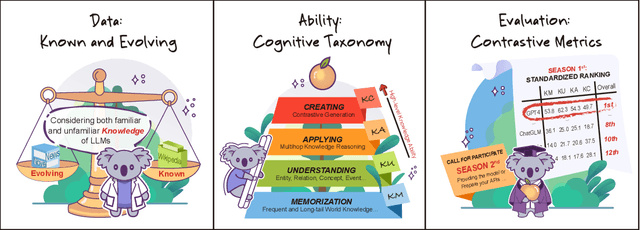
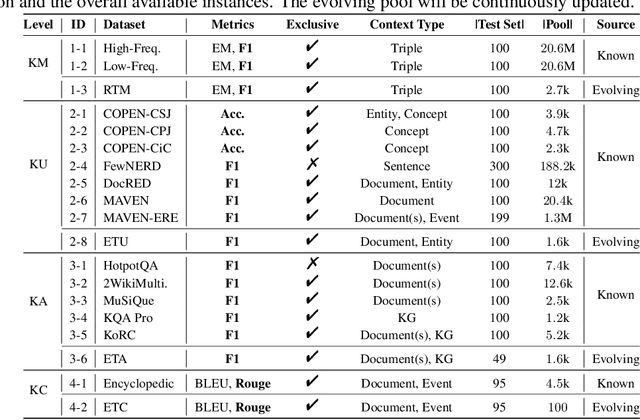
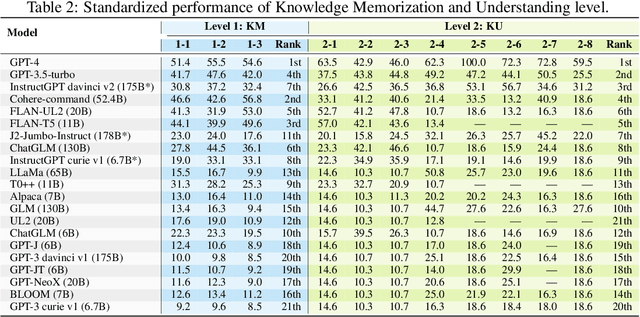

The unprecedented performance of large language models (LLMs) necessitates improvements in evaluations. Rather than merely exploring the breadth of LLM abilities, we believe meticulous and thoughtful designs are essential to thorough, unbiased, and applicable evaluations. Given the importance of world knowledge to LLMs, we construct a Knowledge-oriented LLM Assessment benchmark (KoLA), in which we carefully design three crucial factors: (1) For ability modeling, we mimic human cognition to form a four-level taxonomy of knowledge-related abilities, covering $19$ tasks. (2) For data, to ensure fair comparisons, we use both Wikipedia, a corpus prevalently pre-trained by LLMs, along with continuously collected emerging corpora, aiming to evaluate the capacity to handle unseen data and evolving knowledge. (3) For evaluation criteria, we adopt a contrastive system, including overall standard scores for better numerical comparability across tasks and models and a unique self-contrast metric for automatically evaluating knowledge hallucination. We evaluate $21$ open-source and commercial LLMs and obtain some intriguing findings. The KoLA dataset and open-participation leaderboard are publicly released at https://kola.xlore.cn and will be continuously updated to provide references for developing LLMs and knowledge-related systems.
GLM-Dialog: Noise-tolerant Pre-training for Knowledge-grounded Dialogue Generation
Feb 28, 2023
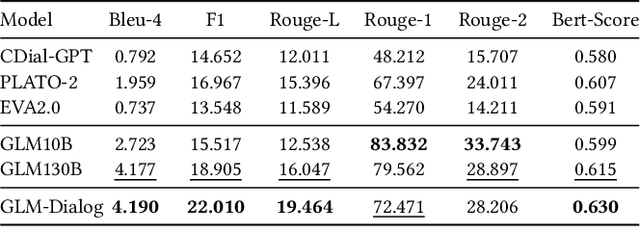

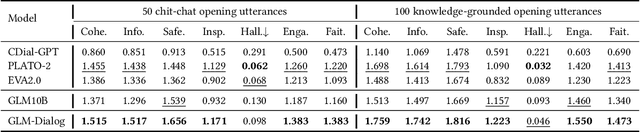
We present GLM-Dialog, a large-scale language model (LLM) with 10B parameters capable of knowledge-grounded conversation in Chinese using a search engine to access the Internet knowledge. GLM-Dialog offers a series of applicable techniques for exploiting various external knowledge including both helpful and noisy knowledge, enabling the creation of robust knowledge-grounded dialogue LLMs with limited proper datasets. To evaluate the GLM-Dialog more fairly, we also propose a novel evaluation method to allow humans to converse with multiple deployed bots simultaneously and compare their performance implicitly instead of explicitly rating using multidimensional metrics.Comprehensive evaluations from automatic to human perspective demonstrate the advantages of GLM-Dialog comparing with existing open source Chinese dialogue models. We release both the model checkpoint and source code, and also deploy it as a WeChat application to interact with users. We offer our evaluation platform online in an effort to prompt the development of open source models and reliable dialogue evaluation systems. The additional easy-to-use toolkit that consists of short text entity linking, query generation, and helpful knowledge classification is also released to enable diverse applications. All the source code is available on Github.